故學然後知不足,教然後知困。知不足,然後能自反也;知困,然後能自強也,故曰:教學相長也。
─ 《禮記.學記》
pandas 是 Python 的一個資料分析函式庫,提供如 DataFrame 等十分容易操作的資料結構,是近年做數據分析時不可或需的工具之一。
雖然已經有滿坑滿谷的教學文章、影片或是線上課程,正是因為 pandas 學習資源之多,導致初學者常常不知如何踏出第一步。在這篇文章裡頭,我以自身作為資料科學家(Data Scientist, DS)的工作經驗,將接近 40 個實用的 pandas 技巧由淺入深地分成 6 大類別:
透過有系統地呈現這些 pandas 技巧,我希望能讓更多想要利用 Python 做資料分析或是想成為 DS 的你,能用最有效率的方式掌握核心 pandas 能力;同時也希望你能將自己認為實用但本文沒有提到的技巧與我分享,達到開頭引文所說的教學相長:)
如果你是使用寬螢幕瀏覽本文,隨時可以點擊左側傳送門瀏覽各章內容:
除了 pandas 的操作技巧以外,我在最後一節:與 pandas 相得益彰的實用工具裡也介紹了幾個實用函式庫。就算你是 pandas 老手,或許也能從中得到些收穫。當然也非常歡迎與我分享其他厲害工具,我會更新到文章裡頭讓更多人知道。
前言已盡,讓我們開始這趟 pandas 旅程吧!當然,首先你得 import pandas:
import pandas as pd
pd.__version__
建立 DataFrame¶
pandas 裡有非常多種可以初始化一個 DataFrame 的技巧。以下列出一些我覺得實用的初始化方式。
用 Python dict 建立 DataFrame¶
使用 Python 的 dict 來初始化 DataFrame 十分直覺。基本上 dict 裡頭的每一個鍵值(key)都對應到一個欄位名稱,而其值(value)則是一個 iterable,代表該欄位裡頭所有的數值。
dic = {
"col 1": [1, 2, 3],
"col 2": [10, 20, 30],
"col 3": list('xyz'),
"col 4": ['a', 'b', 'c'],
"col 5": pd.Series(range(3))
}
df = pd.DataFrame(dic)
df
在需要管理多個 DataFrames 時你會想要用更有意義的名字來代表它們,但在資料科學領域裡只要看到 df,每個人都會預期它是一個 DataFrame,不論是 Python 或是 R 語言的使用者。
很多時候你也會需要改變 DataFrame 裡的欄位名稱:
rename_dic = {"col 1": "x", "col 2": "10x"}
df.rename(rename_dic, axis=1)
這邊也很直覺,就是給一個將舊欄位名對應到新欄位名的 Python dict。值得注意的是參數 axis=1:在 pandas 裡大部分函式預設處理的軸為列(row):以 axis=0 表示;而將 axis 設置為 1 則代表你想以行(column)為單位套用該函式。
你也可以用 df.columns 的方式改欄位名稱:
df.columns = ['x(new)', '10x(new)'] + list(df.columns[2:])
df
使用 pd.util.testing 隨機建立 DataFrame¶
當你想要隨意初始化一個 DataFrame 並測試 pandas 功能時,pd.util.testing 就顯得十分好用:
pd.util.testing.makeDataFrame().head(10)
head 函式預設用來顯示 DataFrame 中前 5 筆數據。要顯示後面數據則可以使用 tail 函式。
你也可以用 makeMixedDataFrame 建立一個有各種資料型態的 DataFrame 方便測試:
pd.util.testing.makeMixedDataFrame()
其他函式如 makeMissingDataframe 及 makeTimeDataFrame 在後面的章節都還會看到。
將剪貼簿內容轉換成 DataFrame¶
你可以從 Excel、Google Sheet 或是網頁上複製表格並將其轉成 DataFrame。
簡單 2 步驟:
- 複製其他來源的表格
- 執行
pd.read_clipboard
