這是一篇以「介紹 GPT-2」之名,行「推坑金庸」之實的自然語言處理文章。
嗨,會點擊進來,我想你應該至少看過武俠小說泰斗金庸的一部著作吧!
這篇文章將簡單介紹 OpenAI 在今年提出的知名語言模型 GPT-2,並展示一個能夠用來生成金庸風格文本的小型 GPT-2。在讀完本文之後,你也能使用我的 Colab 筆記本來生成屬於你自己的金庸小說。文中也將透過視覺化工具 BertViz 讓你能夠直觀地感受 GPT-2 等基於 Transformer 架構的 NLP 模型如何利用注意力機制(Attention Mechanism)來生成文本。
如果你想要直觀地了解自然語言處理(Natural Language Processing, NLP)以及深度學習可以如何被用來生成金庸小說,這篇應該很適合你。
前置知識¶
如果你已讀過我寫的幾篇 NLP 文章,我相信你可以非常輕鬆地理解本文提及的 GPT-2 概念:
- 進入 NLP 世界的最佳橋樑:寫給所有人的自然語言處理與深度學習入門指南
- 讓 AI 寫點金庸:如何用 TensorFlow 2.0 及 TensorFlow.js 寫天龍八部
- 淺談神經機器翻譯 & 用 Transformer 與 TensorFlow 2 英翻中
- 進擊的 BERT:NLP 界的巨人之力與遷移學習
基本上排越後面越進階。別擔心,我還是會用最平易近人的方式介紹 GPT-2!但你之後可能會想要回來參考這些文章。不管如何,現在先讓我們開始這趟 GPT-2 之旅吧!
先睹為快:看看 GPT-2 生成的金庸橋段¶
首先,你可以把本文想成是如何用 TensorFlow 2 及 TensorFlow.js 寫天龍八部的升級版本(是的,我太愛金庸所以要寫第兩篇文章)。本文跟該篇文章的最大差異在於:
- 模型升級:當初我們使用輕量的長短期記憶 LSTM 作為語言模型,這篇則使用更新、更強大的 GPT-2
- 數據增加:當初我們只讓 LSTM「閱讀」一本《天龍八部》,這篇則用了整整 14 部金庸武俠小說來訓練 GPT-2
- 強調概念:當初我們用 TensorFlow 一步步實作 LSTM,這篇則會專注在 GPT-2 的運作原理並額外提供 Colab 筆記本供你之後自己生成文本以及視覺化結果

飛雪連天射白鹿,笑書神俠倚碧鴛。
─ 金庸作品首字詩
從《飛狐外傳》、《倚天屠龍記》、《笑傲江湖》到《鴛鴦刀》,這 14 部經典的金庸著作你讀過幾本呢?哪一本是你的最愛呢?還記得多少橋段呢?
在實際介紹 GPT-2 之前,讓我們先看看將這些作品讀過上百遍的 GPT-2 會生成出怎麼樣的橋段。你可以從底下的這些生成例子感受一下 GPT-2 的語言能力以及腦補技巧:














沒錯,很ㄎㄧㄤ!但這些文本不是我自己吸麻瞎掰出來的。(事實上,GPT-2 比我厲害多了)在用 14 部金庸武俠小說訓練完 GPT-2 之後,我從這些小說中隨意抽取一段文字作為前文脈絡,接著就讓它自己腦補後續橋段。你可以從左上角得知模型是在生成哪部武俠小說。
這些文本當然不完美,但跟我們當初用 LSTM 生成《天龍八部》的結果相比,已有不少進步:
- 生成的文本更加通順、語法也顯得更為自然
- 記憶能力好,能夠持續生成跟前文相關的文章而不亂跳人物
值得一提的是,如果你讀過《天龍八部》,就會知道第一個例子的前文脈絡(context)是段譽與王語嫣墜入井內最終兩情相悅的橋段。儘管每次生成的結果會因為隨機抽樣而有所不同,GPT-2 在看了這段前文後為我們生成了一本超級放閃的言情小說,儘管放閃的兩人貌似跟我們預期地不太一樣。且在該平行時空底下,貌似慕容復也到了井裡(笑
你可以跟當初 LSTM 的生成結果比較,感受 GPT-2 進步了多少:

雖然很有金庸架勢,細看會發現 LSTM 的用詞不太自然(比如說 四具屍體匆匆忙逼、伸掌在膝頭褲子)。且明明前文脈絡提到的是段譽與王語嫣,LSTM 開頭馬上出現不相干的南海鱷神、接著跳到虛竹、然後又扯到蕭峰 ...
