這是一篇當初我在入門資料工程以及 Airflow 時希望有人能為我寫好的文章。
Airflow 是一個從 Airbnb 誕生並開源,以 Python 寫成的工作流程管理系統(Workflow Management System),也是各大企業的資料工程環節中不可或缺的利器之一。
近年不管是資料科學家、資料工程師還是任何需要處理數據的軟體工程師,Airflow 都是他們用來建構可靠的 ETL 以及定期處理批量資料的首選之一。(事實上在 SmartNews,除了 DS/DE,會使用 Airflow 的軟體工程師也不在少數)
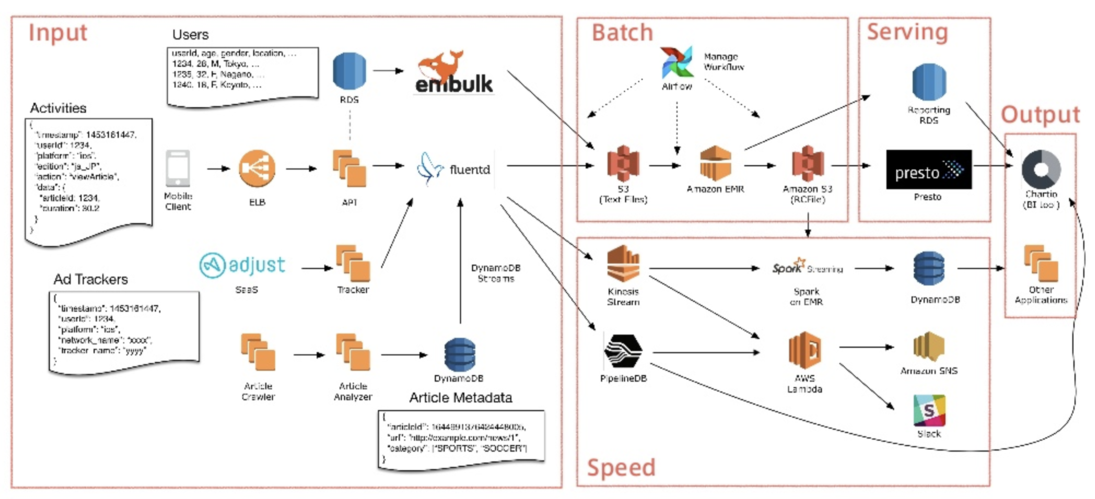
儘管它的方便以及強大,在完全熟悉 Airflow 之前,因為有些專業術語以及資料工程概念的存在,不少初學者(包含當時的我)在剛開始的時候容易四處撞壁。另外如果一開始就以 ETL 當作 Airflow 的入門的話,未免難度過高且缺少共鳴。
追連載:一個 Airflow 的輕鬆使用案例¶
這篇文章希望以一個簡易的漫畫連載通知 App 作為引子,讓完全沒有資料工程經驗的讀者也能夠透過這個 App 的例子,輕鬆地理解工作流程的概念、自動化排程以及 Airflow 的使用方式。閱讀完本文,你將對 Airflow 以及自動排程工作有更深的理解,並學會如何建立多個能在 Airflow 上穩定運行的工作流程。更重要的,我相信你能利用這些學到的基礎,開始自動化自己生活中以及企業的數據處理 pipeline。
如果你對資料工程有興趣,不太熟悉如 Airflow 這種工作流程管理系統,但有基本的 Python 程式基礎的話(或是純粹對用 Python 寫一個漫畫連載通知 App 有興趣),我相信這篇文章應該會很適合你。
想重新複習 ETL 概念的讀者可以參考先前的文章:資料科學家為何需要了解資料工程。
章節傳送門¶
為讓讀者完整了解開發這個 App 的背景脈絡、此 App 的執行邏輯以及使用 Airflow 來定期執行 App 的原因,在我們實際開始寫 Python 之前有兩小節的解說。
如果你已經有 Airflow 及工作流程的基礎知識,且迫不及待想看 Python 程式碼,可以直接跳到 Python 實作 & Airflow 操作章節之後再回來查看前面段落。

所以為何要這 App ?¶
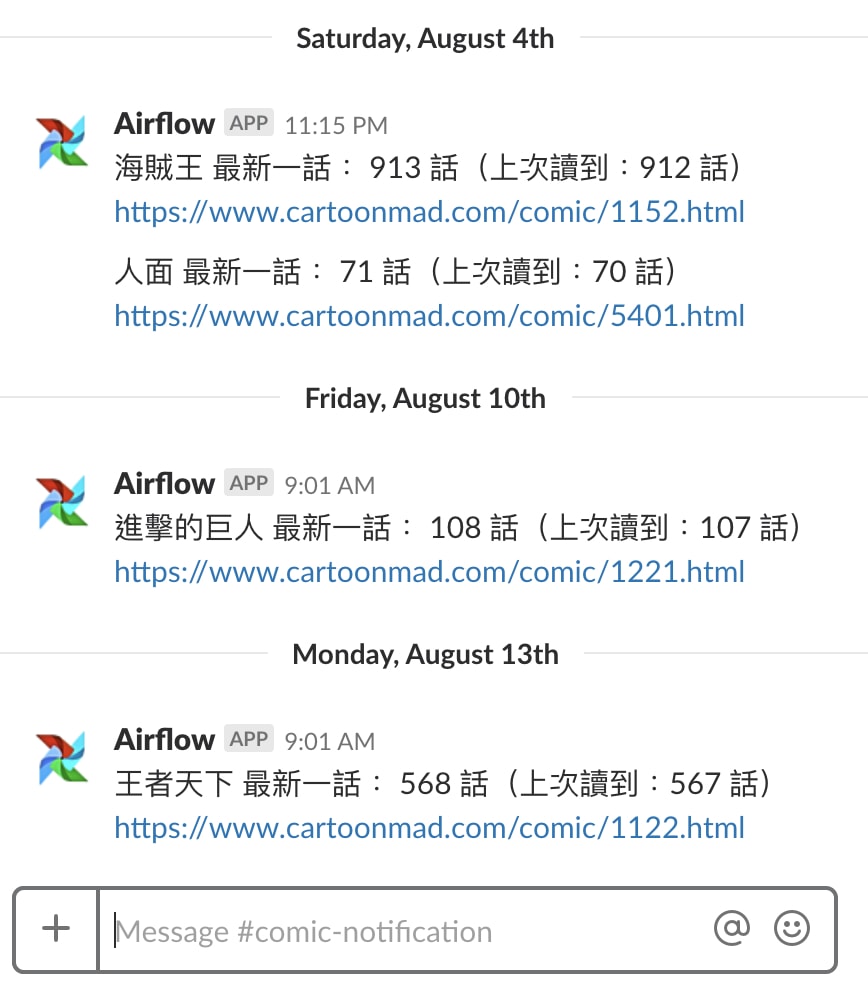
平常有在網路上追漫畫連載的讀者們應該都了解,市面上的漫畫網站通常都不是會員制的。更不用說「在新連載出的時候自動通知您!」這種推送功能(Push Notification)了。也因為這樣,導致我常常三不五時上去這些漫畫網站,看每個關注的漫畫到底出了最新一話了沒。可想而知,答案通常是否定的。(一週出一次每天檢查也沒用啊啊啊)
如果你只看海賊王一個漫畫(索隆好帥!),這或許沒什麼負擔。但就像上面 Slack 截圖顯示的,我不只關注海賊王,還看很多其他漫畫。讓事情更糟的是,到最後你會發現:
- 不記得自己到底在追哪些漫畫
- 每一部漫畫最後到底是看到第幾話
- 上一話是什麼時候出的
- 有幾話是新出而你還沒看的

追漫畫連載應該要是個輕鬆且享受的事情。在一個人人會寫 code 的時代,何不自己做個 App 幫我們自動檢查新連載呢?
工作流概念 & Airflow¶
概念上我們可以把此 App 需要做的工作按照「先後順序」由上往下列出來:
- 取得使用者的閱讀紀錄
- 去漫畫網站看有沒有新的章節
- 跟紀錄比較,有沒有新連載?
- 沒有:
- 什麼都不幹,結束
- 有:
- 寄 Slack 通知
- 更新閱讀紀錄
- 沒有:
想像上述的工作清單由上往下流動,就形成了一個工作流程(Workflow):前一個工作如寄 Slack 通知就是下一個工作:更新閱讀紀錄的上游工作(Upstream Task)。
反過來說,更新閱讀紀錄則是寄 Slack 通知的下游工作(Downstream Task)。
定義出工作之間的上下游關係的好處是什麼?
可以讓我們確保工作之間的相依性(Dependencies)並讓如 Airflow 這種工作流程管理系統幫我們管理工作流程。一般而言,下游工作只能在上游「成功」完成之後被執行;如果上游工作失敗的話,下游工作應該被終止,通常也沒有繼續執行的意義(例:如果 App 在執行上游工作「取得使用者閱讀紀錄」時就失敗的話,不需要也不應該執行下游的「更新閱讀紀錄」工作)。

我知道你在想什麼。
屏除剛剛介紹的工作流程概念,要實作這 App 的邏輯一點都不難。事實上我們只需要寫個 Python script,把每個工作各別用一個函式(Function)實作後再按照順序呼叫它們就好(你甚至可以只用一個函式實現所有邏輯!),為何需要 Airflow?