這個技巧在你想要快速將一些數據轉成 DataFrame 時非常方便。當然,你得考量重現性(reproducibility)。
為了讓未來的自己以及他人可以重現你當下的結果,必要時記得另存新檔以供後人使用:
df.to_csv("some_data.csv")
讀取線上 CSV 檔¶
不限於本地檔案,只要有正確的 URL 以及網路連線就可以將網路上的任意 CSV 檔案轉成 DataFrame。
比方說你可以將 Kaggle 著名的鐵達尼號競賽的 CSV 檔案從網路上下載下來並轉成 DataFrame:
df = pd.read_csv('http://bit.ly/kaggletrain')
df.head()
以下則是另個使用 pandas 爬取網路上數據並作分析的真實案例。
我在之前的 Chartify 教學文中從臺北市的資料開放平台爬取 A1 及 A2 類交通事故數據後做了簡單匯總:
# 你可以用類似的方式爬取任何網路上的公開數據集
base_url = "https://data.taipei/api/getDatasetInfo/downloadResource?id={}&rid={}"
_id = "2f238b4f-1b27-4085-93e9-d684ef0e2735"
rid = "ea731a84-e4a1-4523-b981-b733beddbc1f"
csv_url = base_url.format(_id, rid)
df_raw = pd.read_csv(csv_url, encoding='big5')
# 複製一份做處理
df = df_raw.copy()
# 計算不同區不同性別的死亡、受傷人數
df['區序'] = df['區序'].apply(lambda x: ''.join([i for i in x if not i.isdigit()]))
df = (df[df['性別'].isin([1, 2])]
.groupby(['區序', '性別'])[['死亡人數', '受傷人數']]
.sum()
.reset_index()
.sort_values('受傷人數'))
df['性別'] = df['性別'].apply(lambda x: '男性' if x == 1 else '女性')
df = df.reset_index().drop('index', axis=1)
# 顯示結果
display(df_raw.head())
display(df.head())
有了匯總過後的 DataFrame,你可以用後面簡易繪圖並修改預設樣式章節提到的 pandas plot 函式繪圖。但在這邊讓我用 Chartify 展示結果:
import chartify
ch = chartify.Chart(
x_axis_type='categorical',
y_axis_type='categorical')
ch.plot.heatmap(
data_frame=df,
y_column='性別',
x_column='區序',
color_column='受傷人數',
text_column='受傷人數',
color_palette='Reds',
text_format='{:,.0f}')
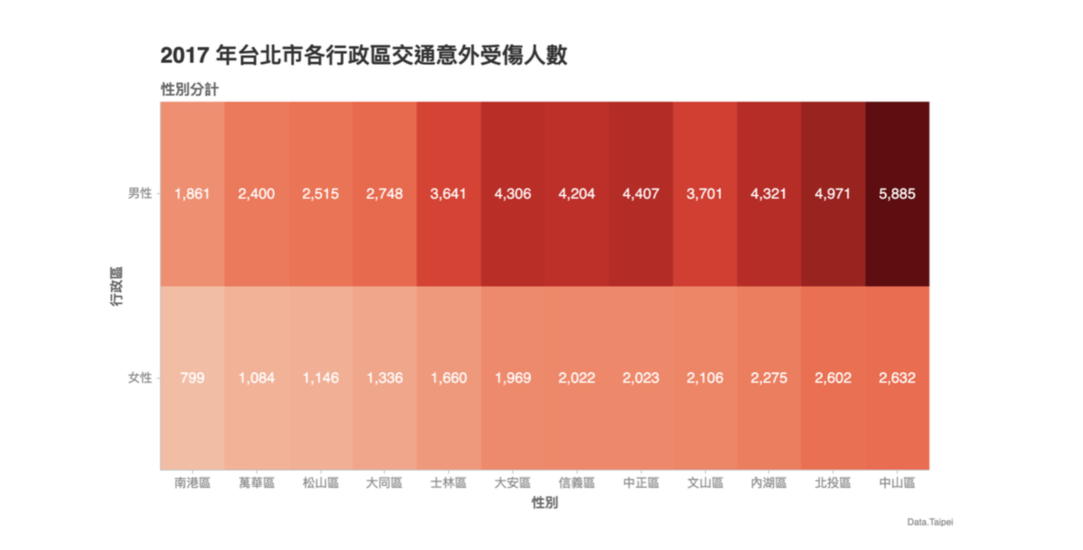
(ch.set_title('2017 年台北市各行政區交通意外受傷人數')
.set_subtitle('性別分計')
.set_source_label("Data.Taipei")
.axes.set_xaxis_label('性別')
.axes.set_yaxis_label('行政區')
.show('png'))
過來人經驗。雖然像這樣利用 pandas 直接從網路上下載並分析數據很方便,有時 host 數據的網頁與機構(尤其是政府機關)會無預期地修改他們網站,導致數據集的 URL 失效(苦主)。為了最大化重現性,我還是會建議將數據載到本地備份之後,再做分析比較實在。
優化記憶體使用量¶
你可以透過 df.info 查看 DataFrame 當前的記憶體用量:
df.info(memory_usage="deep")
從最後一列可以看出鐵達尼號這個小 DataFrame 只佔了 322 KB。如果你是透過 Jupyter 筆記本來操作 pandas,也可以考慮用 Variable Inspector 插件來觀察包含 DataFrame 等變數的大小:
這邊使用的 df 不佔什麼記憶體,但如果你想讀入的 DataFrame 很大,可以只讀入特定的欄位並將已知的分類型(categorical)欄位轉成 category 型態以節省記憶體(在分類數目較數據量小時有效):
dtypes = {"Embarked": "category"}
cols = ['PassengerId', 'Name', 'Sex', 'Embarked']
df = pd.read_csv('http://bit.ly/kaggletrain',
dtype=dtypes, usecols=cols)
df.info(memory_usage="deep")
透過減少讀入的欄位數並將 object 轉換成 category 欄位,讀入的 df 只剩 135 KB。只需剛剛的 40 % 記憶體用量。
另外如果你想在有限的記憶體內處理巨大 CSV 檔案,也可以透過 chunksize 參數來限制一次讀入的列數(rows):
from IPython.display import display
# chunksize=4 表示一次讀入 4 筆樣本
reader = pd.read_csv('dataset/titanic-train.csv',
chunksize=4, usecols=cols)
# 秀出前兩個 chunks
for _, df_partial in zip(range(2), reader):
display(df_partial)
讀入並合併多個 CSV 檔案成單一 DataFrame¶
很多時候因為企業內部 ETL 或是數據處理的方式(比方說利用 Airflow 處理批次數據),相同類型的數據可能會被分成多個不同的 CSV 檔案儲存。
假設在本地端 dataset 資料夾內有 2 個 CSV 檔案,分別儲存鐵達尼號上不同乘客的數據:
pd.read_csv("dataset/passenger1.csv")
另外一個 CSV 內容:
pd.read_csv("dataset/passenger2.csv")
注意上面 2 個 DataFrames 的內容雖然分別代表不同乘客,其格式卻是一模一樣。這種時候你可以使用 pd.concat 將分散在不同 CSV 的乘客數據合併成單一 DataFrame,方便之後處理:
from glob import glob
files = glob("dataset/passenger*.csv")
df = pd.concat([pd.read_csv(f) for f in files])
df.reset_index(drop=True)
你還可以使用 reset_index 函式來重置串接後的 DataFrame 索引。
前面說過很多 pandas 函式預設的 axis 參數為 0,代表著以列(row)為單位做特定的操作。在 pd.concat 的例子中則是將 2 個同樣格式的 DataFrames 依照列串接起來。
有時候同一筆數據的不同特徵值(features)會被存在不同檔案裡頭。以鐵達尼號的數據集舉例:
pd.read_csv("dataset/feature_set1.csv")
除了乘客名稱以外,其他如年齡以及性別等特徵值則被存在另個 CSV 裡頭:
pd.read_csv("dataset/feature_set2.csv")
假設這 2 個 CSV 檔案裡頭同列對應到同個乘客,則你可以很輕鬆地用 pd.concat 函式搭配 axis=1 將不同 DataFrames 依照行(column)串接:
files = glob("dataset/feature_set*.csv")
pd.concat([pd.read_csv(f) for f in files], axis=1)
客製化 DataFrame 顯示設定¶
雖然 pandas 會盡可能地將一個 DataFrame 完整且漂亮地呈現出來,有時候你還是會想要改變預設的顯示方式。這節列出一些常見的使用情境。
完整顯示所有欄位¶
有時候一個 DataFrame 裡頭的欄位太多, pandas 會自動省略某些中間欄位以保持頁面整潔:
df = pd.util.testing.makeCustomDataframe(5, 25)
df
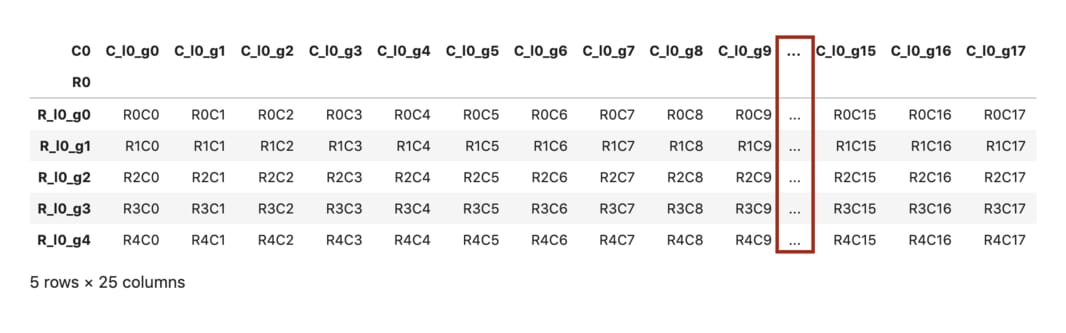
但如果你無論如何都想要顯示所有欄位以方便一次查看,可以透過 pd.set_option 函式來改變 display.max_columns 設定:
pd.set_option("display.max_columns", None)
df
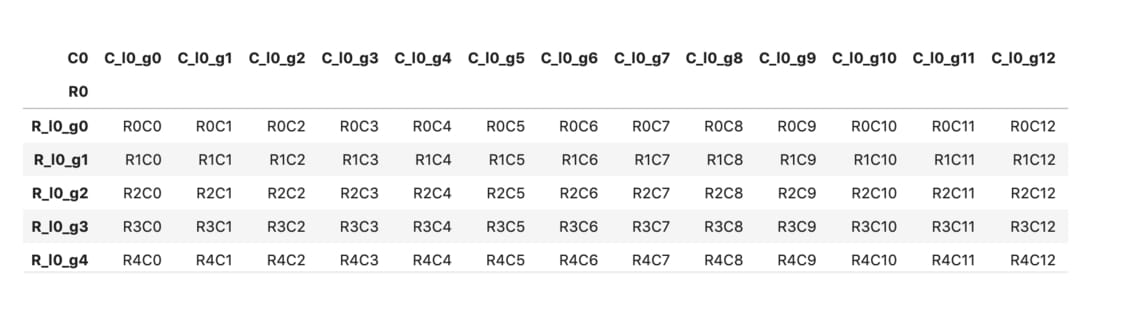
注意 ... 消失了。另外你也可以使用 T 來轉置(transpose)當前 DataFrame,垂直顯示所有欄位:
# 注意轉置後 `head(15)` 代表選擇前 15 個欄位
df.T.head(15)
這個測試用的 DataFrame 欄位裡頭的 C 正代表著 column。你可以在 pandas 官方文件裡查看其他常用的顯示設定。
減少顯示的欄位長度¶
這邊你一樣可以透過 pd.set_option 函式來限制鐵達尼號資料集裡頭 Name 欄位的顯示長度:
from IPython.display import display
print("display.max_colwidth 預設值:",
pd.get_option("display.max_colwidth"))
# 使用預設設定來顯示 DataFrame
df = pd.read_csv('http://bit.ly/kaggletrain')
display(df.head(3))
print("注意 Name 欄位的長度被改變了:")
# 客製化顯示(global)
pd.set_option("display.max_colwidth", 10)
df.head(3)
改變浮點數顯示位數¶
除了欄位長度以外,你常常會想要改變浮點數(float)顯示的小數點位數:
pd.set_option("display.precision", 1)
df.head(3)
你會發現 Fare 欄位現在只顯示小數點後一位的數值了。另外注意剛剛設定的 max_colwidth 是會被套用到所有 DataFrame 的。因此這個 DataFrame 的 Name 欄位顯示的寬度還跟上個 DataFrame 相同:都被縮減了。
想要將所有調整過的設定初始化,可以執行:
pd.reset_option("all")
其他常用的 options 包含:
max_rowsmax_columnsdate_yearfirst
等等。執行 pd.describe_option() 可以顯示所有可供使用的 options,但如果你是在 Jupyter 筆記本內使用 pandas 的話,我推薦直接在 set_option 函式的括號裡輸入 Shift + tab 顯示所有選項:
為特定 DataFrame 加點樣式¶
pd.set_option 函式在你想要把某些顯示設定套用到所有 DataFrames 時很好用。不過很多時候你會想要讓不同 DataFrame 有不同的顯示設定或樣式(styling)。
比方說針對下面這個只有 10 筆數據的 DataFrame,你想要跟上一節一樣把 Fare 欄位弄成只有小數點後一位,但又不想影響到其他 DataFrame 或是其他欄位:
# 隨機抽樣 10 筆數據來做 styling
df_sample = df.sample(n=10, random_state=9527).drop('Name', axis=1)
df_sample.Age.fillna(int(df.Age.mean()), inplace=True)
df_sample
這時候你可以使用 pandas Styler 底下的 format 函式來做到這件事情:
# 一個典型 chain pandas 函式的例子
(df_sample.style
.format('{:.1f}', subset='Fare')
.set_caption('★五顏六色の鐵達尼號數據集☆')
.hide_index()
.bar('Age', vmin=0)
.highlight_max('Survived')
.background_gradient('Greens',
subset='Fare')
.highlight_null()
)
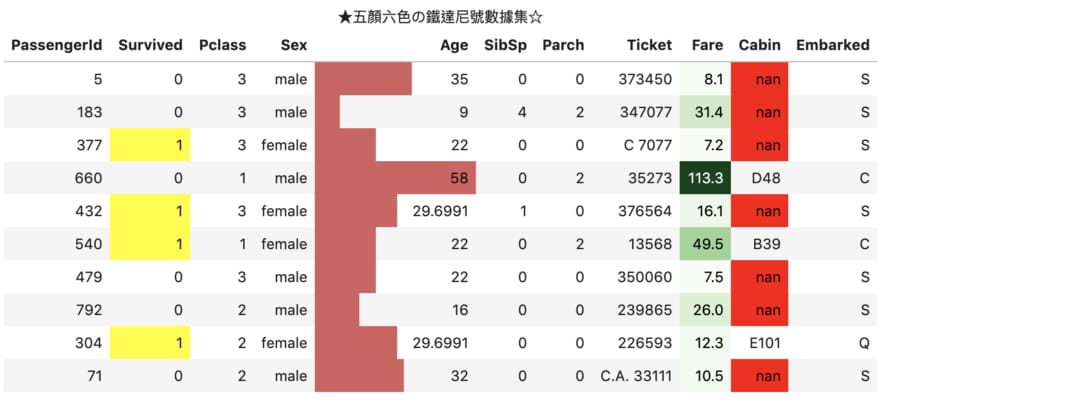
如果你從來沒有用過 df.style,這應該是你這輩子看過最繽紛的 DataFrame。
從上而下,上述程式碼對此 DataFrame 做了以下 styling:
- 將
Fare欄位的數值顯示限制到小數後第一位 - 添加一個標題輔助說明
- 隱藏索引(注意最左邊!)