無庸置疑,LSTM 是你在 NLP 路上必學的重要神經網路。不過很明顯地,跟當初用詞不順且不斷跳 tune 的 LSTM 相比,新的 GPT-2 的生成結果穩定且流暢許多(當然,訓練文本及參數量的差異不小)。在看過生成結果以後,讓我們看看 GPT-2 實際上是個怎麼樣的語言模型。
GPT-2:基於 Transformer 的巨大語言模型¶
GPT-2 的前身是 GPT,其全名為 Generative Pre-Training。在 GPT-2 的論文裡頭,作者們首先從網路上爬了將近 40 GB,名為 WebText(開源版) 的文本數據,並用此龐大文本訓練了數個以 Transformer 架構為基底的語言模型(language model),讓這些模型在讀進一段文本之後,能夠預測下一個字(word)。

如今無人不知、無人不曉的神經網路架構 Transformer 在 2017 年由至今已超過 3,000 次引用的論文 Attention Is All You Need 提出,是一個不使用循環神經網路、卷積神經網路並完全仰賴注意力機制的 Encoder-Decoder 模型。在前置知識一節提過的神經機器翻譯 & Transformer一文裡已經用了大量動畫帶你理解並實作自注意力機制及 Transformer,這邊就不再贅述了。
基本上只要了解 Transformer 架構,你馬上就懂 GPT-2 了。因為該語言模型的本體事實上就是 Transformer 裡的 Decoder:
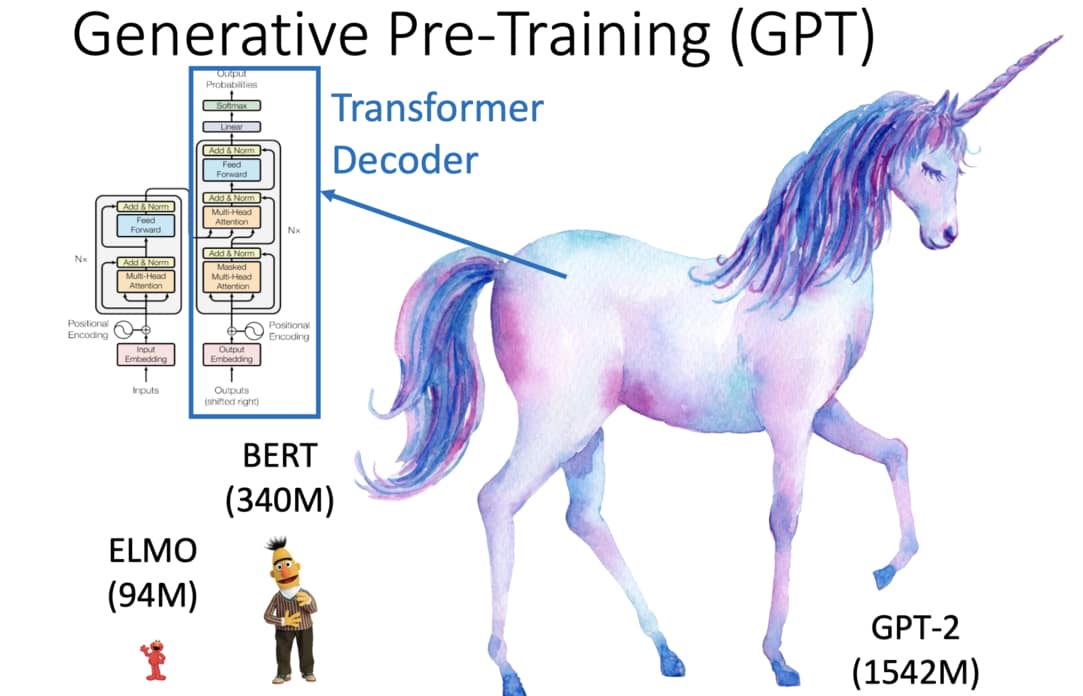
更精準地說,GPT-2 使用的 Transformer Decoder 是原始 Transformer 論文的小變形(比方說沒有了關注 Encoder 的 Decoder-Encoder Attention Layer),但序列生成(Sequence Generation)的概念是完全相同的。
架構本身沒什麼特別。但 GPT-2 之所以出名,是因為它訓練模型時所使用的數據以及參數量都是前所未有地龐大:
- 訓練數據:使用從 800 萬個網頁爬來的 40 GB 高品質文本。把金庸 14 部著作全部串起來也不過 50 MB。WebText 的數據量是金庸著作的 800 倍。想像一下光是要看完這 14 部著作一遍所需花費的時間就好。
- 模型參數:15 億參數,是已經相當巨大、擁有 3.4 億參數的 BERT-Large 語言代表模型的 4.5 倍之多。BERT-Large 使用了 24 層 Transformer blocks,GPT-2 則使用了 48 層。
這可是有史以來最多參數的語言模型。而 GPT-2 獨角獸(unicorn)的形象則是因為當初作者在論文裡生成文本時,給了 GPT-2 一段關於「住在安地斯山脈,且會說英文的一群獨角獸」作為前文脈絡,而 GPT-2 接著生成的結果有模有樣、頭頭是道,讓許多人都驚呆了:

你可以前往在由淺入深的深度學習資源整理就已經介紹過的 Talk to Transformer 生成上例的獨角獸文章、復仇者聯盟劇本或是任何其他類型的英文文章。
我懂,對非英文母語的我們來說,其實很難深切地感受 GPT-2 生成的文章到底有多厲害。這也是為何我決定要使用金庸小說來訓練一個中文模型並介紹 GPT-2,因為這樣你比較能夠實際感受並了解模型生成的文本。官方釋出的 GPT-2 能夠輸出中文字,但因為大部分文本都是透過 Reddit 爬下來的英文文章,因此是沒有辦法做到如同本文的中文生成的。
讓 GPT-2 在社群上被熱烈討論的另個原因是作者等人當初在部落格上展示驚人的生成結果後表示:
因為顧慮到這項技術可能會遭到惡意運用,我們目前並不打算釋出已訓練好的模型。但為了促進研究我們將釋出規模小很多的模型供研究者參考。
─ OpenAI, 2019/02
此言一出,一片譁然。看看隔壁棚幾乎可以說是以開源為志向的 Google BERT!網路上有人甚至嘲諷 OpenAI 一點都不 open,而是 CloseAI;也有人說 OpenAI 只是為了炒話題,GPT-2 並沒有那麼厲害;當然也有人認為作者們的論文已經有足夠的學術貢獻,並非一定得釋出模型。
不過至少目前看來 OpenAI 只是採取相對謹慎的態度在釋出模型。該團隊在今年 2 月將最小的 124M GPT-2 Small(1.2 億參數)與論文一起釋出,並在 5 月釋出 355M 的 GPT-2 Medium。而就在不久前的 8 月釋出了有 7.74 億參數的 GPT-2 Large,其模型大小是 1558M GPT-2 完全體的一半。
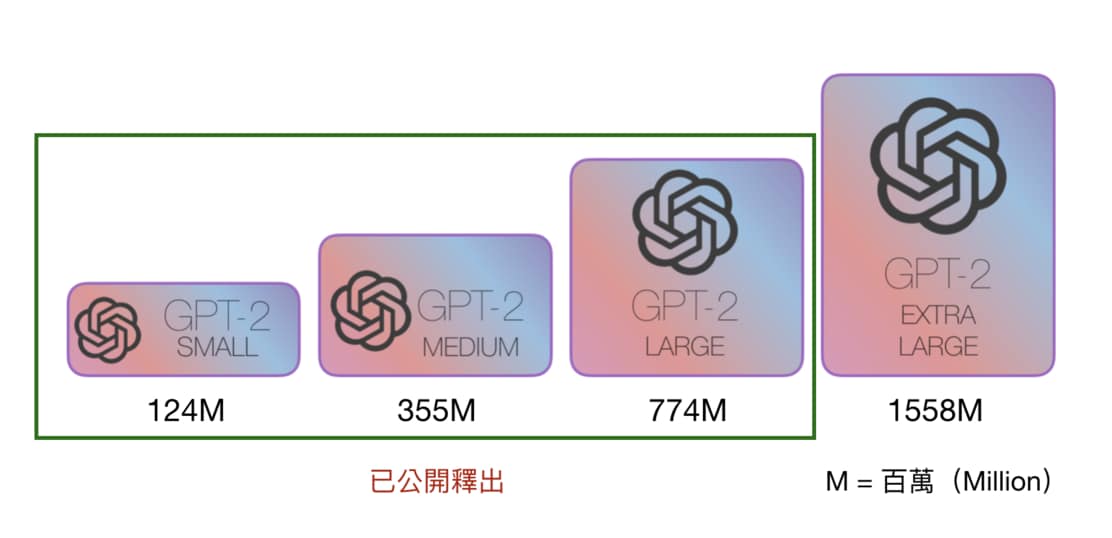
一群人歡欣鼓舞,迫不及待地把玩最新玩具 GPT-2 Large。剛剛提到的 Talk to Transformer 事實上就已經是在使用最新的 GPT-2 Large 了,手腳很快。
其他相關應用多如牛毛。比方說之前介紹過的 This Waifu Does Not Exist 在使用 GAN 生成動漫頭像的同時也利用 GPT-2 隨機生成一段動漫劇情;而 TabNine 則是一個加拿大團隊利用 GPT-2 做智慧 auto-complete 的開發工具,志在讓工程師們減少不必要的打字,甚至推薦更好的寫法:
由強大的深度學習模型驅動,可以想像未來(現在已經是了!)會有更多如 TabNine 的應用影響我們的工作與生活。而這也是為何你最好花點時間 follow 深度學習以及 AI 發展趨勢。當然,你也可以選擇在文末訂閱此部落格,只是我不敢保證文章的更新速度(笑