在你往下滑前給個提示:我們這個 App 不是每一秒鐘都在執行。

Airflow 非常適合用來管理相依性複雜,且具批次處理性質的工作流程。
小提醒:暗色模式為方便讀者閱讀,會用與真實 AirFlow UI 不同的顏色來呈現,但概念是一模一樣的。
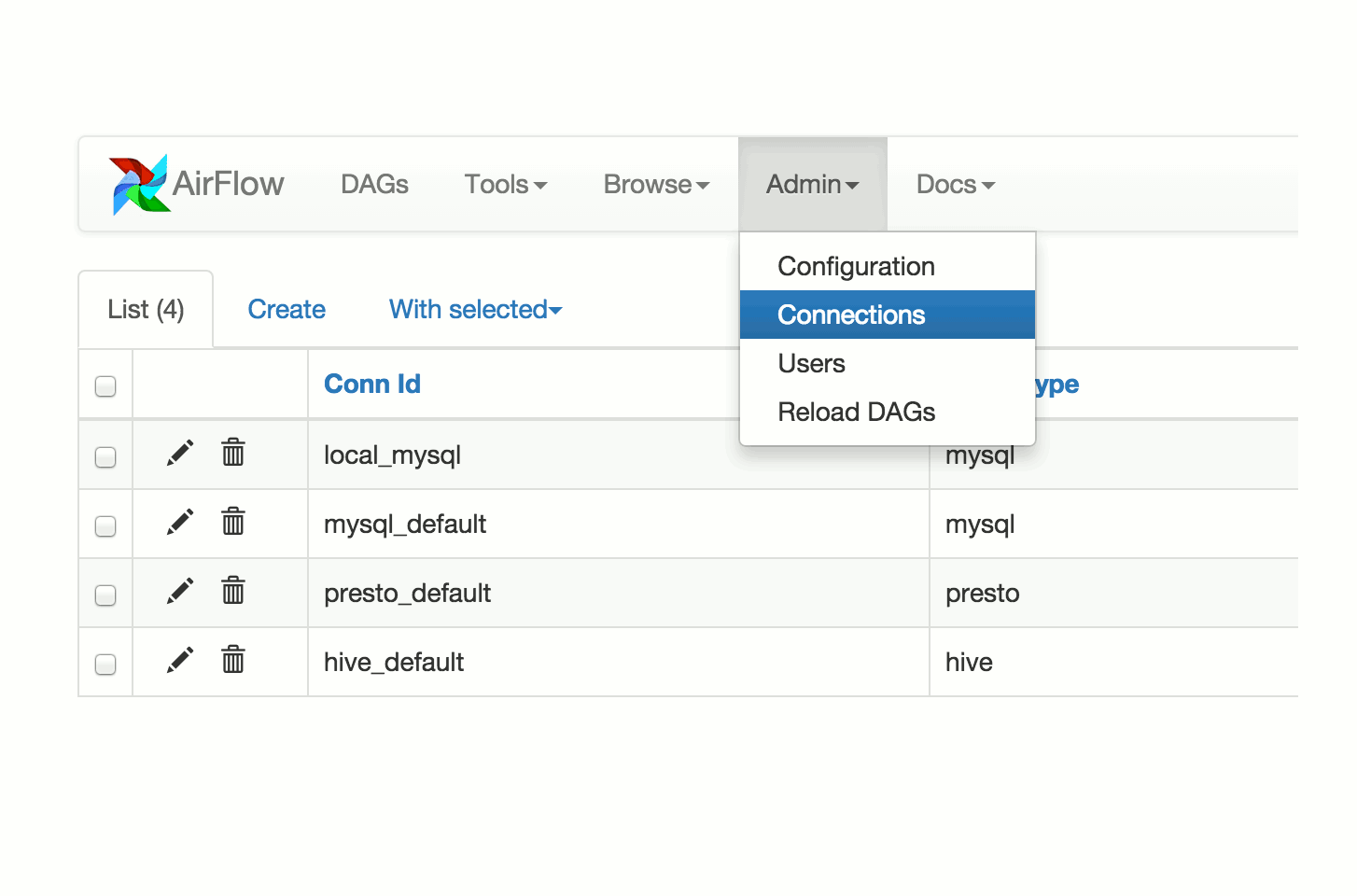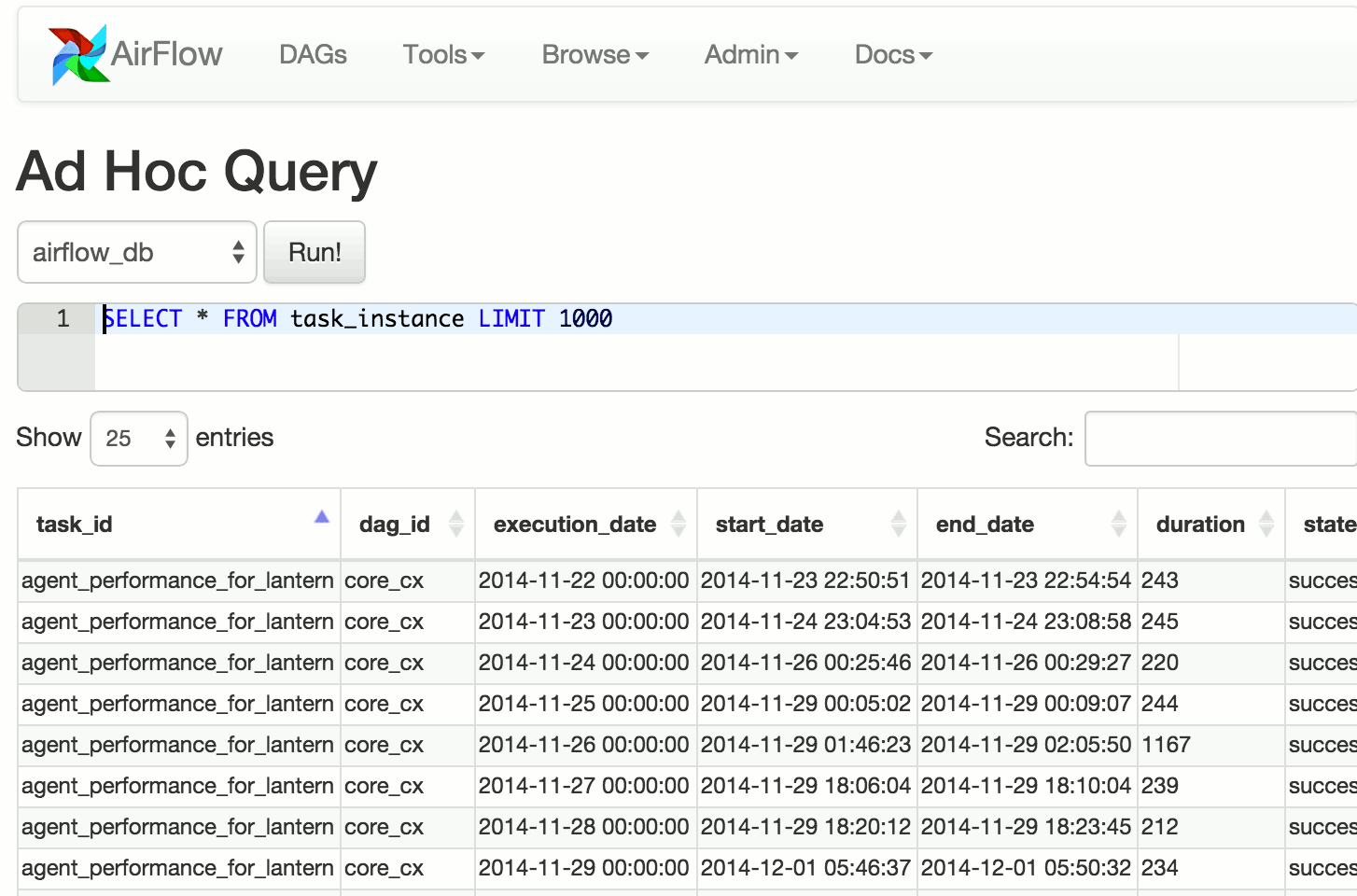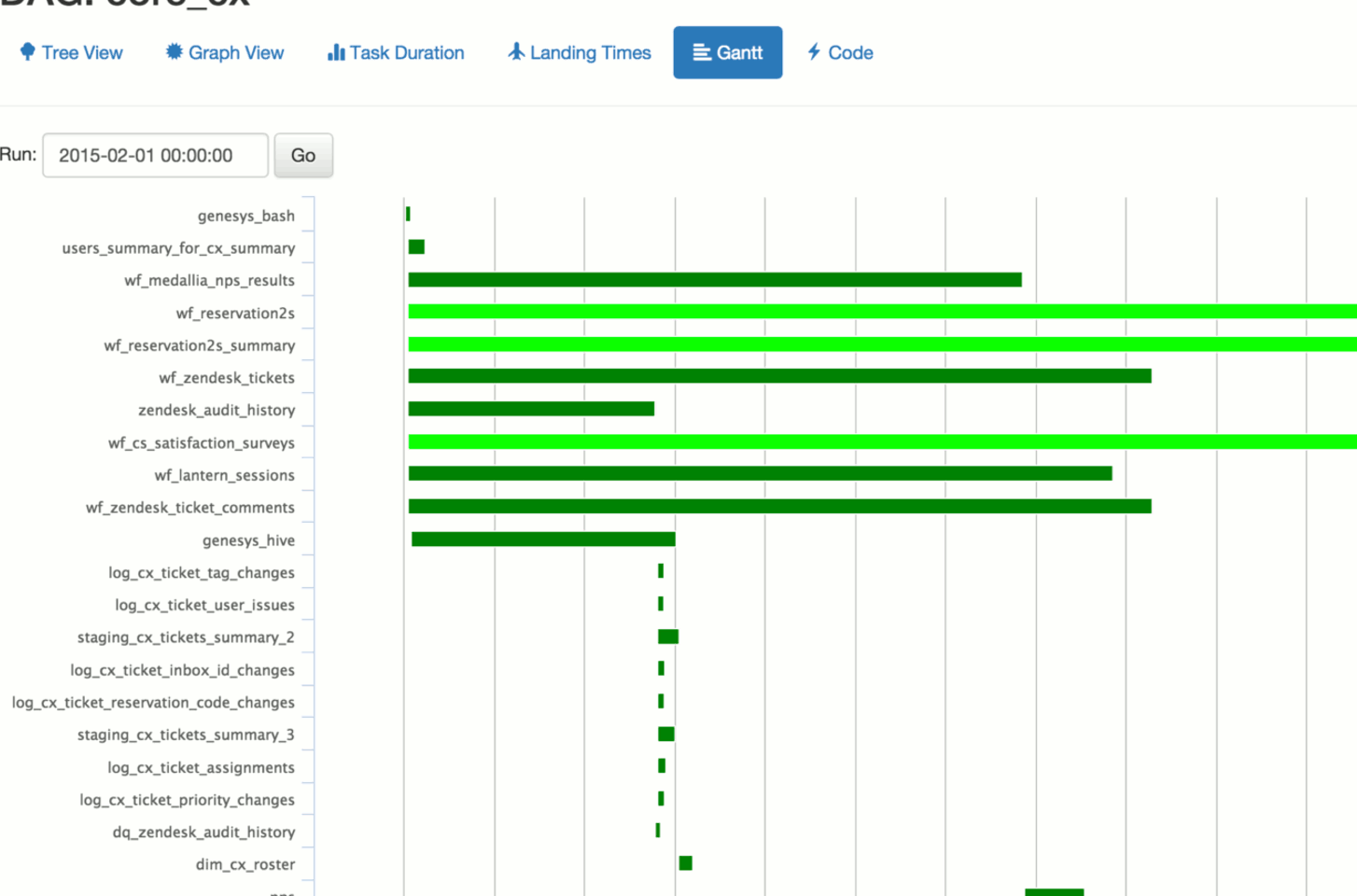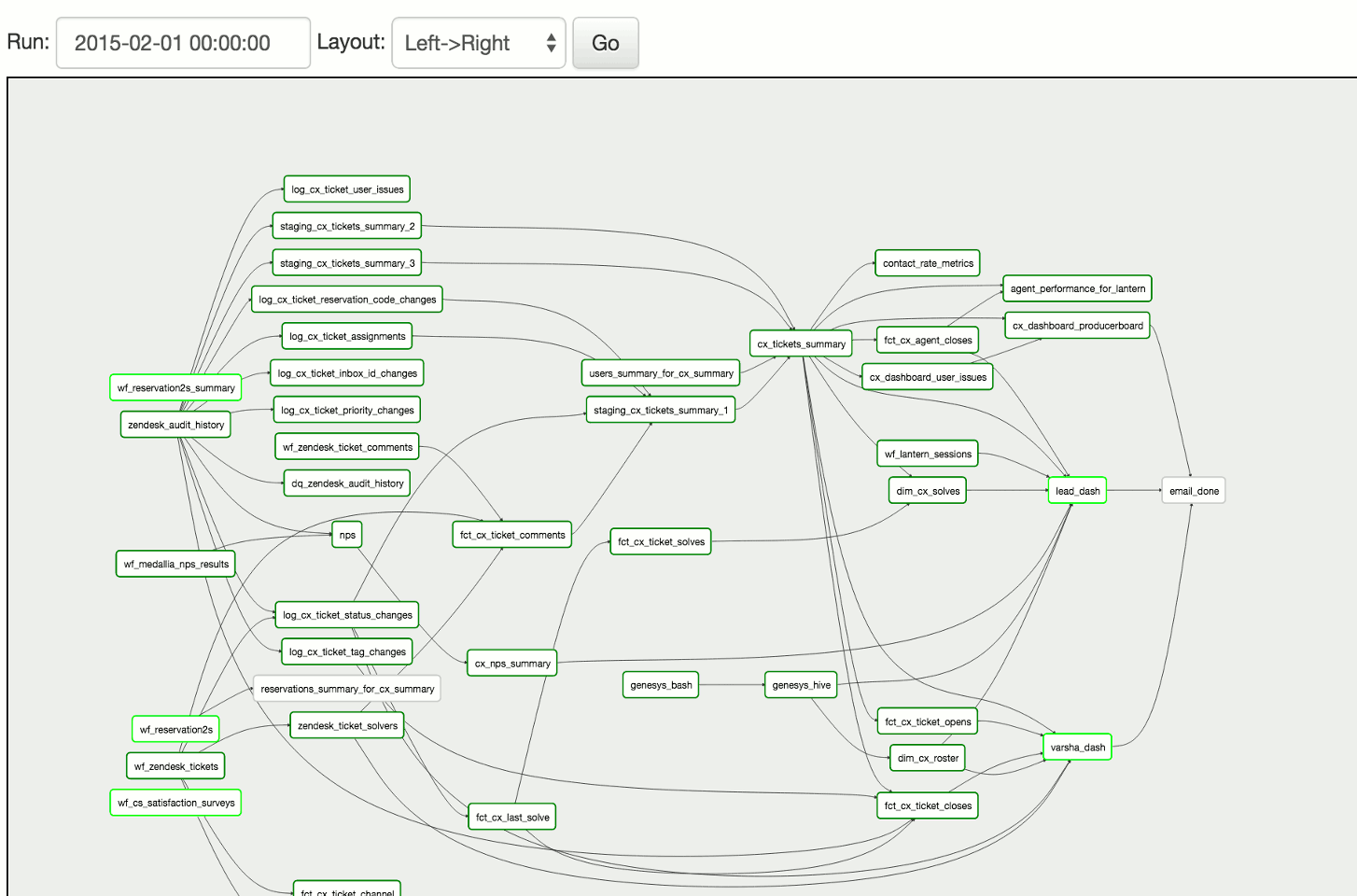
事實上我們也可以透過 Linux 排程工具 Cron 來定期執行我們的 App。但 Cron 本身沒有工作流程的概念,沒辦法管理上下游工作的相依性、失敗時無法自動重跑、當然也沒有易懂的 Web UI。因此以 2, 3, 4 項的角度來看,Airflow 是一個比較好的選擇。
到此為止,我們已經了解
- 為何要做這個 App
- 此 App 的工作流程以及工作流程(Workflow)的基本概念
- 為何要使用 Airflow 來幫我們管理 App 的工作流程
接著只差用 Python 將 App 的邏輯以 Airflow 工作流程的方式實現了,讓我們開始實作吧!

