監控資本主義時代下的資料科學、AI 與你我的數位未來
這是一篇講述監控資本主義的驚悚輕小說與科普文。處在數位時代的每個人都需要了解谷歌、臉書與推特等科技巨頭如何形塑我們的數位現實以及其背後運作的商業邏輯與經濟誘因。文中也會清晰地呈現資料科學與監控資本主義之間的緊密關係。閱讀完本文的讀者將能重新找回數位時代中最重要的注意力並專注在真正重要的事情。
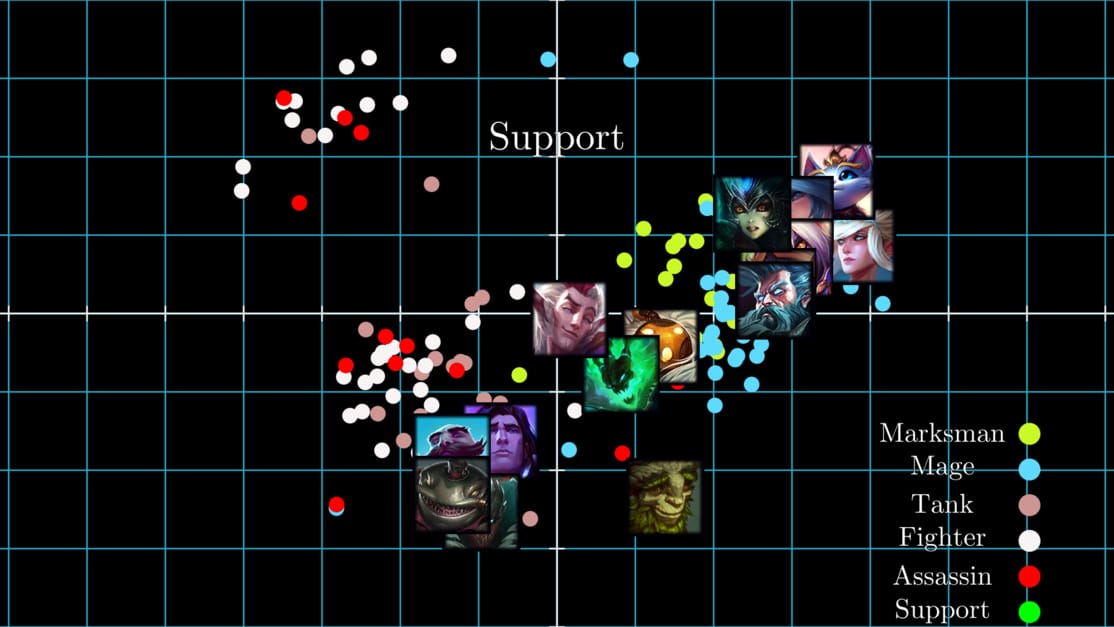
這篇文章用世上最生動且實務的方式帶你直觀理解機器學習領域中十分知名且強大的線性降維技巧:主成分分析 PCA。我們將重新回顧你所學過的重要線性代數概念,並實際應用這些概念將數據有效地降維並去除特徵間的關聯。你也將學會如何使用 NumPy 和 scikit-learn 等 Python 函式庫自己實作 PCA。文中也分享使用 PCA 分析線上遊戲《英雄聯盟》公開數據的有趣案例。
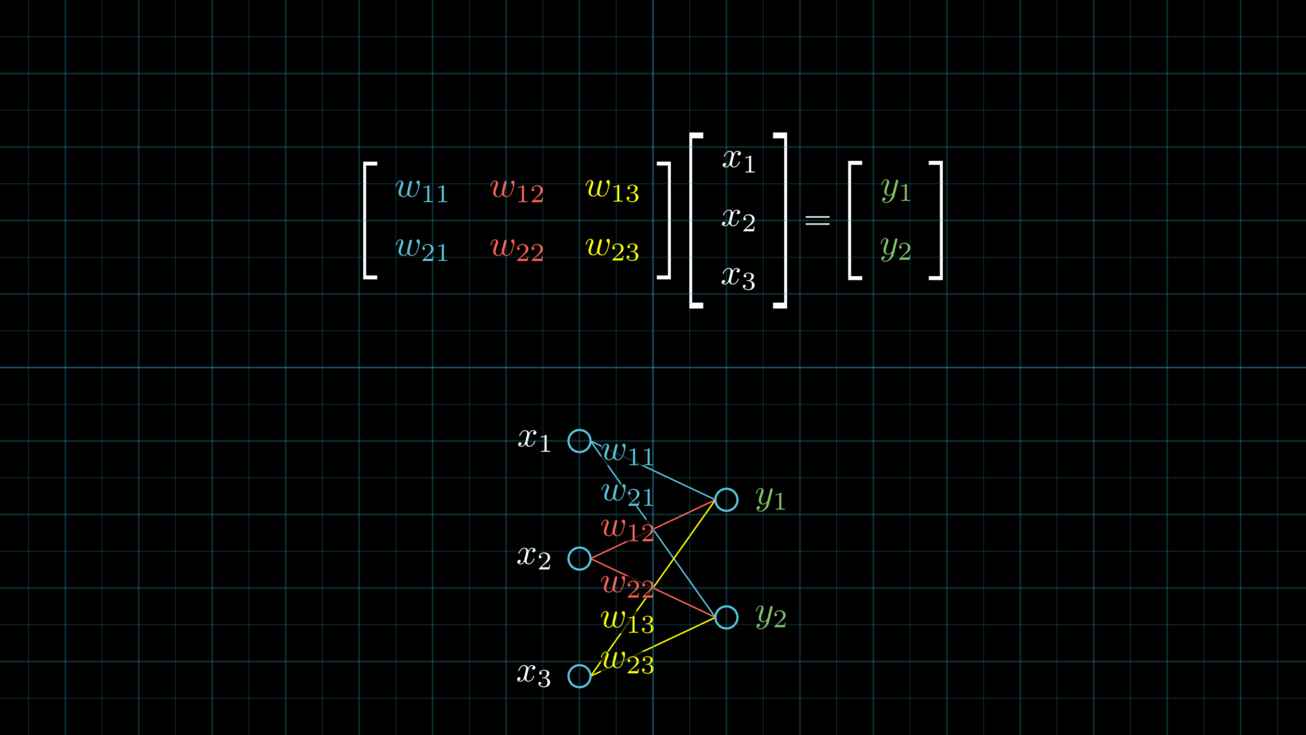
這是篇透過大量動畫幫助你直觀理解神經網路的科普文。我們將介紹基礎的神經網路與線性代數概念,以及兩者之間的緊密關係。我們也將實際透過神經網路解決二元分類任務,了解神經網路的運作原理。讀完本文,你將能夠深刻地體會神經網路與線性代數之間的緊密關係,奠定 AI 之旅的基礎。