GPT-2 公布時在多個 language modeling 任務取得 SOTA 結果,因此所有人都在引頸期盼著 OpenAI 將最大、擁有 15 億參數的 GPT-2 模型釋出。而該團隊也表示他們會先觀察人們怎麼使用 774M GPT-2,並持續考慮開源的可能性。

不過別走開!GPT-2 的故事還沒有結束。可別以為 OpenAI 會僅僅滿足於能夠生成獨角獸文章的一個語言模型。
重頭戲現在才要開始。
論文作者:GPT-2 能做的可不只是生成文本¶
要了解 GPT-2,先看其前身 GPT。
我們前面就已經提過,GPT 的全名是 Generative Pre-Training。Generative(生成)指的是上節看到的 language modeling,將爬來的文本餵給 GPT,並要求它預測(生成)下一個字;Pre-Training 則是最近 NLP 界非常流行的兩階段遷移學習的第一階段:無監督式學習(Unsupervised Learning)。相關概念我們在進擊的 BERT:NLP 界的巨人之力與遷移學習就已經非常詳細地探討過了,但為了幫助你理解,讓我很快地再次簡單說明。
近年 NLP 界十分流行的兩階段遷移學習會先蒐集大量文本(無需任何標注數據),並以無監督的方式訓練一個通用 NLP 模型,接著再微調(Fine-tune)該模型以符合特定任務的需求。常見的 NLP 任務有文章分類、自然語言推論、問答以及閱讀理解等等。
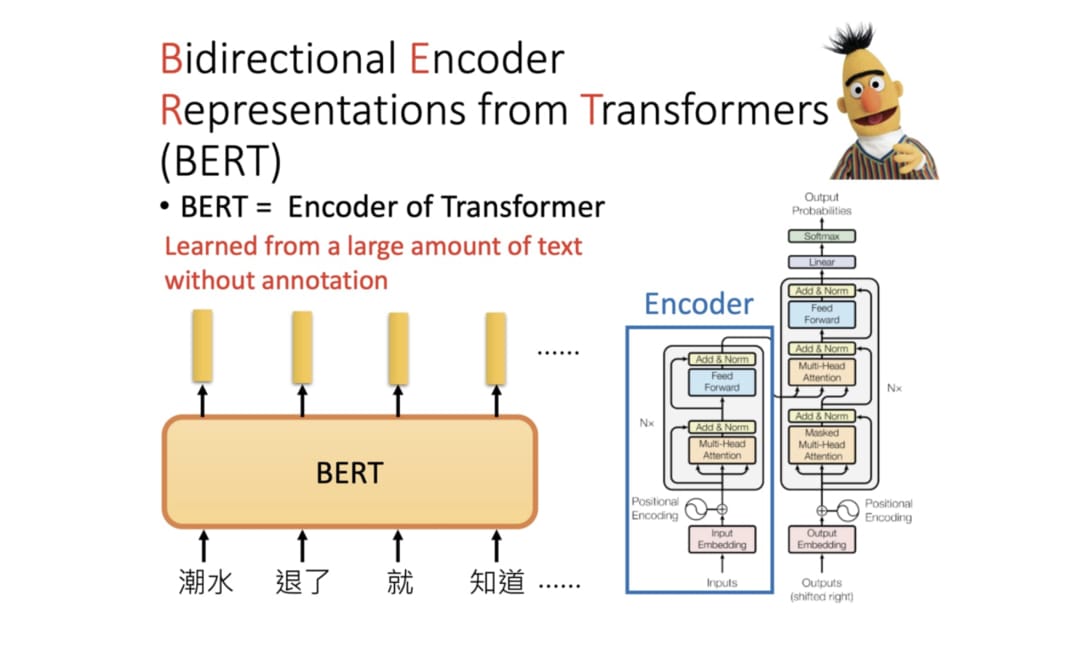
值得一提的是,OpenAI 提出的 GPT 跟 Google 的語言代表模型 BERT 都信奉著兩階段遷移學習:利用大量文本訓練出一個通用、具有高度自然語言理解能力的 NLP 模型。有了一個這樣的通用模型之後,之後就能透過簡單地微調同一個模型來解決各式各樣的 NLP 任務,而無需每次都為不同任務設計特定的神經網路架構,省時省力有效率。
兩者的差別則在於進行無監督式訓練時選用的訓練目標以及使用的模型有所不同:
- GPT 選擇 Transformer 裡的 Decoder,訓練目標為一般的語言模型,預測下個字
- BERT 選擇 Transformer 裡的 Encoder,訓練目標則為克漏字填空以及下句預測
我們這邊不會細談,但基本上不同模型架構適合的訓練目標就會有所不同。不管如何,兩者都使用了 Transformer 架構的一部份。而這主要是因為 Transformer 裡頭的自注意力機制(Self-Attention Mechanism)十分有效且相當適合平行運算。GPT(-2) 的 Transformer Decoder 裡頭疊了很多層 Decoder blocks,以下則是某一層 Decoder block 透過自注意力機制處理一段文字的示意圖:
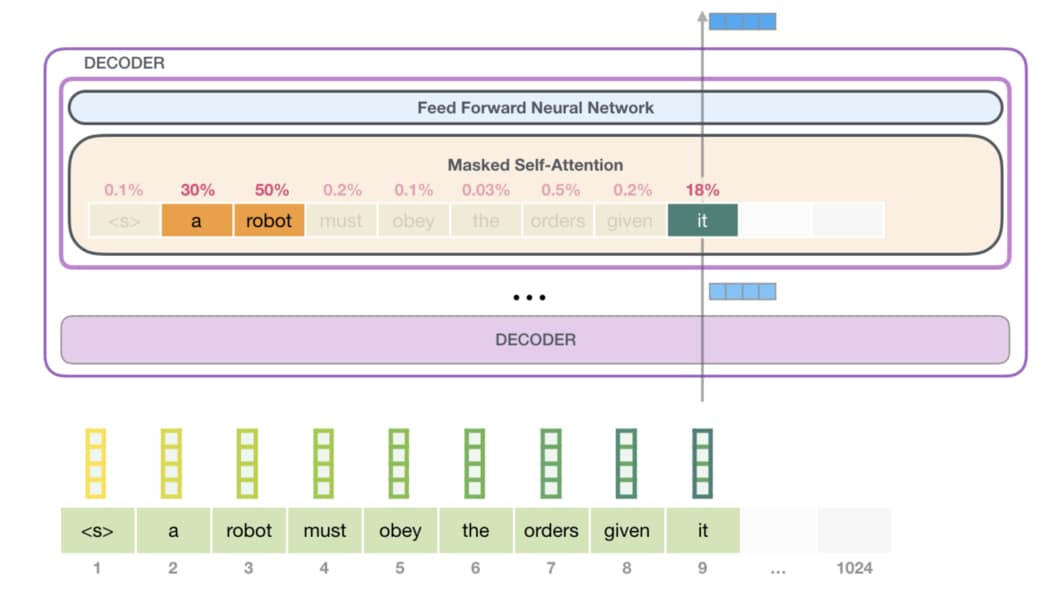
給定一段文本:
<s> a robot must obey the orders given it ...