Python & Airflow 實作¶
程式碼都會放在這個 Github Repo 裡頭供你在閱讀完文章後參考。但如果你正在用電腦瀏覽的話且想趕快熟悉 Airflow 開發的話,可以 git clone 下來以後跟著文章走。
開啟一個新的 terminal,移動到你平常放新專案的資料夾,然後輸入:
git clone https://github.com/leemengtaiwan/airflow-tutorials.git
cd airflow-tutorials
之後沒特別明說的話,指令都會是在 airflow-tutorials 資料夾底下執行。
建置 Airflow 環境¶
雖然 production 環境需要很多調整,以建構測試環境來說,基本上參考官方的 Quick Start 就可以很輕鬆地完成。因為 Airflow 是以 Python 實作的,我們可以很輕易地用 pip install 來安裝所有需要的東西。用 Anaconda 則是能讓你事後管理不同專案的環境時輕鬆不少:
conda create -n airflow-tutorials python=3.6 -y
source activate airflow-tutorials
pip install "apache-airflow[crypto, slack]"
export AIRFLOW_HOME="$(pwd)"
airflow initdb
以上的指令幫我們:
- 建立並啟動一個新的 Anaconda 環境
- 在此環境下安裝 Airflow 以及支援 Slack 功能的額外函式庫
- 設定專用路徑以讓 Airflow 之後知道要在哪找檔案、存 log
- 初始化 Airflow Metadata DB。此 DB 被用來記錄所有工作流程的執行狀況
理想上把 AIRFLOW_HOME 加入到 ~/.bash_profile 裡頭之後會比較輕鬆,不過現在不做也沒關係。
【2018/08/27 加註】如果沒有設定 export AIRFLOW_HOME="$(pwd)" 就執行 airflow initdb的話,會讓 Airflow 使用作者當初測試時使用的路徑,而不是你 git clone 下來的 repo 的路徑而造成問題,務必記得設定。
在環境都搞定之後,我們可以啟動 Airflow 的網頁伺服器:
airflow webserver -p 8080
接著在瀏覽器輸入 localhost:8080 就能看到 Airflow 簡潔的 Web UI 了:
Airflow 基本概念¶
這邊值得注意的是 Airflow 利用 DAG 一詞來代表一種特殊的工作流程(Workflow)。如工作流程一樣,DAG 定義了我們有什麼工作、工作之間的執行順序以及依賴關係。DAG 的最終目標是將所有工作依照上下游關係全部執行,而不是關注個別的工作實際上是怎麼被實作的(這點在後面的 Operator 章節會有詳細解釋)。
另外從它的全名有向無環圖(Directed Acyclic Graph)你可以看出它具備兩個特色:「有向」及「無環」。事實上我們的 App 邏輯就是一個理想的 DAG。首先,裡頭包含多個邏輯上的工作:
- 取得使用者的閱讀紀錄
- 去漫畫網站看有沒有新的章節
- 跟紀錄比較,有沒有新連載?
- 沒有:
- 什麼都不幹,結束
- 有:
- 寄 Slack 通知
- 更新閱讀紀錄
- 沒有:
很明顯地, App 是從上而下地執行每個工作,即為「有向」;同時 App 不會在更新閱讀紀錄以後(下游工作),還跑回去漫畫網站看有沒有新的章節(上游工作):上游會指向下游,但下游不會指回上游,此即「無環」。
有了這個理解以後,我們的目標就很明顯了:將 App 的工作流程轉換成一個能在 Airflow 上執行的 DAG,然後排程它,就能讓它每天去找新連載!
App 版本一:大鍋炒¶
在 Airflow 世界裡,一個 DAG 是由一個 Python script 所定義的。
以下是我們 App 的第一個版本,也是最簡單的 DAG comic_app_v1 的程式碼(airflow-tutorials/dags 資料夾底下的 comic_app_v1.py):
import time
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
default_args = {
'owner': 'Meng Lee',
'start_date': datetime(2100, 1, 1, 0, 0),
'schedule_interval': '@daily',
'retries': 2,
'retry_delay': timedelta(minutes=1)
}
def fn_superman():
print("取得使用者的閱讀紀錄")
print("去漫畫網站看有沒有新的章節")
print("跟紀錄比較,有沒有新連載?")
# Murphy's Law
accident_occur = time.time() % 2 > 1
if accident_occur:
print("\n天有不測風雲,人有旦夕禍福")
print("工作遇到預期外狀況被中斷\n")
return
new_comic_available = time.time() % 2 > 1
if new_comic_available:
print("寄 Slack 通知")
print("更新閱讀紀錄")
else:
print("什麼都不幹,工作順利結束")
with DAG('comic_app_v1', default_args=default_args) as dag:
superman_task = PythonOperator(
task_id='superman_task',
python_callable=fn_superman
)
為了讓你能專注在 Airflow 及 DAG 最核心的概念,讓我先用 print() 假裝我們已經在一個函式 fn_superman 裡頭實作所有工作的邏輯了。在修改完代表一個 DAG 的 Python script 後,要確保 Airflow 能正確地將其視為一個 DAG,最基本的檢查就是用 Python 直接執行該 script。
你目前的 terminal 應該正被 Airflow 的網頁伺服器所使用。如果你還沒有把 AIRFLOW_HOME 加到 ~/.bash_profile 裡頭的話,開啟一個新的 terminal,重新進入 airflow-tutorials 資料夾以後執行:
source activate airflow-tutorials
export AIRFLOW_HOME="$(pwd)"
這邊我們為新的 terminal 啟動 Anaconda 環境,並告訴 Airflow 在 airflow-tutorials 資料夾底下找所有它要的東西。(之後要打開新的 terminal 也要做一樣的事情)
接著我們就可以用 Python 測試 script 的正確性:
python dags/comic_app_v1.py
沒有特別設定的話, Airflow 會去 AIRFLOW_HOME 路徑底下的 dags 子資料夾找 DAG,這也是為何我們在上面路徑有個 dags。(你可以去 Repo 確定檔案的路徑。)
如果沒有任何錯誤跑出來,恭喜!Airflow 能將其視為一個正常的 DAG 並顯示在 Web UI 上。之後只要你有修改 DAG 裡頭的程式碼,都應該做這個檢查。
這個 DAG 的程式碼雖不長,卻隱含了一些非常重要的概念。
輕鬆排程¶
with DAG('comic_app_v1', default_args=default_args) as dag:
...
靠近 Script 尾端的這行實際上就定義了我們的 DAG 並將它命名為 comic_app_v1。而此 DAG 的排程(Scheduling)設定如
'start_date': datetime(2100, 1, 1, 0, 0)代表從西元 2100 年開始第一次執行此 DAG- 每次執行之間間隔多久。
'schedule_interval': '@daily'代表每天執行一次 'retries': 2則允許 Airflow 在 DAG 失敗時重試 2 次- DAG 失敗後等多久後開始重試(
'retry_delay': timedelta(minutes=1)代表等一分鐘) - 更多更多 ...
乍看之下沒什麼了不起的,就是些設定。
但如果你有自己從頭實作過資料管道的經驗或者使用過 Cron 排程 ETL,就能體會 Airflow 這樣的「Configuration as Code」有多麽的強大:你只做一些設定(Config),Airflow 就幫你自動建立可靠、失敗時會自動重試的工作流程。

這些排程設定為了方便管理,一般都另外定義在 default_args 變數並放在 script 的最上面。
Operator:將實作邏輯跟 DAG 排程分離¶
最有趣的是我們使用 with 關鍵字來定義一個只屬於 comic_app_v1 DAG 的領域。在這裡頭我們則定義了唯一一個工作 superman_task 處理所有事情(你應該能猜到為何它被這樣命名):
with DAG('comic_app_v1', ...
superman_task = PythonOperator(
task_id='superman_task',
python_callable=fn_superman
)
這段程式碼用白話翻譯的話,就是說:
- 在 DAG
comic_app_v1裡頭,利用PythonOperator建立一個名為superman_task的工作,而實際執行這個工作的時候,呼叫fn_superman函式。
一個非常重要且需要你搞懂的概念是,現在說的工作(Task),是指那些實際透過程式碼宣告,在 DAG 裡頭被定義出來的工作,如 superman_task。
前面我們提到,App 概念上本身就包含了多個工作(步驟):
- 取得使用者的閱讀紀錄
- 去漫畫網站看有沒有新的章節
- 跟紀錄比較,有沒有新連載?
- 沒有:
- 什麼都不幹,結束
- 有:
- 寄 Slack 通知
- 更新閱讀紀錄
- 沒有:
這些是「邏輯上」的工作,而在 comic_app_v1 DAG 裡頭,為了方便說明,我們將它們全部包起來,定義成唯一一個 Airflow 工作: superman_task。(在 App 版本二:模組化章節裡,我們則會分別為這些「邏輯工作」建立他們自己的 Airflow 工作)。
回到 Opeartor 的話題。在 Airflow 裡頭,DAG 只知道有哪些工作以及這些工作之間的執行順序。而實際上這些工作要怎麼被完成,其實作邏輯則是由各種 Operator 負責。
你可以想像 Opeartors 就是幫我們完成特定種類工作的小幫手,像是一些常見的例子:
- PythonOperator 執行一個 Python 函式
- BashOperator 執行 Bash 指令
- S3KeySensor 監測 S3 上的檔案存不存在
- SlackAPIPostOperator 送訊息給 Slack
- ...
要建立一個 DAG 裡的工作(Task)就是依照你想要它完成的特定目標,來選擇合適的 Operator。比方說上面的 superman_task 就是透過 PythonOperator 來執行特定的 Python 函式 fn_superman,而該函式則把 App 裡頭所有的「邏輯工作」實作了。
PythonOperator 可以說是 Airflow 裡最基本也最強大的 Opeartors 之一。學會使用方法以後,你可以將任何你定義的 Python 函式變成一個 Airflow 工作。
基本的使用方法非常簡單,你只要指定一個可呼叫的 Python 函式給 python_callable 參數以及設定一個工作名稱(task_id)即可:
superman_task = PythonOperator(
task_id='superman_task',
python_callable=fn_superman
)
在後面的 Airflow 變數以及 Jinja 模板章節,我們則會看到如何使用其他 Operator 如 SlackAPIPostOperator 來新增一個可以幫我們送 Slack 訊息的工作。
測試開發 Airflow 工作¶
你現在應該已經理解 DAG 本身關注的是有哪些工作以及他們的相依性,而不是各個工作的實作邏輯。(雖然在 comic_app_v1 DAG 裡頭只有一個工作所以不存在相依性問題)
我們用 python dags/comic_app_v1.py 確保 DAG 本身沒有語法問題以後,接著就是要確保裡頭每個工作(Task)的執行結果如我們預期。
在 comic_app_v1 DAG 裡頭,我們只有一個工作 superman_task (其透過一個函式 fn_superman 幫我們做所有邏輯上的工作):
def fn_superman():
print("取得使用者的閱讀紀錄")
print("去漫畫網站看有沒有新的章節")
print("跟紀錄比較,有沒有新連載?")
# Murphy's Law
accident_occur = time.time() % 2 > 1
if accident_occur:
print("\n天有不測風雲,人有旦夕禍福")
print("工作遇到預期外狀況被中斷\n")
return
new_comic_available = time.time() % 2 > 1
if new_comic_available:
print("寄 Slack 通知")
print("更新閱讀紀錄")
else:
print("什麼都不幹,工作順利結束")
with DAG('comic_app_v1', default_args=default_args) as dag:
superman_task = PythonOperator(
task_id='superman_task',
python_callable=fn_superman
)
這樣的設計有什麼優點?
一般來說 DAG 跟工作是一對多的關係(一個工作流程裡有多個小工作要做):要讓一個 DAG 順利跑完,理所當然所有工作都要順利執行完畢。但 comic_app_v1 DAG 是個特例,它裡頭只有一個工作,一人吃全家飽。只要測試且確保 superman_task 工作的執行結果如我們預期,就代表 DAG comic_app_v1 能順利完成,簡單易懂!