- 將
Age欄位依數值大小畫條狀圖 - 將
Survived最大的值 highlight - 將
Fare欄位依數值畫綠色的 colormap - 將整個 DataFrame 的空值顯示為紅色
pd.DataFrame.style 會回傳一個 Styler。你已經看到除了 format 函式以外,還有很多其他函式可以讓你為 DataFrame 添加樣式。使用 format 函式的最大好處是你不需要用像是 round 等函式去修改實際數值,而只是改變呈現結果而已。
熟悉 styling 技巧能讓你不需畫圖就能輕鬆與他人分享簡單的分析結果,也能凸顯你想讓他們關注的事物。小提醒:為了讓你能一次掌握常用函式,我把能加的樣式都加了。實務上你應該思考什麼視覺變數是必要的,而不是盲目地添加樣式。
另外值得一提的是 pandas 函式都會回傳處理後的結果,而不是直接修改原始 DataFrame。這讓你可以輕鬆地把多個函式串(chain)成一個複雜的數據處理 pipeline,但又不會影響到最原始的數據:
df_sample
瞧!原來的 DataFrame 還是挺淳樸的。注意 Fare 欄位裡的小數點並沒有因為剛剛的 styling 而變少,而這讓你在呈現 DataFrame 時有最大的彈性。
數據清理 & 整理¶
這節列出一些十分常用的數據清理與整理技巧,如處理空值(null value)以及切割欄位。
處理空值¶
世界總是殘酷,很多時候手上的 DataFrame 裡頭會有不存在的值,如底下一格格額外顯眼的 NaN:
df = pd.util.testing.makeMissingDataframe().head()
df
你可以利用 fillna 函式將 DataFrame 裡頭所有不存在的值設為 0:
df.fillna(0)
當然,這個操作的前提是你確定在當前分析的情境下,將不存在的值視為 0 這件事情是沒有問題的。
針對字串欄位,你也可以將空值設定成任何容易識別的值,讓自己及他人明確了解此 DataFrame 的數據品質:
df = pd.util.testing.makeMissingCustomDataframe(nrows=5,
ncols=4,
dtype=str)
df.fillna("Unknown")
捨棄不需要的行列¶
給定一個初始 DataFrame:
df = pd.util.testing.makeDataFrame().head()
df
你可以使用 drop 函式來捨棄不需要的欄位。記得將 axis 設為 1:
columns = ['B', 'D']
df.drop(columns, axis=1)
同理,你也可以捨棄特定列(row):
df.drop('OOOtaUhOOp')
重置並捨棄索引¶
很多時候你會想要重置一個 DataFrame 的索引,以方便使用 loc 或 iloc 屬性來存取想要的數據。
給定一個 DataFrame:
df = pd.util.testing.makeDataFrame().head()
df
你可以使用 reset_index 函式來重置此 DataFrame 的索引並輕鬆存取想要的部分:
df.reset_index(inplace=True)
df.iloc[:3, :]
# 豆知識:因為 iloc 是屬性而非函式,
# 因此你得使用 [] 而非 () 存取數據
將函式的 inplace 參數設為 True 會讓 pandas 直接修改 df。一般來說 pandas 裡的函式並不會修改原始 DataFrame,這樣可以保證原始數據不會受到任何函式的影響。
當你不想要原來的 DataFrame df 受到 reset_index 函式的影響,則可以將處理後的結果交給一個新 DataFrame(比方說 df1):
df = pd.util.testing.makeDataFrame().head()
df1 = df.reset_index(drop=True)
display(df)
display(df1)
透過這樣的方式,pandas 讓你可以放心地對原始數據做任何壞壞的事情而不會產生任何不好的影響。
將字串切割成多個欄位¶
在處理文本數據時,很多時候你會想要把一個字串欄位拆成多個欄位以方便後續處理。
給定一個簡單 DataFrame:
df = pd.DataFrame({
"name": ["大雄", "胖虎"],
"feature": ["膽小, 翻花繩", "粗魯, 演唱會"]
})
df
你可能會想把這個 DataFrame 的 feature 欄位分成不同欄位,這時候利用 str 將字串取出,並透過 expand=True 將字串切割的結果擴大成(expand)成一個 DataFrame:
df[['性格', '特技']] = df.feature.str.split(',', expand=True)
df
注意我們使用 df[columns] = ... 的形式將字串切割出來的 2 個新欄位分別指定成 性格 與 特技。
將 list 分成多個欄位¶
有時候一個欄位裡頭的值為 Python list:
df = pd.DataFrame({
"name": ["大雄", "胖虎"],
"feature": [["膽小", "翻花繩"], ["粗魯", "演唱會"]]
})
df
這時則可以使用 tolist 函式做到跟剛剛字串切割相同的效果:
cols = ['性格', '特技']
pd.DataFrame(df.feature.tolist(), columns=cols)
你也可以使用 apply(pd.Series) 的方式達到一樣的效果:
df.feature.apply(pd.Series)
遇到以 Python list 呈現欄位數據的情境不少,這些函式能讓你少抓點頭。
取得想要關注的數據¶
通常你會需要依照各種不同的分析情境,將整個 DataFrame 裡頭的一部份數據取出並進一步分析。這節內容讓你能夠輕鬆取得想要關注的數據。
基本數據切割¶
在 pandas 裡頭,切割(Slice)DataFrame 裡頭一部份數據出來做分析是稀鬆平常的事情。讓我們再次以鐵達尼號數據集為例:
df = pd.read_csv('http://bit.ly/kaggletrain')
df = df.drop("Name", axis=1)
df.head()
你可以透過 loc 以及 : 的方式輕鬆選取從某個起始欄位 C1 到結束欄位 C2 的所有欄位,而無需將中間的欄位一一列出:
df.loc[:3, 'Pclass':'Ticket']
反向選取行列¶
透過 Python 常見的 [::-1] 語法,你可以輕易地改變 DataFrame 裡頭所有欄位的排列順序:
df.loc[:3, ::-1]
同樣概念也可以運用到列(row)上面。你可以將所有樣本(samples)排序顛倒並選取其中 N 列:
df.iloc[::-1, :5].head()
注意我們同時使用 :5 來選出前 5 個欄位。
條件選取數據¶
在 pandas 裡頭最實用的選取技巧大概非遮罩(masking)莫屬了。遮罩讓 pandas 將符合特定條件的樣本回傳:
male_and_age_over_70 = (df.Sex == 'male') & (df.Age > 70)