你可以很輕易地看出 it 指代前面出現過的 robot。而這是因為你懂得去關注(pay attention to)前文並修正當前詞彙 it 的語意。在給定相同句子時,傳統詞嵌入(Word Embeddings)方法是很難做到這件事情的。所幸,透過強大的自注意力機制,我們可以讓模型學會關注上文以決定每個詞彙所代表的語意。
以上例而言,訓練好的 GPT 可以在看到 it 時知道該去關注前面的 a 及 robot,並進而調整 it 在當下代表的意思(即修正該詞彙的 vector representation)。而被融入前文語意的新 representation 就是所謂的 Contextual Word Representation。
我們可以再看一個 BERT 文章裡出現過的自注意力例子:
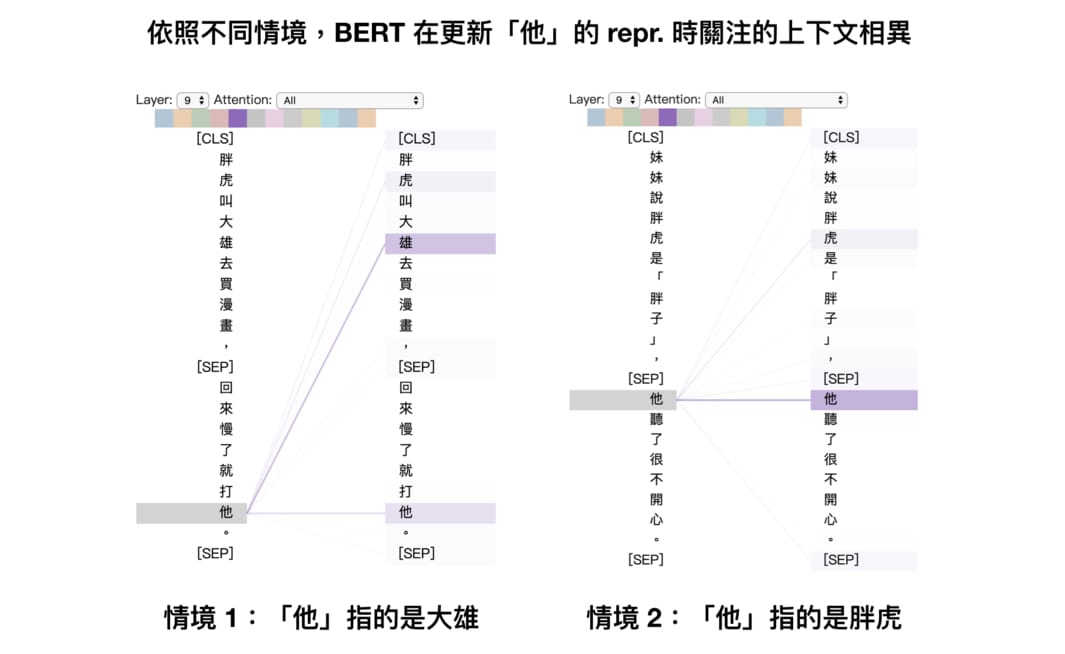
關於自注意力機制(Self-Attention),有個值得記住的重要概念:在 GPT 之後問世的 BERT 是同時關注整個序列來修正一個特定詞彙的 representation,讓該詞彙的 repr. 同時隱含上下文資訊;而 GPT 是一個由左到右的常見語言模型,會額外透過遮罩技巧(Masking)來確保模型只會關注到某詞彙以左的上文資訊。
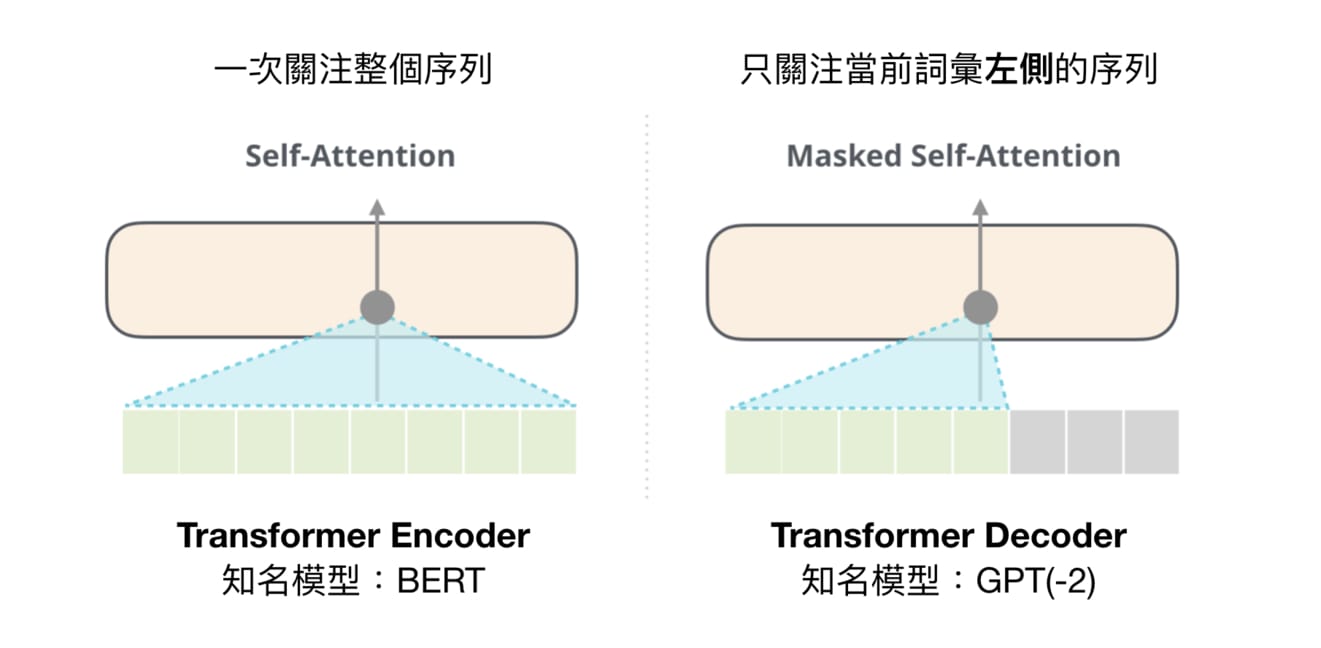
再次提醒,如果你想要深入了解如何實際用 TensorFlow 來實作遮罩,並將左側的自注意力機制變成右側的遮罩版本,可以參考之前的 Transformer 文章。假設你仍無法理解我在胡扯些什麼的話,只要記得:
Transformer 的自注意力機制讓我們可以用更有意義、具備當下語境的方式來表達一段文字裡頭的每個詞彙,進而提升模型的自然語言理解能力。
我在下一節還會用些額外的例子讓你能更直觀地理解這個概念。
了解 GPT 後 GPT-2 就容易了解了,因為 GPT-2 基本上就是 GPT 第二代:一樣是 Transformer Decoder 架構,但使用的數據及模型大小都直接霸氣地乘上 10 倍。有了如此龐大的數據與模型,在做完第一階段的無監督式訓練以後,GPT-2 的作者們決定做些瘋狂的事情:不再遵循兩階段遷移學習,直接做 zero-shot learning!這也就意味著直接把只看過 WebText 的 GPT-2 帶上考場,「裸測」它在多個跟 WebText 無關的 NLP 任務上的表現。而實驗結果如下:

乍看之下你可能會覺得這張圖沒什麼。畢竟就算是最大、最右側的 GPT-2 模型(1542M)在多數特定的 NLP 任務上還是比不過專門為那些任務設計的神經網路架構(比方說閱讀理解的 DrQA + PGNet)。但 GPT-2 的作者們認為他們最大的貢獻在於展現了用大量無標註數據訓練巨大語言模型的潛力:數大就是美!除了摘要(Summarization)任務之外,基本上只要模型參數越大,zero-shot 的結果就越好。
且因為在模型參數越來越大時,訓練 / 測試集的結果仍然都持續進步且表現水準相仿,作者們認為就算是最大的 GPT-2 模型也還 underfit 他們爬的 WebText 數據集,還有進步空間。
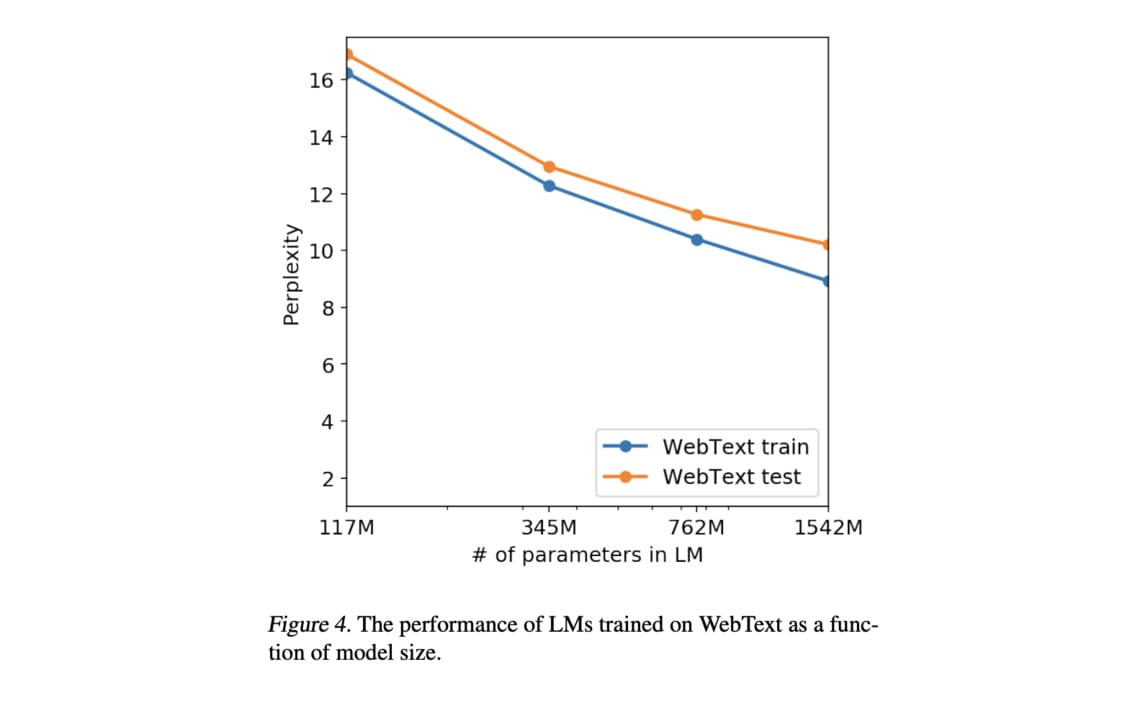
令某些研究者興奮的是,這實驗結果隱含的一個訊息是「或許只要用夠多的文本訓練夠大的語言模型,就能讓該模型在沒有監督的情況下完成更多 NLP 任務」。
總而言之,GPT-2 整篇論文的核心思想可以被這樣總結:
給定越多參數以及越多樣、越大量的文本,無監督訓練一個語言模型或許就可讓該模型具備更強的自然語言理解能力,並在沒有任何監督的情況下開始學會解決不同類型的 NLP 任務。
這個概念用一個簡單但合適的比喻就是「觸類旁通」:GPT-2 在被要求預測 WebText 裡頭各式各樣文章的下一個字時,逐漸掌握理解自然語言的能力,最後就算不經過特別的訓練也能做些簡單的問答、翻譯以及閱讀理解任務。現在回頭看看,你從論文標題:Language Models are Unsupervised Multitask Learners 就能理解當初 GPT-2 作者們想要傳達的想法了。他們也希望這些實驗結果能吸引更多研究者往這個方向發展。當然,不是每個人都有能力與資源做這種龐大模型的研究,且我個人事實上比較喜歡如 DistilBERT 等輕量級模型的研究與應用,之後有時間再撰文分享。
好啦!基本上你現在應該已經掌握 GPT-2 的核心概念與思想了。如果你欲罷不能、想要了解更多,我在最後一節會附上更多相關連結供你參考。在下一節,讓我們再回去看看金庸 GPT-2。
用 BertViz 觀察 GPT-2 生成文本¶
取決於超參數設定,GPT-2 是一個有上千萬、甚至上億參數的語言模型,因此有時你很難理解它裡頭究竟在做些什麼。這節我想花點時間說明如何透過 BertViz 工具來視覺化(visualize)本文的金庸 GPT-2 裡頭的自注意力機制,以加深你對 GPT-2 的理解。
讓我們先比較一下金庸 GPT-2 跟論文裡 4 個模型的差距:
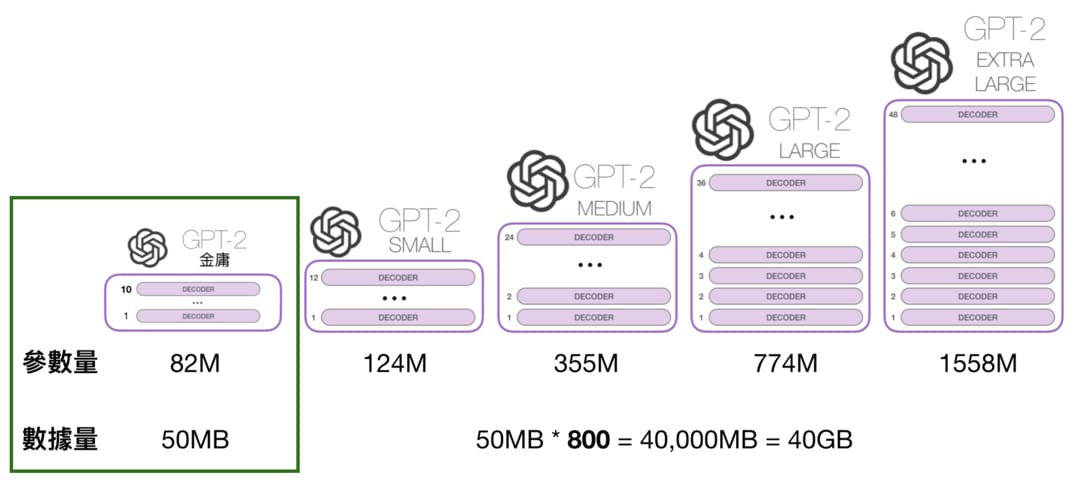
是的,金庸 GPT-2 不管是在訓練數據還是模型尺寸都比論文裡最小的 GPT-2 Small 還來得小,因此你不該期待它表現地跟任何使用大型 GPT-2 模型的線上 demo 一樣好。但因為它是讀中文文章,非常適合我們理解,是作為教學用途的好夥伴。另外注意金庸 GPT-2 使用了 10 層 Decoder blocks,而我們可以用 BertViz 輕易地視覺化每一層的自注意力機制。
比方說給定一個在金庸原著裡不存在,但我超級想要實現的《天龍八部》劇情:
喬峯帶阿朱回到北方,喬峯對她說:「我們兩人永遠留在這裡!」
透過我為你準備好的 Colab 筆記本及預先訓練好的金庸 GPT-2,你只需幾行 Python 程式碼就能視覺化每一層 Decoder block 處理這段文本的結果:
from bertviz.pytorch_transformers_attn import GPT2Model
gpt2_model = GPT2Model.from_pretrained('.')
text = '喬峯帶阿朱回到北方,喬峯對她說:「我們兩人永遠留在這裡!」'
view = 'model'
show(gpt2_model, tokenizer, text, view)
我們在這邊不會細談,但你會發現上下每一層 Decoder block 左右各有 12 個 heads。這就是之前介紹過的 Multi-head Attention 機制,目的是讓模型能夠給予每個詞彙多個不同的 representations 並在不同 representation spaces 裡關注不同位置,增加表達能力。
這些圖的解讀方式是當 GPT-2 看左側特定詞彙時,關注右側同序列中出現在該詞彙之前(包含自己)的其他詞彙。關注的程度則透過線條粗細來表示。
而如果我們將 GPT-2 生成這段文本的自注意力機制的變化依照詞彙的生成順序顯示出來的話,會看起來像這樣:
# BertViz 的 neuron view 可以看到 key, value 的匹配
view = 'neuron'
show(gpt2_model, tokenizer, text, view)
這邊的重點是前面講過的 Masked Self-Attention:一個傳統、單向的語言模型在處理新詞彙時只會、也只能關注前面已經被生成的其他詞彙,而不該去看「未來」的詞彙。
不知道你有沒有注意到,在上面的例子中,GPT-2 在處理詞彙「她」時會去關注前面靠近人名的「阿」,這是一件很了不起的事情:
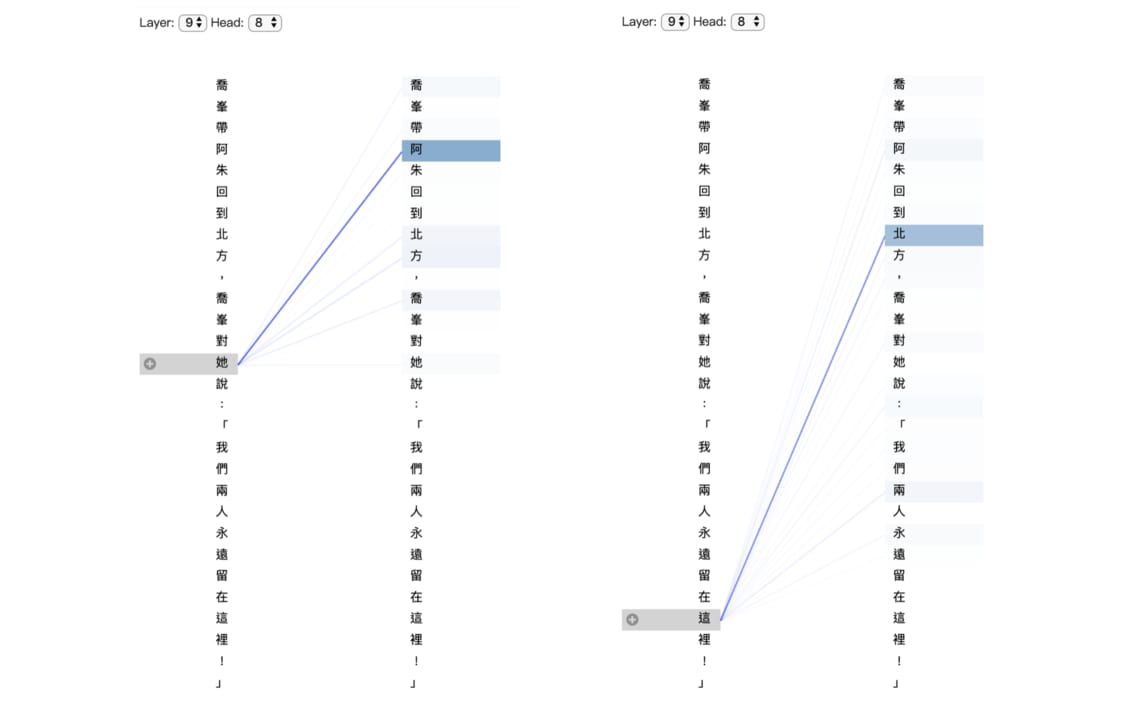
如同我們在前面章節提過的,中文字「她」與「這」本身並沒有太多含義,只有在了解情境之後才能判別它們所代表的意義。而這是具有自注意力機制的 NLP 模型可以想辦法學會的。
我們也可以看看不同層的 Decoder blocks 在關注同樣的文本時有什麼變化:
# 實際上只會產生一個可以選擇不同層的 UI,我隨意選了 3 層的截圖結果
text = '喬峯帶阿朱回到北方,喬峯對她說:「我們兩人永遠留在這裡!」'
view = 'head'
show(gpt2_model, tokenizer, text, view)
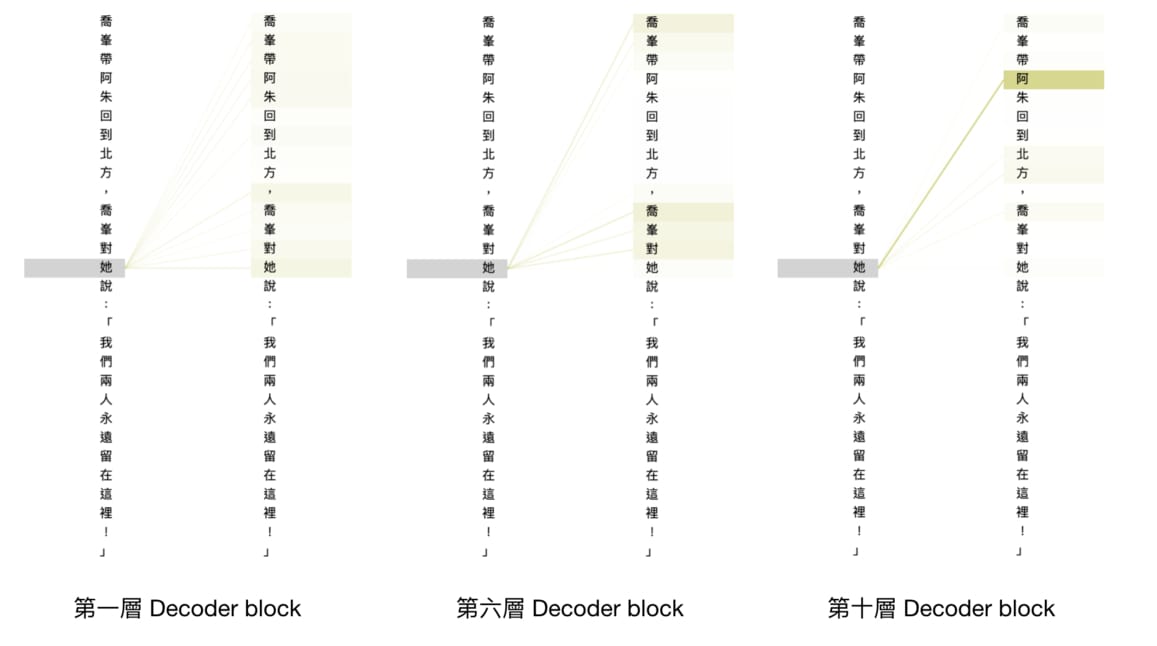
你可以明顯地觀察到底層(第一層)的 Decoder block 在處理詞彙「她」時將注意力放到多個詞彙上以擷取整個前文資訊。而越上層的 block 的注意力越顯集中,到了最後一層的 Decoder block 時就相當專注在較遠的人名附近。
透過這些視覺化結果,你現在應該對 GPT-2 的運作模式有著更直觀的理解了。
故事尾聲¶
呼!我希望你享受這趟跟我一起探索 GPT-2 以及金庸著作的旅程。
就我所知,這應該是網路上第一篇以中文 GPT-2 為背景,用最白話的方式講解相關概念的中文文章了。我在撰寫本文時嘗試用初學者最容易理解的章節編排方式、省略不必要的艱澀詞彙並避免丟上一長串程式碼。如果你讀完覺得本文內容很簡單,GPT-2 也不過就這樣,或者迫不及待想要知道更多細節,那就達成我撰寫本文的目標了。

本文為了顧及更多剛剛入門 NLP 的讀者省略了不少技術細節,如長距離依賴(Long-range Dependencies)的探討、自注意力機制的實作細節及研究 GPT-2 是真的學習還是只是記憶等課題。想要深入研究相關概念的讀者,下節的延伸閱讀可供你做參考。而如果你想要打好 NLP 基礎以及本文提到的相關知識,我會推薦你回到前面的前置知識一節,選擇最合你胃口的 NLP 文章開始閱讀。
正如統計學家喬治·E·P·博克斯所說的:
所有模型都是錯的;但有些是有用的。
─ George E. P. Box
等到哪天有更好的語言模型可以拿來生成金庸武俠小說,你就會再次看到我撰寫相關文章了。
但今天就到這裡啦!我現在還得煩惱該從哪部金庸小說開始複習呢 ...
跟資料科學相關的最新文章直接送到家。 只要加入訂閱名單,當新文章出爐時, 你將能馬上收到通知