我們可以使用 Airflow 的 test 指令來幫我們測試這個工作:
airflow test comic_app_v1 superman_task 2018-08-18
這行指令是讓 Airflow 幫我們測試 comic_app_v1 DAG 裡頭的 superman_task 工作,並假設這個工作是在 2018-08-18 這個日期被執行。在我們的 App 例子中,superman_task 工作的執行結果基本上不會受到執行日期的影響,可以隨便你改。
但想像一個每天 24 點 0 分準備被啟動,從資料庫撈出數據並計算「當天」使用者數目的工作。其 SQL 查詢可能長這樣:
SELECT COUNT(user_id) AS num_new_users
FROM user_activities
WHERE dt = '{execute_date}'
因為此工作的結果會受到執行日期的影響,在測試的時候,你就得仔細選擇執行日期(execute_date)。
拉回 superman_task 工作的測試。
從上面 fn_superman 函式的程式碼你可能已經注意到,我埋了個小彩蛋,每次執行都會有不同的執行結果。
幸運的話你會得到下面這種:
airflow test comic_app_v1 superman_task 2018-08-01
取得使用者的閱讀紀錄
去漫畫網站看有沒有新的章節
跟紀錄比較,有沒有新連載?
什麼都不幹,工作順利結束
喔耶!這執行結果如我們預期,可以讓 DAG 上線定期執行了!
不過別高興得太早。多執行幾次看看。如果墨菲定律發生,你會得到失敗的結果:
airflow test comic_app_v1 superman_task 2018-08-01
取得使用者的閱讀紀錄
去漫畫網站看有沒有新的章節
跟紀錄比較,有沒有新連載?
天有不測風雲,人有旦夕禍福
工作遇到預期外狀況被中斷
假設此執行結果不是我們預期的結果,該怎麼辦?
如果你反應夠快,會說:
「那又怎麼樣?墨菲定律不會每次發生,而且就算遇到而導致工作失敗的話, Airflow 不是會自己幫我們重試嗎?」
的確,這是我們在前面輕鬆排程章節提到 Airflow 的強處。畢竟我們這 App 只是在檢查最新連載,不是做什麼很複雜的運算。基本上就算 DAG 裡頭這唯一一個工作 superman_task 失敗了導致整個 DAG 要重跑,Airflow 也可以應付得來。
但問題在於,企業在運行資料管道的時候,常常需要分成很多步驟,某些步驟可能需要龐大的計算資源跟時間(像是將每天使用者使用 App 的幾億筆紀錄做匯總存入資料庫),有些則很輕量(如存取一個外部 API 取得外匯比例)。
現在假設你無視這些不同步驟的性質差異,將它們全部放在一個 fn_superman 函式裡頭並只建立一個 Airflow 工作,當該 Airflow 工作裡頭任何一個輕量的步驟失敗,Airflow 得重跑整個工作,導致所有龐大計算的步驟也得跟著重新執行,重試的時間/計算成本會大到你哭出來。
雞蛋不要放在同個籃子裡。為邏輯上獨立的工作/步驟分別建立 Airflow 工作,可以讓 Airflow 只從失敗的工作開始重新做起。
因此一個比較好的 Airflow DAG 設計模式是為我們 App 裡頭每個邏輯上獨立的工作:
- 取得使用者的閱讀紀錄
- 去漫畫網站看有沒有新的章節
- 跟紀錄比較,有沒有新連載?
- 沒有:
- 什麼都不幹,結束
- 有:
- 寄 Slack 通知
- 更新閱讀紀錄
- 沒有:
都分別建立如同 superman_task 的 Airflow 工作,並定義好它們之間的相依性(Dependencies)。而這將是我們下一節的重點。
題外話:你可能會納悶為何我們只測試 superman_task 工作而沒測試整個 comic_app_v1 DAG。當然「一人吃全家飽」是個理由:只要確定 DAG 裡頭唯一一個工作正確運作,我們就能保證此 DAG 沒問題。
事實上還有一個原因:airflow test 指令實際上只能用來測試單一工作,而不能測試整個 DAG。關於 DAG 的測試我們在後面的 Airflow 排程器 章節會詳細說明。
App 版本二:模組化¶
所以現在我們要做的改善(Refactoring)很簡單:
- 將 App 邏輯從
comic_app_v1DAG 中的函式fn_superman中拿出來 - 為 App 的每個步驟分別定義一個 Python 函式
- 在 DAG 裡頭利用
PythonOperator建立多個 Airflow 工作並分別呼叫這些函式 - 定義這些工作的執行順序
版本二的 App 完整的程式碼如下:
import time
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.python_operator import PythonOperator, BranchPythonOperator
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.slack_operator import SlackAPIPostOperator
default_args = {
'owner': 'Meng Lee',
'start_date': datetime(2100, 1, 1, 0, 0),
'schedule_interval': '@daily',
'retries': 2,
'retry_delay': timedelta(minutes=1)
}
def process_metadata(mode, **context):
if mode == 'read':
print("取得使用者的閱讀紀錄")
elif mode == 'write':
print("更新閱讀紀錄")
def check_comic_info(**context):
all_comic_info = context['task_instance'].xcom_pull(task_ids='get_read_history')
print("去漫畫網站看有沒有新的章節")
anything_new = time.time() % 2 > 1
return anything_new, all_comic_info
def decide_what_to_do(**context):
anything_new, all_comic_info = context['task_instance'].xcom_pull(task_ids='check_comic_info')
print("跟紀錄比較,有沒有新連載?")
if anything_new:
return 'yes_generate_notification'
else:
return 'no_do_nothing'
def generate_message(**context):
_, all_comic_info = context['task_instance'].xcom_pull(task_ids='check_comic_info')
print("產生要寄給 Slack 的訊息內容並存成檔案")
with DAG('comic_app_v2', default_args=default_args) as dag:
get_read_history = PythonOperator(
task_id='get_read_history',
python_callable=process_metadata,
op_args=['read']
)
check_comic_info = PythonOperator(
task_id='check_comic_info',
python_callable=check_comic_info,
provide_context=True
)
decide_what_to_do = BranchPythonOperator(
task_id='new_comic_available',
python_callable=decide_what_to_do,
provide_context=True
)
update_read_history = PythonOperator(
task_id='update_read_history',
python_callable=process_metadata,
op_args=['write'],
provide_context=True
)
generate_notification = PythonOperator(
task_id='yes_generate_notification',
python_callable=generate_message,
provide_context=True
)
send_notification = SlackAPIPostOperator(
task_id='send_notification',
token="YOUR_SLACK_TOKEN",
channel='#comic-notification',
text="[{{ ds }}] 海賊王有新番了!",
icon_url='http://airbnb.io/img/projects/airflow3.png'
)
do_nothing = DummyOperator(task_id='no_do_nothing')
# define workflow
get_read_history >> check_comic_info >> decide_what_to_do
decide_what_to_do >> generate_notification
decide_what_to_do >> do_nothing
generate_notification >> send_notification >> update_read_history
天啊這可比 comic_app_v1 DAG 的程式碼長了不少!
不過在你開始懷疑自己適不適合寫 Airflow DAG 之前讓我提醒你一下。就跟我們剛剛上面提到的,實際上這個 comic_app_v2 DAG 的架構從上到下也就分為三個區塊:
- 用
def定義負責實作的 Python 函式(們) - 在 DAG 利用各種
Operator定義 DAG 工作(大部分是PythonOperator,並使用python_callable指定執行步驟 1 定義的函式) - 定義這些 DAG 工作的執行順序(Workflow)
回頭再看一遍,有沒有清楚一點了?
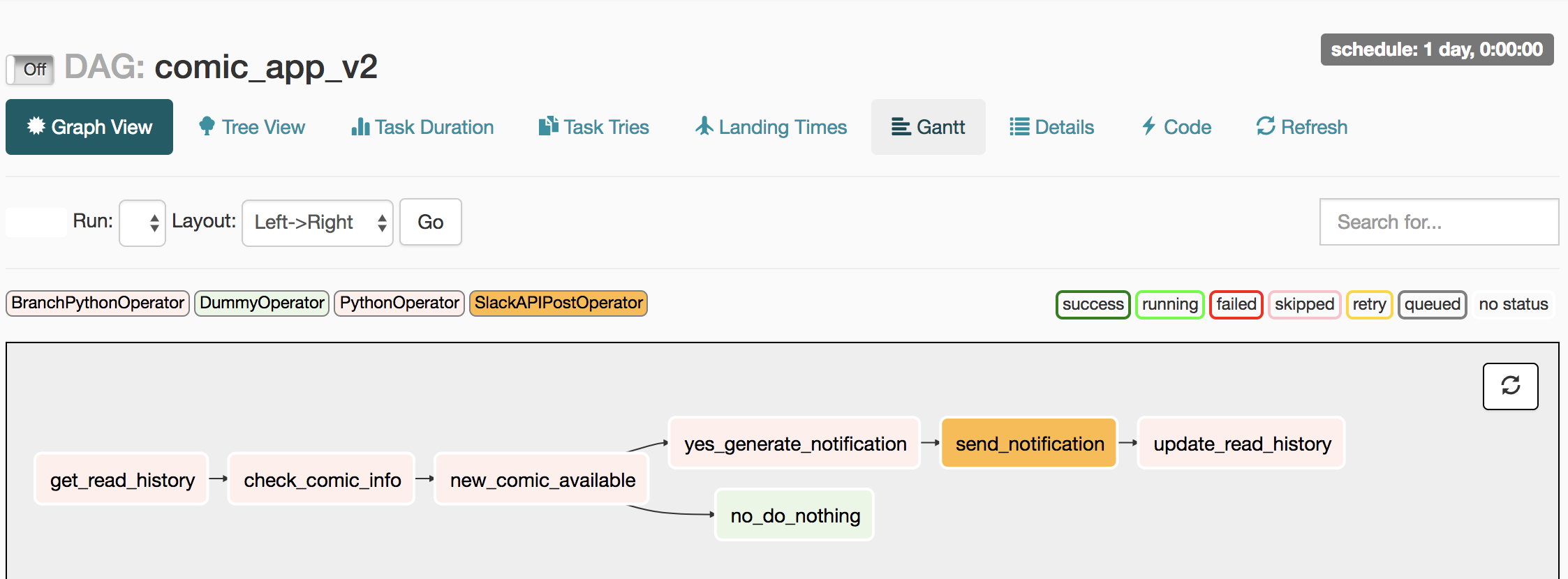
在細看 comic_app_v2 的程式碼前,先讓我們用 Airflow Web UI 研究一下這個 DAG 在做什麼:
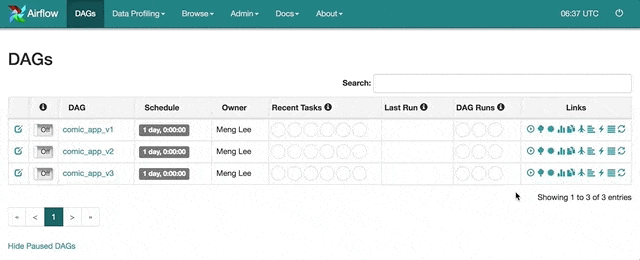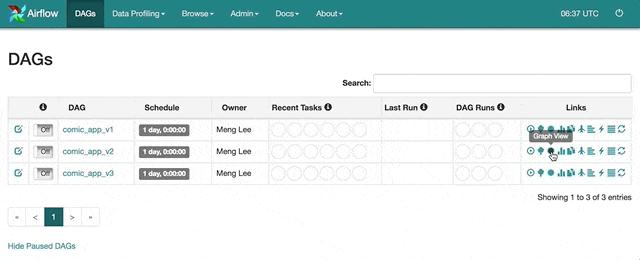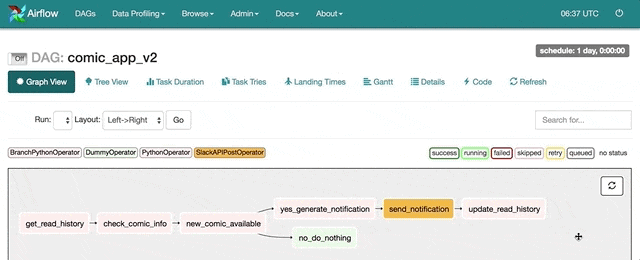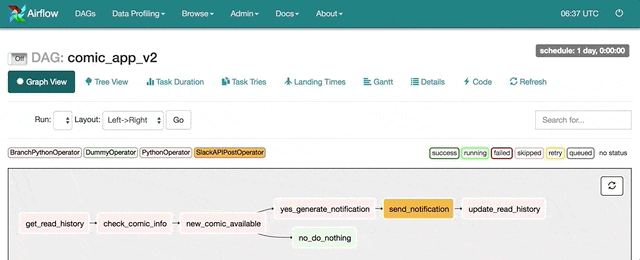
Airflow 工作寫成英文是為了方便使用 airflow test 指令測試每個工作。
儘管工作名稱都是英文,你應該不會覺得陌生。因為這就是我們 App 的邏輯:
- 取得使用者的閱讀紀錄(get_read_history)
- 去漫畫網站看有沒有新的章節(check_comic_info)
- 跟紀錄比較,有沒有新連載?(new_comic_available)
- 沒有(no_do_nothing)
- 有(yes_generate_notification)
- 寄 Slack 通知(send_notification)
- 更新閱讀紀錄(update_read_history)
看來這應該不是巧合:)
Airflow 排程器¶
如同當初測試 comic_app_v1 DAG 裡頭的 superman_task 工作一樣,在我們放心讓 Airflow 幫我們排程 comic_app_v2 DAG 以前,應該分別測試裡頭所有工作,確保它們的執行結果如我們預期:
airflow test comic_app_v2 get_read_history 2018-01-01
取得使用者的閱讀紀錄
airflow test comic_app_v2 check_comic_info 2018-01-01
跟紀錄比較,有沒有新連載?
airflow test comic_app_v2 new_comic_available 2018-01-01
去漫畫網站看有沒有新的章節
...