(df[male_and_age_over_70]
.style
.applymap(lambda x: 'background-color: rgb(153, 255, 51)',
subset=pd.IndexSlice[:, 'Sex':'Age']))
# 跟 df[(df.Sex == 'male') & (df.Age > 70)] 結果相同
male_and_age_over_70 是我們定義的一個遮罩,可以把同時符合兩個布林判斷式(大於 70 歲、男性)的樣本選取出來。上面註解有相同效果,但當存在多個判斷式時,有個準確說明遮罩意義的變數(上例的 male_and_age_over_70)會讓你的程式碼好懂一點。
另外你也可以使用 query 函式來達到跟遮罩一樣的效果:
age = 70
df.query("Age > @age & Sex == 'male'")
在這個例子裡頭,你可以使用 @ 來存取已經定義的 Python 變數 age 的值。
選擇任一欄有空值的樣本¶
一個 DataFrame 裡常會有多個欄位(column),而每個欄位裡頭都有可能包含空值。
有時候你會想把在任一欄位(column)出現過空值的樣本(row)全部取出:
df[df.isnull().any(axis=1)].head() \
.style.highlight_null()
這邊剛好所有樣本的 Cabin 欄位皆為空值。但倒數第 2 個樣本就算其 Cabin 欄不為空值,也會因為 Age 欄為空而被選出。
選取或排除特定類型欄位¶
有時候你會想選取 DataFrame 裡特定數據類型(字串、數值、時間型態等)的欄位,這時你可以使用 select_dtypes 函式:
df.select_dtypes(include='number').head()
上面我們用一行程式碼就把所有數值欄位取出,儘管我們根本不知道有什麼欄位。而你當然也可以利用 exclude 參數來排除特定類型的欄位:
# 建立一個有多種數據形態的 DataFrame
df_mix = pd.util.testing.makeMixedDataFrame()
display(df_mix)
display(df_mix.dtypes)
display(df_mix.select_dtypes(exclude=['datetime64', 'object']))
pandas 裡的函式使用上都很直覺,你可以丟入 1 個包含多個元素的 Python list 或是單一 str 作為參數輸入。
選取所有出現在 list 內的樣本¶
很多時候針對某一個特定欄位,你會想要取出所有出現在一個 list 的樣本。這時候你可以使用 isin 函式來做到這件事情:
tickets = ["SC/Paris 2123", "PC 17475"]
df[df.Ticket.isin(tickets)]
選取某欄位為 top-k 值的樣本¶
很多時候你會想選取在某個欄位中前 k 大的所有樣本。這時你可以先利用 value_counts 函式找出該欄位前 k 多的值:
top_k = 3
top_tickets = df.Ticket.value_counts()[:top_k]
top_tickets.index
這邊我們以欄位 Ticket 為例。另外你也可以使用 pandas.Series 裡的 nlargest 函式取得相同結果:
df.Ticket.value_counts().nlargest(top_k).index
接著利用上小節看過的 isin 函式就能輕鬆取得 Ticket欄位值為前 k 大值的樣本:
df[df.Ticket.isin(top_tickets.index)].head()
找出符合特定字串的樣本¶
有時你會想要對一個字串欄位做正規表示式(regular expression),取出符合某個 pattern 的所有樣本。
這時你可以使用 str 底下的 contains 函式:
df = pd.read_csv('http://bit.ly/kaggletrain')
df[df.Name.str.contains("Mr\.")].head(5)
這邊我們將所有 Name 欄位值裡包含 Mr. 的樣本取出。注意 contains 函式接受的是正規表示式,因此需要將 . 轉換成 \.。
使用正規表示式選取數據¶
有時候你會想要依照一些規則來選取 DataFrame 裡頭的值、索引或是欄位,尤其是在處理跟時間序列相關的數據:
df_date = pd.util.testing.makeTimeDataFrame(freq='7D')
df_date.head(10)
假設你想將所有索引在 2000 年 2 月內的樣本取出,則可以透過 filter 函式達成這個目的:
df_date.filter(regex="2000-02.*", axis=0)
filter 函式本身功能十分強大,有興趣的讀者可以閱讀官方文件進一步了解其用法。
選取從某時間點開始的區間樣本¶
在處理時間數據時,很多時候你會想要針對某個起始時間挑出前 t 個時間點的樣本。
讓我們再看一次剛剛建立的 DataFrame:
df_date.head(8)
在索引為時間型態的情況下,如果你想要把前 3 週的樣本取出,可以使用 first 函式:
df_date.first('3W')
十分方便的函式。
基本數據處理與轉換¶
在了解如何選取想要的數據以後,你可以透過這節的介紹來熟悉 pandas 裡一些常見的數據處理方式。這章節也是我認為使用 pandas 處理數據時最令人愉快的部分之一。
對某一軸套用相同運算¶
你時常會需要對 DataFrame 裡頭的每一個欄位(縱軸)或是每一列(橫軸)做相同的運算。
比方說你想將鐵達尼號資料集內的 Survived 數值欄位轉換成人類容易理解的字串:
# 重新讀取鐵達尼號數據
df_titanic = pd.read_csv('http://bit.ly/kaggletrain')
df_titanic = df_titanic.drop("Name", axis=1)
# 複製一份副本 DataFrame
df = df_titanic.copy()
columns = df.columns.tolist()[:4]
# 好戲登場
new_col = '存活'
columns.insert(1, new_col) # 調整欄位順序用
df[new_col] = df.Survived.apply(lambda x: '倖存' if x else '死亡')
df.loc[:5, columns]
透過 apply 函式,我們把一個匿名函式 lambda 套用到整個 df.Survived Series 之上,並以此建立一個新的 存活 欄位。
值得一提的是當你需要追加新的欄位但又不想影響到原始 DataFrame 時,可以使用 copy 函式複製一份副本另行操作。
對每一個樣本做自定義運算¶
上小節我們用 apply 函式對 DataFrame 裡頭的某個 Series 做運算並生成新欄位:
df[new_col] = df.Survived.apply(...