這篇文章將簡單向讀者介紹 OpenAI 的知名語言模型 GPT-2,並展示能夠生成金庸小說的 GPT-2 模型。文中也將透過視覺化工具 BertViz 來帶讀者直觀了解基於 Transformer 架構的 NLP 模型背後的自注意力機制。讀者也能透過文中提供的 GPT-2 模型及 Colab 筆記本自行生成全新的金庸橋段。

熟練地使用 pandas 是資料科學家處理數據與分析時不可或缺的重要技能之一。透過 40 個 pandas 實用技巧,這篇文章將帶你由淺入深地掌握最基礎且重要的 pandas 能力。文中也將介紹多個適合與 pandas 一起使用的強大函式庫,提升你的數據處理能力。

這篇是給所有人的 BERT 科普文以及操作入門手冊。文中將簡單介紹知名的語言代表模型 BERT 以及如何用其實現兩階段的遷移學習。讀者將有機會透過 PyTorch 的程式碼來直觀理解 BERT 的運作方式並實際 fine tune 一個真實存在的假新聞分類任務。閱讀完本文的讀者將能把 BERT 與遷移學習運用到其他自己感興趣的 NLP 任務。

本文分為兩大部分。前半將帶讀者簡單回顧 Seq2Seq 模型、自注意力機制以及 Transformer 等近年在機器翻譯領域裡頭的重要發展與概念;後半段則將帶著讀者實作一個可以將英文句子翻譯成中文的 Transformer。透過瞭解其背後運作原理,讀者將能把類似的概念應用到如圖像描述、閱讀理解以及語音辨識等各式各樣的機器學習任務之上。
本文展示 3 種可以讓你馬上運用 CartoonGAN 來生成動漫的方法。其中包含了我們的 Github 專案、TensorFlow.js 應用以及一個事先為你準備好的 Colab 筆記本。有興趣的同學還可學習如何利用 TensorFlow 2.0 來訓練自己的專屬 CartoonGAN。

這篇文章展示一個由 TensorFlow 2.0 以及 TensorFlow.js 實現的文本生成應用。本文也會透過深度學習專案常見的 7 個步驟,帶領讀者一步步了解如何實現一個這樣的應用。閱讀完本文,你將對開發 AI 應用的流程有些基礎的了解。

AI For Everyone 是由吳恩達教授開授的一堂線上課程,這篇文章則記錄了我個人在修習完這堂線上課程後整理出的 10 個最重要 AI 概念。除了將這些概念條列出來以外,本文也將逐一介紹每個概念所代表的涵意,幫助讀者快速掌握該課程裡頭的重要 AI 概念,並開始自己的 AI 之旅。

這裡紀錄了我在學習深度學習時蒐集的一些線上資源。內容由淺入深,而且會一直被更新,希望能幫助你順利地開始學習:)