假設我們已經做完所有工作的測試,想讓 comic_app_v2 DAG 開始被 Airflow 排程,除了已經被開啟的 Airflow 網頁伺服器以外,我們需要另外開啟 Airflow 排程器(Scheduler)。
因為目前為止一直在運轉的 Airflow 網頁伺服器只負責:
- 顯示 DAG 資訊,如工作流程圖、各個 DAG 的運行狀況以及 Logs
- 讓我們輕鬆地終止/開始 DAG 排程(在有排程器的前提)
而實際要執行 DAG、分配每個工作的運算資源則需要 Airflow 排程器。Airflow 的架構圖能幫助我們理解這件事情:
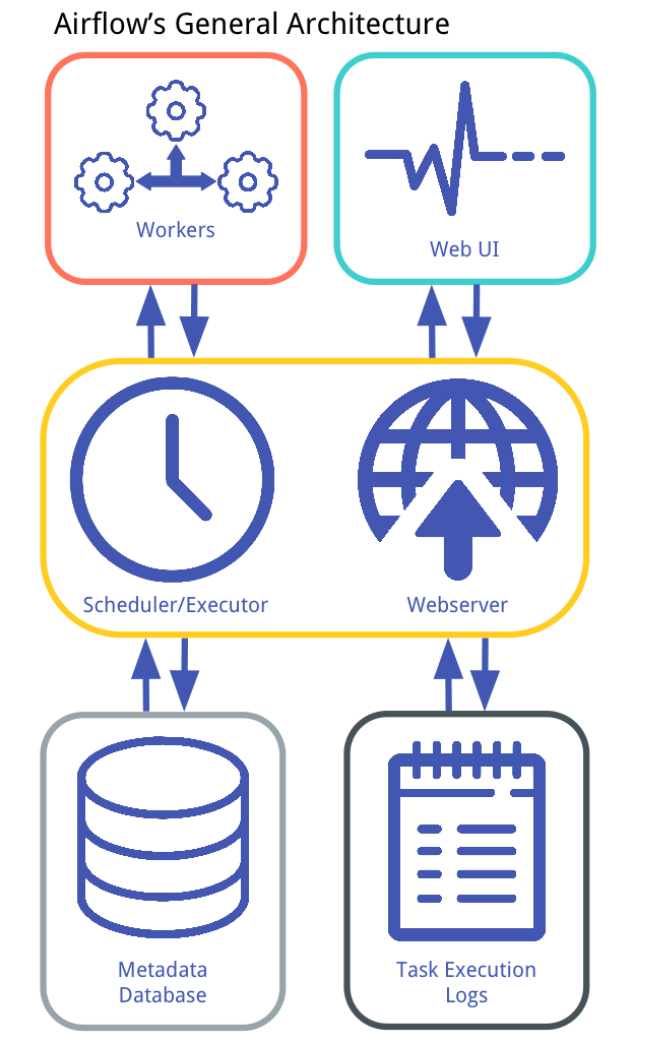
事不宜遲,讓我們啟動 Airflow 排程器吧!
現在再打開一個 terminal,進入 airflow-tutorials 資料夾後設定環境:
export AIRFLOW_HOME="$(pwd)"
source activate airflow-tutorials
接著啟動排程器:
airflow scheduler
到目前為止你應該有 3 個 terminals 各司其職:
- 用來輸入
airflow相關指令的 terminal - Airflow Webserver
- Airflow Scheduler
我保証不會再多了。
有了排程器以後,打開 UI,在左邊將 comic_app_v2 DAG 設成「On」後,點擊右邊「Trigger Dag」按鈕可以呼叫排程器馬上開始執行該 DAG。先讓我們按下去以後,再讓我解釋這樣做會發生什麼事情。
為了避免預料之外的排程,Airflow 所有 DAG 的預設狀態都是暫停的(Paused),也就是上圖中如 comic_app_v1 左邊的「Off」。只有在你將 DAG 的狀態設定成如圖中的 comic_app_v2 的「On」,排程器才會開始為其做排程。
手動觸發 DAG¶
雖說將一個 DAG 取消暫停(Unpause)可以讓它成為 Airflow 的排程對象,實際上 Airflow 的排程又分兩種方式:
- 手動觸發(Manual)
- 常用在測試 DAG 或是有意外發生,需要手動重新執行 DAG 的時候
- 定期執行(Scheduled)
- 也就是所謂的「正式上線」。
- 依照 DAG 的
start_date及schedule_interval設定決定何時執行
現在讓我們先專注在手動觸發。
當然你也可以在不透過 Web UI 的情況下,直接利用 terminal 取消暫停一個 DAG 並觸發它:
airflow unpause comic_app_v2
airflow trigger_dag comic_app_v2理論上我們剛剛手動觸發的 comic_app_v2 應該已經跑完了。重新整理你應該會看到 Airflow UI 顯示 DAG 已被成功執行的畫面:
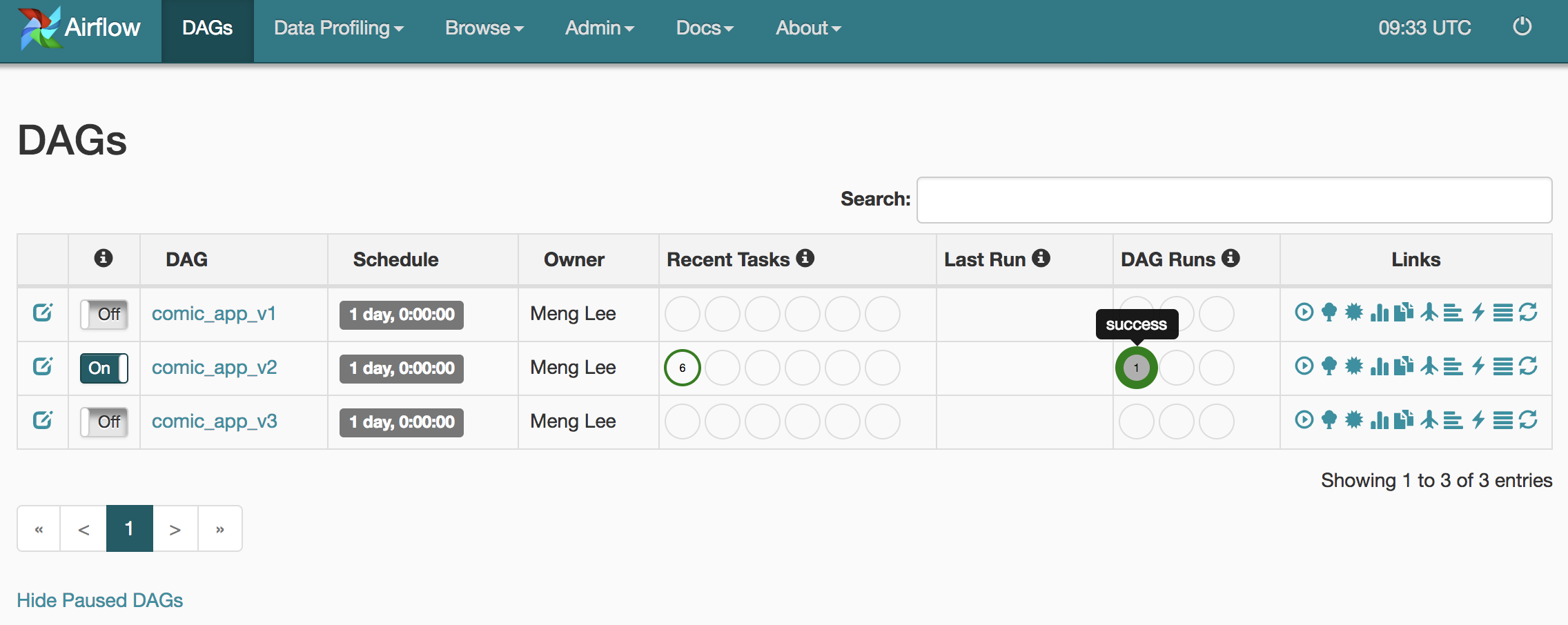
從 Web UI 我們可以清楚地看到剛剛手動觸發的 comic_app_v2 DAG 已經被 Airflow 排程器拿去執行,產生一個新的 DAG Run 並成功執行。DAG 跟 DAG Run 的差異在於前者只是個定義好的工作流程,後者則是該 DAG 在某個時間點實際被排程器拿去執行(Run)過後的結果,會有一個執行日期(execute_date)。
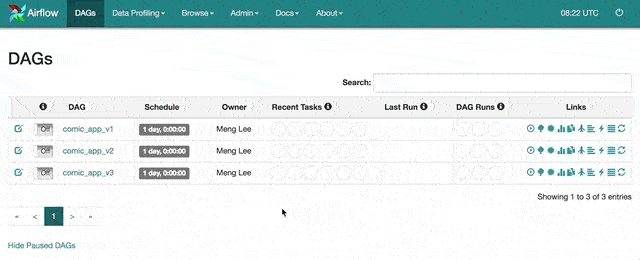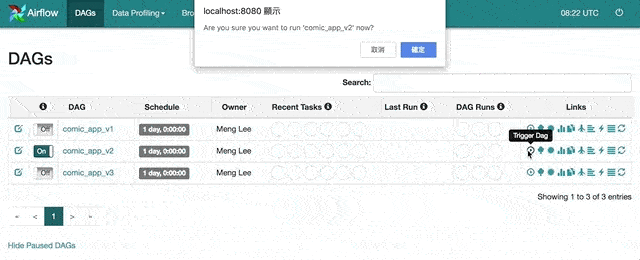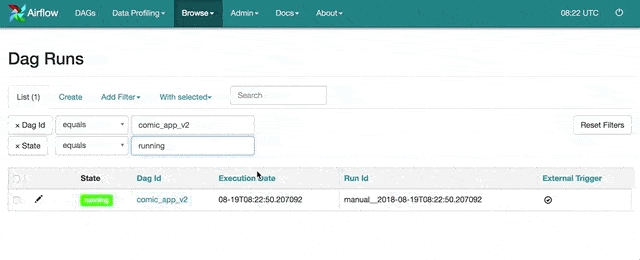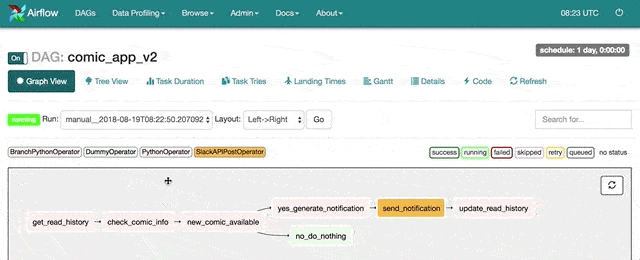
接著點擊右邊 Links 中長得像太陽的 Graph View 按鈕後就可以看到這個 DAG Run 的執行狀況:
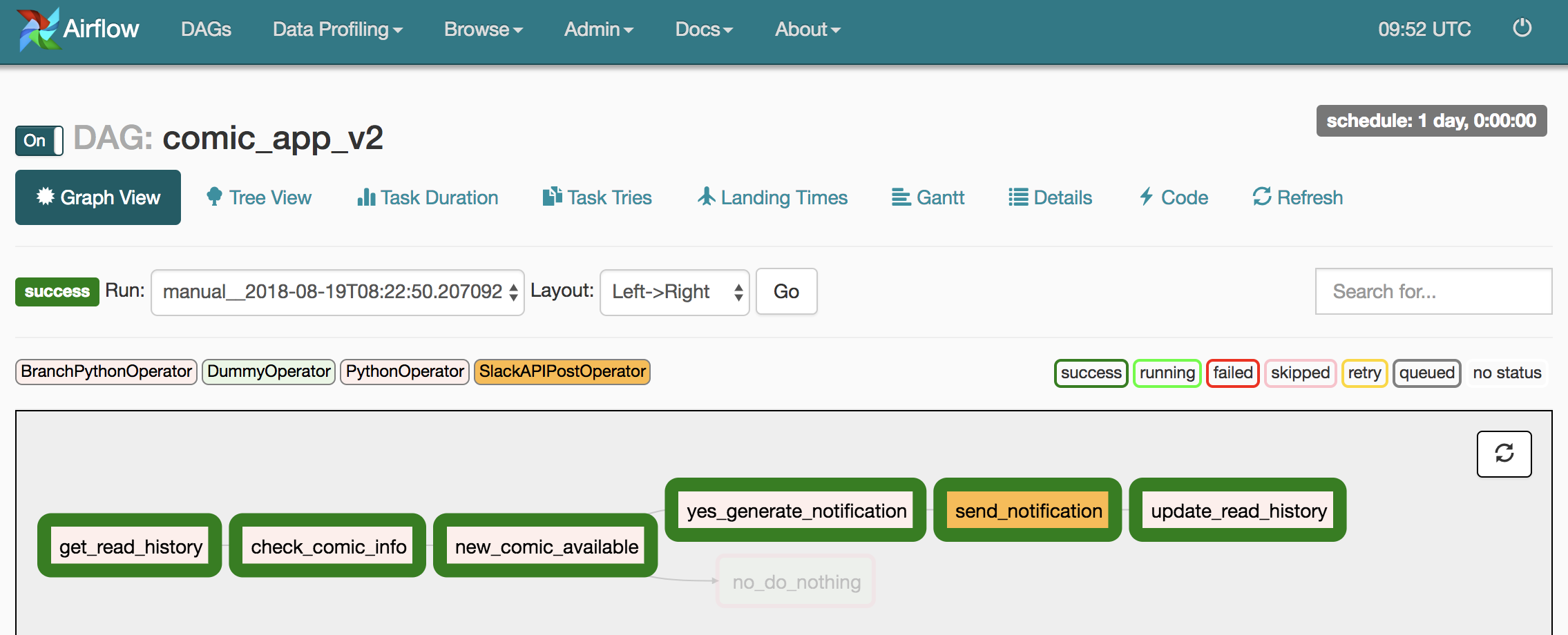
我們可以清楚地看到這個 DAG Run 完美地模擬了我們 App 在檢查到新連載情報時送 Slack 訊息給我們的情境。我甚至收到一個 Slack 訊息:

定義工作流程¶
要在 DAG 裡頭定義出如上圖的工作流程也非常的直觀,讓我們參考這兩個工作:
- yes_generate_notification
- send_notification
它們在 dags/comic_app_v2.py 裡頭被這樣定義(節錄最重要的部分):
with DAG('comic_app_v2', default_args=default_args) as dag:
...