不過你時常會想要把樣本(row)裡頭的多個欄位一次取出做運算並產生一個新的值。這時你可以自定義一個 Python function 並將 apply 函式套用到整個 DataFrame 之上:
df = df_titanic.copy()
display(df.head())
# apply custom function 可以說是 pandas 裡最重要的技巧之一
d = {'male': '男性', 'female': '女性'}
def generate_desc(row):
return f"一名 {row['Age']} 歲的{d[row['Sex']]}"
df['描述'] = df.apply(generate_desc, axis=1)
df.loc[:4, 'Sex':]
此例中 apply 函式將 generate_desc 函式個別套用到 DataFrame 裡頭的每一個樣本(row),結合 Sex 及 Age 兩欄位資訊,生成新的 描述。
當然,將 axis 設置為 0 則可以對每一個欄位分別套用自定義的 Python function。
將連續數值轉換成分類數據¶
有時你會想把一個連續數值(numerical)的欄位分成多個 groups 以方便對每個 groups 做統計。這時候你可以使用 pd.cut 函式:
df = df_titanic.copy()
# 為了方便比較新舊欄位
columns = df.columns.tolist()
new_col = '年齡區間'
columns.insert(4, new_col)
# 將 numerical 轉換成 categorical 欄位
labels = [f'族群 {i}' for i in range(1, 11)]
df[new_col] = pd.cut(x=df.Age,
bins=10,
labels=labels)
# 可以排序切割後的 categorical 欄位
(df.sort_values(new_col, ascending=False)
.reset_index()
.loc[:5, columns]
)
如上所示,使用 pd.cut 函式建立出來的每個分類 族群 X 有大小之分,因此你可以輕易地使用 sort_values 函式排序樣本。
df[new_col].dtype
將 DataFrame 隨機切成兩個子集¶
有時你會想將手上的 DataFrame 隨機切成兩個獨立的子集。選取其中一個子集來訓練機器學習模型是一個常見的情境。
要做到這件事情有很多種方法,你可以使用 scikit-learn 的 train_test_split 或是 numpy 的 np.random.randn,但假如你想要純 pandas 解法,可以使用 sample 函式:
df_train = df_titanic.sample(frac=0.8, random_state=5566)
df_test = df_titanic.drop(df_train.index)
# 顯示結果,無特殊操作
display(df_train.head())
display(df_test.head())
print('各 DataFrame 大小:',
len(df_titanic), len(df_train), len(df_test))
這個解法的前提是原來的 DataFrame df_titanic 裡頭的索引是獨一無二的。另外記得設定 random_state 以方便別人重現你的結果。
用 SQL 的方式合併兩個 DataFrames¶
很多時候你會想要將兩個 DataFrames 依照某個共通的欄位(鍵值)合併成單一 DataFrame 以整合資訊。
比方說給定以下兩個 DataFrames:
df_city = pd.DataFrame({
'state': ['密蘇里州', '亞利桑那州', '肯塔基州', '紐約州'],
'city': ['堪薩斯城', '鳳凰城', '路易維爾', '紐約市']
})
df_info = pd.DataFrame({
'city': ['路易維爾', '堪薩斯城', '鳳凰城'],
'population': [741096, 481420, 4039182],
'feature': list('abc')})
display(df_city)
display(df_info)
DataFrame df_city 包含了幾個美國城市以及其對應的州名(state);DataFrame df_info 則包含城市名稱以及一些數據。如果你想將這兩個 DataFrames 合併(merge),可以使用非常方便的 merge 函式:
pd.merge(left=df_city,
right=df_info,
how="left", # left outer join
on="city", # 透過此欄位合併
indicator=True # 顯示結果中每一列的來源
)
沒錯,merge 函式運作方式就像 SQL 一樣,可以讓你透過更改 how 參數來做:
left:left outer joinright:right outer joinouter: full outer joininner: inner join
注意合併後的 DataFrame 的最後一列:因為是 left join,就算右側的 df_info 裡頭並沒有紐約市的資訊,我們也能把該城市保留在 merge 後的結果。你還可以透過 indicator=True 的方式讓 pandas 幫我們新增一個 _merge 欄位,輕鬆了解紐約市只存在左側的 df_city 裡。
merge 函式強大之處在於能跟 SQL 一樣為我們抽象化如何合併兩個 DataFrames 的運算。如果你想要了解 SQL 跟 Python 本質上的差異,可以參考為何資料科學家需要學習 SQL 一文。
存取並操作每一個樣本¶
我們前面看過,雖然一般可以直接使用 apply 函式來對每個樣本作運算,有時候你就是會想用 for 迴圈的方式把每個樣本取出處理。
這種時候你可以用 itertuples 函式:
for row in df_city.itertuples(name='City'):
print(f'{row.city}是{row.state}裡頭的一個城市')
顧名思義,itertuples 函式回傳的是 Python namedtuple,也是一個你應該已經很熟悉的資料型態:
from collections import namedtuple