generate_notification = PythonOperator(
task_id='yes_generate_notification',
...
)
send_notification = SlackAPIPostOperator(
task_id='send_notification',
...
)
# define workflow
generate_notification >> send_notification >> ...
你可以發現在 comic_app_v2 DAG 裡,我們分別定義好這兩個工作以後,在最下面用 >> 語法告訴 Airflow 這兩個工作的相依性:
yes_generate_notification工作要在send_notification之前執行
另外眼尖的讀者會發現,Python 變數名稱 generate_notification 跟實際上的工作名稱(task_id) yes_generate_notification 並不一致。我們將實際的工作 PythonOperator 命名為 generate_notification,只是為了後面在定義工作流程的時候好提到它。參考下面的程式碼:
with DAG('comic_app_v2', default_args=default_args) as dag:
...
task1 = PythonOperator(
task_id='yes_generate_notification',
...
)
task2 = SlackAPIPostOperator(
task_id='send_notification',
...
)
# define workflow
task1 >> task2 >> ...
這段程式碼跟上一段程式碼在定義工作流程上有一模一樣的效果,只是後者的 naming convention 在定義工作流程的時候比較易懂。
雖然要多打幾個字,為了其他 DS/DE 以及未來的自己,一般推薦 Python 變數名稱取跟 task_id 類似的名字。
針對其他工作,我們也是用相同語法將它們串起來:
...
decide_what_to_do = BranchPythonOperator(
task_id='new_comic_available',
python_callable=decide_what_to_do,
provide_context=True
)
...
get_read_history >> check_comic_info >> decide_what_to_do
decide_what_to_do >> generate_notification
decide_what_to_do >> do_nothing
generate_notification >> send_notification >> update_read_history
然後我們就得到前面看過的工作流程圖了:
你也可以回到 App 版本二:模組化章節,確認 comic_app_v2 完整的程式碼後再利用左邊的傳送門回來,我等你。
Airflow 變數以及 Jinja 模板¶
現在你應該已經了解如何使用 PythonOperator 建立一個新的工作,並利用 >> 語法定義 Airflow 的工作流程(DAG)了。我們也實際觸發 comic_app_v2 DAG 讓 Airflow 排程器幫我們排程,最後收到一個 Slack 訊息。
現在讓我們仔細研究一下負責寄 Slack 訊息的工作,也就是下圖的 send_notificiation:
你會發現它的顏色跟其他工作不一樣,這是因為它並不是一個 PythonOperator,而是一個 SlackAPIPostOperator。由此 Operator 定義的工作並不會呼叫一個 Python 函式,而是直接呼叫 Slack API 來傳送訊息。下面是我們在當初落落長的 comic_app_v2 DAG 裡頭定義的 send_notificiation:
send_notification = SlackAPIPostOperator(
task_id='send_notification',
token="YOUR_SLACK_TOKEN",
channel='#comic-notification',
text="[{{ ds }}] 海賊王有新番了!",
icon_url='http://airbnb.io/img/projects/airflow3.png'
)
注意 text 參數的值。 {{ ds }} 實際上是 Jinja 語法,它允許我們將 Python 變數渲染(Render)到字串裡頭,動態地產生文本。這就像是我們有個變數 ds,然後利用 format 語法一樣:
text = "[{ds}] 海賊王有新番了!".format(ds=ds)而這邊的重點是 Airflow 在執行一個 DAG 的時候會提供一些預設的環境變數供我們使用,像是:
ds:代表 DAG Run 的執行日期(execute_date),以YYYY-MM-DD形式表現yesterday_ds:DAG Run 的執行日期的前一天,以YYYY-MM-DD形式表現tomorrow_ds:DAG Run 的執行日期的後一天,以YYYY-MM-DD形式表現- ...
而因為我們在 2018-08-19 的時候,利用下面這個指令手動觸發 comic_app_v2 DAG:
airflow trigger_dag comic_app_v2
Airflow 會將實際執行該 DAG 的日期設定為執行日期(execute_date)。因此 ds 即為 2018-08-19,SlackAPIPostOperator 裡頭的 "[{{ ds }}] 海賊王有新番了!" 就會被渲染成 [2018-08-19] 海賊王有新番了!。
最後我們就得到這個 Slack 訊息:
現在你也了解使用 Jinja 語法可以動態地調整每次 DAG 運行的邏輯以及執行結果。讓我們實際將 comic_app_v2 DAG 丟上線試試看吧!
執行日期:排程最重要的概念¶
經過前面的幾個章節,我們已經對 comic_app_v2 DAG 的測試及開發下了不少功夫:
- 利用
airflow test指令分別測試每個 Airflow 工作執行如預期 python dags/comic_app_v2.py確保 DAG 定義無誤- 使用 Web UI 點擊「 Trigger Dag 」按鈕或是透過
airflow trigger來手動觸發 DAG 確認結果
這些都是將一個 DAG 正式上線前必須完成的步驟。在這些測試都完成以後,是時候將我們的 comic_app_v2 DAG 交給 Airflow 排程器,讓 Airflow 幫我們每天執行這個 DAG 了!
在手動觸發 DAG 章節我們有看到,要讓 Airflow 排程器開始排程一個 DAG,首先要終止暫停(Unpause)該 DAG。而為何當時 Airflow 沒有在我們 comic_app_v2一終止暫停 就開始自動排程,而要等到我們手動觸發呢?
這是因為當時的 comic_app_v2 的排程設定如下:
default_args = {
'owner': 'Meng Lee',
'start_date': datetime(2100, 1, 1, 0, 0),
'schedule_interval': '@daily',
...
with DAG('comic_app_v2', default_args=default_args) as dag:
...
'start_date': datetime(2100, 1, 1, 0, 0) 代表我們希望 comic_app_v2 DAG 的第一個執行日期(execute_date)為西元 2100 年 1 月 1 號 0 點。
你可能覺得為何要把話說得那麼複雜,就說:
- 「 Airflow 排程器會在 西元 2100 年 1 月 1 號 0 點第一次執行此 DAG 」
不就好了嗎?
不這麼說的原因,就是因為上面的理解是錯的。事實上這是很多人在利用 Airflow 排程時最容易搞錯的概念之一,值得花點篇幅徹底搞清楚。
假如西元 2100 年我們架的 Airflow 排程器還在運作的話,它會在:
start_date 2100 年 1 月 1 號 0 點 0 分 + 1 * schedule_interval
= 2100 年 1 月 1 號 0 點 0 分 + 1 * @daily
= 2100 年 1 月 1 號 0 點 0 分 + 1 * 24 小時
= 2100 年 1 月 2 號 0 點 0 分
也就是 2100 年 1 月 2 號 0 點 0 分的時候,將 comic_app_v2 DAG 拿出來做第一次執行,而該 DAG Run 的執行日期為 2100 年 1 月 1 號 0 點 0 分。

要理解為何我們一開始的猜想:
- 「 Airflow 排程器會在 西元 2100 年 1 月 1 號 0 點第一次執行此 DAG 」
是非常矛盾的,讓我們做個我最愛的假想實驗。還記得在測試開發 Airflow 工作章節提到的 SQL 查詢嗎?
SELECT COUNT(user_id) AS num_new_users
FROM user_activities
WHERE dt = '{execute_date}'
現在假設我們給這個工作跟 comic_app_v2 一模一樣的排程設定:
'start_date': datetime(2100, 1, 1, 0, 0)
'schedule_interval': '@daily'
根據本章節一開始的敘述,這個 DAG 的第一個執行日期(execute_date)為 2100-01-01。而按照我們在 Airflow 變數以及 Jinja 模板章節所說的,此 SQL 查詢裡頭的 Jinja 語法會被渲染成:
SELECT COUNT(user_id) AS num_new_users
FROM user_activities
WHERE dt = '2100-01-01'
接著假設我們一開始的猜想:
- 「 Airflow 排程器會在 西元 2100 年 1 月 1 號 0 點第一次執行此 DAG 」
是對的話,該 SQL 查詢會取回什麼資料?
答案是什麼都沒有。
因為如果這猜想是對的話,這個 SQL 查詢工作會馬上在西元 2100 年 1 月 1 號的 0 點,想辦法去把西元 2100 年 1 月 1 號整天的使用者資料全部撈出來。而因為此 SQL 查詢執行時, 1 月 1 號才剛開始,這個查詢不會取得任何資料。
很明顯哪裡出了差錯了。
而如果照我剛剛解釋的版本,就會顯得合理許多:
- 在 2100 年 1 月 2 號 0 點的時候,以下的 SQL 查詢會被執行
SELECT COUNT(user_id) AS num_new_users
FROM user_activities
WHERE dt = '2100-01-01'
這代表我們在 1 月 1 號 23 點 59 分結束以後,也就是 1 月 2 號 0 點的時候,將 1 月 1 號所有的使用者資料做彙總。
一般而言,Airflow 會在 start_date 加上一個 schedule_interval 之後開始第一次執行某個 DAG,而該 DAG Run 的 execute_date 為 start_date。這樣的設計就是為了避免像是上面那個 SQL 查詢在當天才剛開始的時候就想要搜集該天所有資料的窘境。
Airflow 擅長的是管理那些允許「事件發生時間」跟「實際數據處理時間」有落差的批次工作。因此 Airflow 都會在 start_date 加上 schedule_interval 長度的時間過完以後,才開始處理發生在 start_date 到 start_date + schedule_interval 之間的資料。
再換句話說,
一個 DAG Run 中的執行日期,只等於它「負責」的日期,不等於它實際被 Airflow 排程器執行的日期。一個被自動排程且執行日期為 dt 的 DAG Run,實際上是在 dt + schedule_period 後被 Airflow 執行。
我們換了好幾種說法,希望你能百分之百地掌握這個 Airflow 排程的概念,因為這實在太重要了。
有了這章節的排程概念以後,我們可以正式開始排程 comic_app_v2 DAG 了!
正式排程¶
經過上一章節排程概念的洗禮,想必你還記得 comic_app_v2 DAG 的開始排程日期(start_date)是遙遠的西元 2100 年 1 月 1 號:
default_args = {
'owner': 'Meng Lee',
'start_date': datetime(2100, 1, 1, 0, 0),
'schedule_interval': '@daily',
...
with DAG('comic_app_v2', default_args=default_args) as dag:
...
作者目前撰寫這段落的日期為西元 2018 年 8 月 20 號,所以大概還要再等 82 年,而且我啟動的 Airflow 排程器還活著,這個 DAG 才會被第一次執行。我們可等不了那麼久。
在完全地理解上一章執行日期:排程最重要的概念所提到的概念以後,你可能會說:
- 「那我們可以把 start_date 設為 2018 年 8 月 20 號,並維持 schedule_interval 為一天,這樣等到 8 月 21 號 0 點的時候,這個 DAG 就會被執行,然後我們就知道它 work 不 work 了!」
好傢伙(好姑娘?),我給你 100 分!
這句話已經抓到 Airflow 排程的精髓中的精髓,只不過別誤會,我趕時間。何不讓我們當個時空旅人,將 start_date 設為 8 月 20 號以前的日期,比方說 8 月 17 號?
畢竟我們在上一章提到:
一個 DAG Run 中的執行日期,只等於它「負責」的日期,不等於它實際被 Airflow 排程器執行的日期。
將 start_date 設為今天(8 月 20 號)以前的日期,並啟動 Airflow 排程器的話,就會讓 Airflow 排程器馬上開始排程執行日期為 start_date 的 DAG Run,並且一直執行到最新的 DAG Run 為止。

所以現在讓我修改 comic_app_v2 DAG 的程式碼以排程「過去」的 DAG Run:
default_args = {
'owner': 'Meng Lee',
'start_date': datetime(2018, 8, 17, 0, 0),
'schedule_interval': '@daily',
...
with DAG('comic_app_v2', default_args=default_args) as dag:
...
保持好習慣,修改完程式碼以後用 Python 確認 DAG 沒語法錯誤:
python dags/comic_app_v2.py
通常 Airflow 沒多久就會重新載入最新的程式碼。如果你懷疑程式碼沒有被更新,可以點擊 Airflow UI 首頁中 comic_app_v2 DAG 最右邊 Links 裡頭的「Refresh」按鈕。
問題時間。
將 comic_app_v2 DAG 的 start_date 設定成 2018 年 8 月 17 號以後,在作者撰文的 8 月 20 號晚間 10 點為止, Airflow 會排程幾次 DAG Runs?它們分別的執行日期為何?花個幾秒鐘思考,確定你知道答案。(schedule_interval 一樣為 @daily )

答案揭曉,Airflow 排程器總共排程三個 DAG Runs,他們的執行日期分別為:
- 2018-08-17
- 2018-08-18
- 2018-08-19
8 月 20 號的 DAG Run 則要等到 8 月 21 號 0 點才會被執行。
喝杯水重新載入 UI,我們可以從 Airflow UI 裡頭確認 comic_app_v2 DAG 總共有 4 個成功的 DAG Runs:
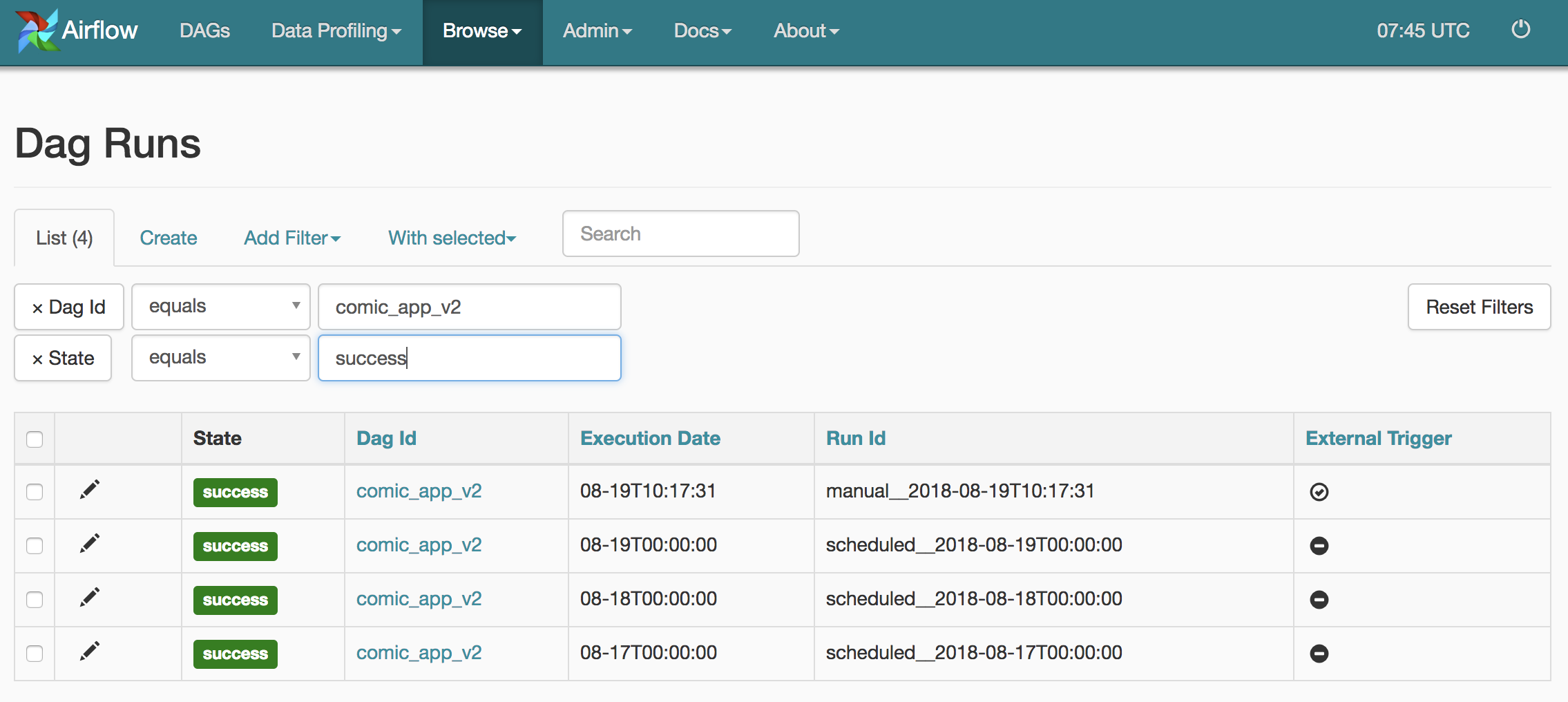
除了第一個 DAG Run 是我們之前手動觸發以外(你可以從它的 Run Id 以及最右邊的 External Trigger 看出),其他三個都是 Airflow 排程器實際排程並執行的結果(一樣你可以從它們的 Run Id 看出端倪)。
同時我的 Slack 作響。我們可以看到儘管執行日期相異,三個被排程的 DAG Runs 按照順序通知我有新番。
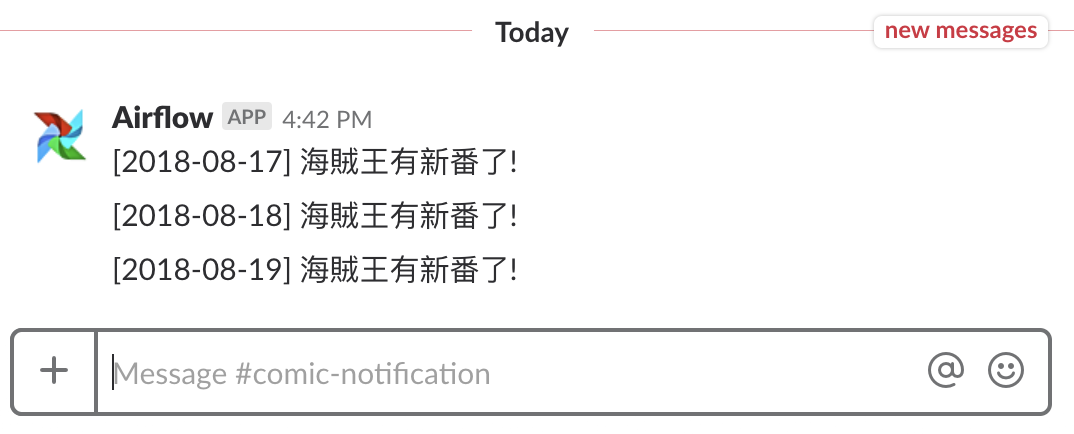
嗯 .. 海賊王一週出一次,想必其中有幾個是 fake news。
不管如何,我們在這章節成功讓 Airflow 排程器從好幾天前開始自動排程 comic_app_v2 DAG 並確認結果成功!
如果我不將 Airflow 排程器關掉的話,之後每天的 0 點(UTC)它都會幫我執行 comic_app_v2 DAG。沒有意外的話,或許 Airflow 排程器可以幫我們持續排程此 DAG 到西元 2100 年,希望到時海賊王已經完結,不用叫孫子燒給我了。
App 版本三:填填樂¶
目前為止,本文為了讓你能專注在理解 Airflow 及工作流程的核心概念(而非個別工作的實作細節),以 print() 代替我們 App 的實作邏輯。
在此章節,我們則會一窺實作所有邏輯的 comic_app_v3 DAG,也就是實現本文開頭展示的 App 的程式碼。
但為何說「一窺」呢?
因為 comic_app_v3 DAG 為了處理 JSON 檔案、利用 Selenium 存取網頁等事情,其程式碼變得比只用 print() 的 comic_app_v2 DAG 要長得多,且其程式碼很大一部份已經不直接跟 Airflow 相關了。
我相信大部分的讀者是為了學習 Airflow 而來,而不是看我東 try 西 try 來實作這個 App。當然,如果你有興趣且想要練習如何建立一個自己的漫畫連載 App,你可以嘗試將實作邏輯填入到 comic_app_v2 DAG 裡頭的各個 Python 函式即可,或者直接執行我已經實作好所有邏輯的 comic_app_v3 DAG,這個我們在後面的如何建立你自己的連載通知 App(懶人法)章節會有詳細講解。
在這章節,我想跟你分享一些在實作 comic_app_v3 DAG 時用到的 Airflow 知識及技巧。
重複利用 Python 函式¶
在 App 版本二:模組化章節我們看到,大部分的 Airflow 工作都是由一個 PythonOperator 所定義,而每個 PythonOperator 分別呼叫不同的 Python 函式。但在 comic_app_v3 DAG 裡頭,我們只利用一個 Python 函式 process_metadata 專門負責讀 / 寫使用者的閱讀紀錄:
def process_metadata(mode, **context):
if mode == 'read':
...
elif mode == 'write':
...
with DAG('comic_app_v3', default_args=default_args) as dag:
get_read_history = PythonOperator(
task_id='get_read_history',
python_callable=process_metadata,
op_args=['read'],
provide_context=True
)
...
update_read_history = PythonOperator(
task_id='update_read_history',
python_callable=process_metadata,
op_args=['write'],
provide_context=True
)
你會發現上面兩個 Airflow 工作的 python_callable 都呼叫 process_metadata,因為它們做類似的事情:
get_read_history負責讀取閱讀紀錄update_read_history負責更新閱讀紀錄
而這兩個工作則利用不同的 op_args 來使用 process_metadata 函式的不同功能。這樣的好處是我們不需要為每個類似的 PythonOperator 都分別建立一個新的 Python 函式,而是利用參數 op_args 來改變同個 Python 函式的執行結果。
當然,傳遞參數給 Python 函式這件事情本身就是很常見,這時候 op_args 就會派上用場。
Xcom:工作之間的訊息交換¶
Xcom(Cross Communication) 是 Airflow 工作之間交換訊息的方式。一個被 PythonOperator 呼叫的 Python 函式所回傳(return)的值,都可以被其他 Airflow 工作透過 Xcom 存取:
def check_comic_info(**context):
print("檢查有無新連載")
...
return anything_new, all_comic_info
def decide_what_to_do(**context):
anything_new, all_comic_info = context['task_instance'].xcom_pull(task_ids='check_comic_info')
print("跟紀錄比較,有沒有新連載?")
if anything_new:
return 'yes_generate_notification'
else:
return 'no_do_nothing'
...
with DAG('comic_app_v3', ...
...
check_comic_info = PythonOperator(
task_id='check_comic_info',
python_callable=check_comic_info,
provide_context=True
)
你可以看到最底下的 check_comic_info 工作呼叫上方的 check_comic_info 函式,而該函式回傳 anything_new, all_comic_info。
接著 decide_what_to_do 函式則利用以下語法來取得該結果:
anything_new, all_comic_info = context['task_instance'].xcom_pull(task_ids='check_comic_info')
下游工作可以透過這樣的方式取得上游工作的執行結果,來決定接下來要做的任務。
值得注意的是 XCom 的所有資料在 pickle 之後會被存到 Airflow 的 Metadata Database(通常是 MySQL)裡頭,因此不適合交換太大的數據(例:100 萬行的 Pandas DataFrame),而適合用在交換 Metadata。
def check_comic_info(**context):
...
裡頭的 **context 的語法是為了取得 Airflow 在執行工作時產生的環境變數,其中就包含 XCom。除了要在 Python 函式設置 **context 以外,我們還必須將 PythonOperator 的 provide_context 參數設置為 True,Airflow 才會把環境變數傳給該工作:
check_comic_info = PythonOperator(
task_id='check_comic_info',
python_callable=check_comic_info,
provide_context=True
)
圖中的 check_comic_info 「上游」工作會去漫畫網頁檢查有沒有新的連載,依照結果的不同,我們希望不同分支被執行:
- 如果有的話,執行上面分支的
yes_generate_notification「下游」工作 - 沒有的話,則執行下面分支的
no_do_nothing「下游」工作
要在 Airflow 裡頭實現這樣的邏輯,可以在上下游工作「之間」新增一個 BranchPythonOperater(如圖中的 new_comic_available 工作):
- 砍掉原上游工作跟下游工作之間的
>> - 將原上游工作
>>該BranchPythonOperator工作 - 將該
BranchPythonOperator工作>>原下游工作
資料工程很大一部份的工作就是在建立資料管道/工作流程,接個水管合情合理對吧?
from airflow.operators.python_operator BranchPythonOperator
def decide_what_to_do(**context):
anything_new, all_comic_info = context['task_instance'].xcom_pull(task_ids='check_comic_info')
print("跟紀錄比較,有沒有新連載?")
if anything_new:
return 'yes_generate_notification'
else:
return 'no_do_nothing'
...
with DAG('comic_app_v3', default_args=default_args) as dag:
...
decide_what_to_do = BranchPythonOperator(
task_id='new_comic_available',
python_callable=decide_what_to_do,
provide_context=True
)
generate_notification = PythonOperator(...)
do_nothing = DummyOperator(task_id='no_do_nothing')
decide_what_to_do >> generate_notification
decide_what_to_do >> do_nothing
而 BranchPythonOperator 一樣會呼叫一個 Python 函式(上例的 decide_what_to_do 函式),由該函式決定到底最後哪個下游工作會被執行。基本上該函式會依照實際情況決定哪個下游工作被執行,並將該下游工作的 task_id 回傳。
而因為在這個例子中,我們希望依照上游工作 check_comic_info 回傳的一個布林值 anything_new 來決定要執行哪個下游工作,因此可以使用 xcom_pull 取得該結果以後回傳要執行的下游工作 ID task_id。
好啦,這就是我想跟你分享在實作 comic_app_v3 DAG 時的幾個實用技巧,希望對你上手 Airflow 有所幫助。
接下來我們將針對那些想要建立自己的連載通知 App 的你,提供一個快速起手指南。
不過如果你現在沒有打算做這件事情的話,可以放心跳到最後面的結語。
如何建立你自己的連載通知 App(懶人法)¶
此章節提供一個懶人指南,讓那些想要建立自己的 App 的你,在(幾乎)不需要改變 comic_app_v3 程式碼的前提下完成這件事情。
如同我們在建置 Airflow 環境提到的,首先你當然得先把跟這篇文章相關的 Github Repo 複製下來:
git clone https://github.com/leemengtaiwan/airflow-tutorials.git
cd airflow-tutorials
如果你在之前就有複製 Repo 下來跟著走,你只需要再另外安裝 Selenium。Selenium 是一個自動化網頁測試的工具,在這個 App 裡頭被我們用來當網路爬蟲,去漫畫網站看連載資訊。
接著啟動目前為止 Airflow 一直在使用的 Anaconda 環境,然後安裝 Selenium:
source activate airflow-tutorials
conda install -c conda-forge selenium
如果你之前沒有建置任何環境,可以利用 Repo 裡頭的 environment.yaml 從頭安裝 Airflow 以及 Selenium:
conda env create -n airflow-tutorials -f environment.yaml
source activate airflow-tutorials
在這個 App 裡頭,要讓 Selenium 正常運作,你還需要 Chrome Driver。下載最新版本以後把它放在你的 $PATH 讀得到的地方。Mac 使用者的話可以放到像是 /usr/local/bin 資料夾下面。如果還是不懂可以查看這裡的 Chrome Driver 安裝教學。
環境設定好以後,你會需要一個新的 Slack App 來送訊息到你的 Workspace。建立一個新的 Slack App,給予它寫訊息的權限以後,安裝到你自己的 Workspace。這時候你應該會得到一個開頭為 xoxp- 的 Slack Token。將該 Token 複製下來,打開 airflow-tutorials 資料夾底下的 data/credentials/slack.json。
將你的 Token 複製貼上如:
{
"token": "xoxp-....."
}
搞定網路爬蟲以及 Slack 認證以後,你需要改變 comic_app_v3.py 裡頭的一行程式碼,以讓 Airflow 送訊息到你 Workspace 底下指定的頻道(channel):
send_notification = SlackAPIPostOperator(
task_id='send_notification',
token=get_token(),
channel='#comic-notification',
text=get_message_text(),
icon_url='http://airbnb.io/img/projects/airflow3.png'
)
將上述的 channel='#comic-notification' 改成你自己的頻道,如 channel='#my-new-channel'。
接著你會需要一個正常運作的 Airflow 排程器。啟動方法參考 Airflow 排程器章節。
在 Airflow 排程器、Selenium 以及 Slack 都就緒以後,你可以直接手動觸發 comic_app_v3 DAG 來測試 App 的第一則訊息。如同我們在手動觸發 DAG 章節提到的,你可以透過 Web UI 或者 terminal 來終止暫停(Unpause)並手動觸發一個 DAG:
airflow unpause comic_app_v3
airflow trigger_dag comic_app_v3
一切順利的話,幾秒鐘之後,你會在自己的 Slack Workspace 及 channel 底下收到這個測試訊息:
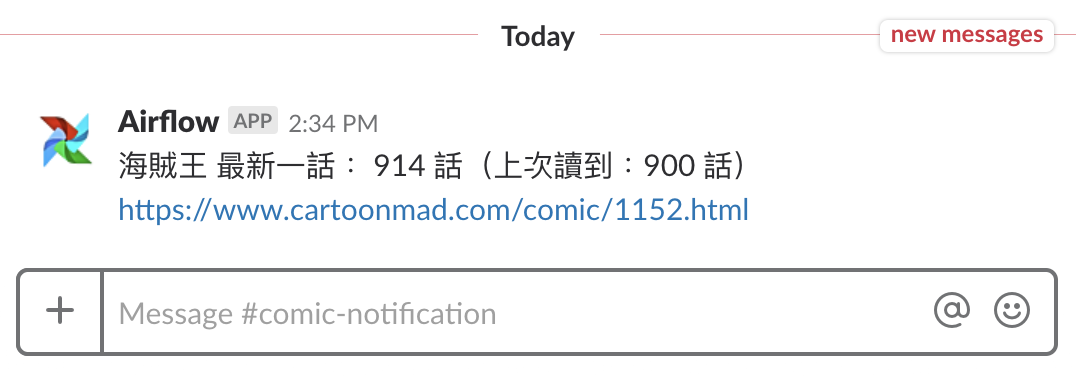
目前 comic_app_v3 DAG 將使用者的閱讀紀錄儲存在 data/comic.json 裡頭,底下則是為了產生上面這個 Slack 訊息的假閱讀紀錄:
{
"1152": {
"name": "海賊王",
"previous_chapter_num": 900
}
}
目前此 App 只能從動漫狂(歡迎你丟 PR 改善!)找最新的漫畫連載。為了新增你自己的漫畫,你需要找出該漫畫主頁在動漫狂的連結,將連結中的數字如上述的例子一樣新增在 data/comic.json 裡頭。假設你想開始關注「進擊的巨人」,然後最近看到 100 話的話,可以把 data/comic.json 改成這樣:
{
"1221": {
"name": "進擊的巨人",
"previous_chapter_num": 100,
}
}
這樣一來, comic_app_v3 DAG 就會用該數字去「進擊的巨人」的頁面,幫你查看有沒有最新的連載。當然你也可以像我一樣,在 comic.json 裡追加多個漫畫:
{
"1152": {
"name": "海賊王",
"previous_chapter_num": 911
},
"1221": {
"name": "進擊的巨人",
"previous_chapter_num": 107
},
"4485": {
"name": "西遊",
"previous_chapter_num": 152
},
"1121": {
"name": "浪人劍客",
"previous_chapter_num": 327
},
"1122": {
"name": "王者天下",
"previous_chapter_num": 565
}
...
}
修改完 comic.json,最後你會想要修改 comic_app_v3.py 裡頭的排程設定:
default_args = {
'owner': 'Meng Lee',
'start_date': datetime(2100, 1, 1, 0, 0),
'schedule_interval': '@daily',
'retries': 2,
'retry_delay': timedelta(minutes=1)
}
將 start_date 改成你想要他它開始的日期,接著 Airflow 排程器就會每天幫你執行 comic_app_v3 DAG 並查看最新連載。搞定收工!
結語¶
首先,由衷感謝你花了那麼多寶貴時間與力氣跟隨著我們的 Airflow 冒險。
回顧一下,這一路上你已經學會不少資料工程相關的知識以及 Airflow 的開發技巧:
- 了解工作流程、上下游工作、相依性的概念以及其與 Airflow DAG 的關係
- 模組化工作流程的重要性
- 了解如何利用
PythonOperator建立一個 Airflow 工作並呼叫自定義 Python 函式 - 利用
airflow test指令以及 Web UI 測試 Airflow 工作以及 DAG - 了解如何利用 Python 定義一個工作流程以及決定工作間的相依性
- 利用 Web UI 及 terminal 手動觸發 DAG 並確認執行結果
- 了解 Airflow 排程概念(如執行日期)並實際讓工作流程上線(
comic_app_v2) - 了解一些 Airflow 開發時的技巧,如建立條件分支以及使用各種不同的 Operators 建立工作
先給自己鼓個掌吧!
如同我在文章開頭所述:
這是一篇當初我在入門資料工程以及 Airflow 時希望有人能為我寫好的文章。
當時的我找不到這篇文章,而現在我自己寫了這篇文章。
希望這篇文章能幫助到跟過去的我一樣,正在嘗試學習資料工程以及 Airflow 的你。
雖然使用 Airflow 來實作本篇的漫畫連載 App 可能是一個殺雞用牛刀的例子,但我希望你能參考本文的 App 例子,開始思考如何用本文學到的知識,去實際解決、自動化你自身或是所在企業的數據問題。
儘管這篇的 Airflow 故事即將進入尾聲,你的 Airflow 之旅才剛剛展開。
Keep learning and happy Airflowing!
跟資料科學相關的最新文章直接送到家。 只要加入訂閱名單,當新文章出爐時, 你將能馬上收到通知