City = namedtuple('City', ['Index', 'state', 'city'])
c = City(3, '紐約州', '紐約市')
c == row
簡單匯總 & 分析數據¶
在對數據做些基本處理以後,你會想要從手上的 DataFrame 匯總或整理出一些有用的統計數據。本節介紹一些常用的數據匯總技巧。
取出某欄位 top k 的值¶
這你在選取某欄位為 top-k 值的樣本小節應該就看過了。
但因為這個使用情境實在太常出現,讓我們再次嘗試將鐵達尼號數據集裡頭 Ticket 欄位最常出現的值取出:
df = df_titanic.copy()
display(df.head())
display(df.Ticket.value_counts().head(5).reset_index())
value_counts 函式預設就會把欄位裡頭的值依照出現頻率由高到低排序,因此搭配 head 函式就可以把最常出現的 top k 值選出。
一行描述數值欄位¶
當你想要快速了解 DataFrame 裡所有數值欄位的統計數據(最小值、最大值、平均和中位數等)時可以使用 describe 函式:
df.describe()
你也可以用取得想要關注的數據一節的技巧來選取自己關心的統計數據:
df.describe().loc[['mean', 'std'], 'Survived':'Age']
找出欄位裡所有出現過的值¶
針對特定欄位使用 unique 函式即可:
df.Sex.unique()
分組匯總結果¶
很多時候你會想要把 DataFrame 裡頭的樣本依照某些特性分門別類,並依此匯總各組(group)的統計數據。這種時候你可以用 groupby 函式。
讓我們再次拿出鐵達尼號數據集:
df = df_titanic.copy()
df.head()
你可以將所有乘客(列)依照它們的 Pclass 欄位值分組,並計算每組裡頭乘客們的平均年齡:
df.groupby("Pclass").Age.mean()
你也可以搭配剛剛看過的 describe 函式來匯總各組的統計數據:
df.groupby("Sex").Survived.describe()
你也可以依照多個欄位分組,並利用 size 函式迅速地取得各組包含的樣本數:
df.groupby(["Sex", 'Pclass']).size().unstack()
你也可以用 agg 函式(aggregate,匯總)搭配 groupby 函式來將每一組樣本依照多種方式匯總:
df.groupby(["Sex", 'Pclass']).Age.agg(['min', 'max', 'count'])
透過 unstack 函式能讓你產生跟 pivot_table 函式相同的結果:
df.groupby(["Sex", 'Pclass']).Age.agg(['min', 'max', 'count']).unstack()
當然,你也可以直接使用 pivot_table 函式來匯總各組數據:
df.pivot_table(index='Sex',
columns='Pclass',
values='Age',
aggfunc=['min', 'max', 'count'])
依照背景不同,每個人會有偏好的 pandas 使用方式。選擇對你來說最直覺又好記的方式吧!
結合原始數據與匯總結果¶
不管是上節的 groupby 搭配 agg 還是 pivot_table,匯總結果都會以另外一個全新的 DataFrame 表示。
有時候你會想直接把各組匯總的結果放到原本的 DataFrame 裡頭,方便比較原始樣本與匯總結果的差異。這時你可以使用 transform 函式:
df = df_titanic.copy()
df['Avg_age'] = df.groupby("Sex").Age.transform("mean")
df['Above_avg_age'] = df.apply(lambda x: 'yes' if x.Age > x.Avg_age else 'no',
axis=1)
# styling
(df.loc[:4, 'Sex':]
.style
.highlight_max(subset=['Avg_age'])
.applymap(lambda x: 'background-color: rgb(153, 255, 51)',
subset=pd.IndexSlice[[0, 4], ['Age', 'Above_avg_age']])
)
此例將所有乘客依照性別 Sex 分組之後,計算各組的平均年齡 Age,並利用 transform 函式將各組結果插入對應的乘客(列)裡頭。你會發現兩名男乘客跟平均男性壽命 Avg_age 欄位相比正好一上一下,這差異則反映到 Above_avg_age 欄位裡頭。
對時間數據做匯總¶
給定一個跟時間相關的 DataFrame:
df_date = pd.util.testing.makeTimeDataFrame(freq='Q').head(10) * 10
df_date
你可以利用 resample 函式來依照不同時間粒度匯總這個時間 DataFrame:
(df_date.resample('Y').A.max()
.reset_index()
.rename({'index': 'year'}, axis=1)
)
此例中將不同年份(Year)的樣本分組,並從每一組的欄位 A 中選出最大值。你可以查看官方 resampling 說明文件來了解還有什麼時間粒度可以選擇(分鐘、小時、月份等等)。
另外小細節是你可以利用 numpy 的 broadcasting 運算輕鬆地將 DataFrame 裡的所有數值做操作(初始 df_date 時的用到的 * 10)。
簡易繪圖並修改預設樣式¶
在 Python 世界裡有很多數據視覺化工具供你選擇,比方說經典的 Matplotlib 以及在淺談神經機器翻譯一文中被我拿來視覺化矩陣運算的 Seaborn。你也可以使用前面看過的 Chartify 搭配 pandas 畫出美麗圖表。
但有時,你只需要 pandas 內建的 plot 函式就能輕鬆地將一個 DataFrame 轉成統計圖:
# 用 `plot` 一行畫圖。前兩行只是改變預設樣式
import matplotlib.pyplot as plt
plt.style.use("ggplot")
df.groupby("Pclass").Survived.count().plot("barh");
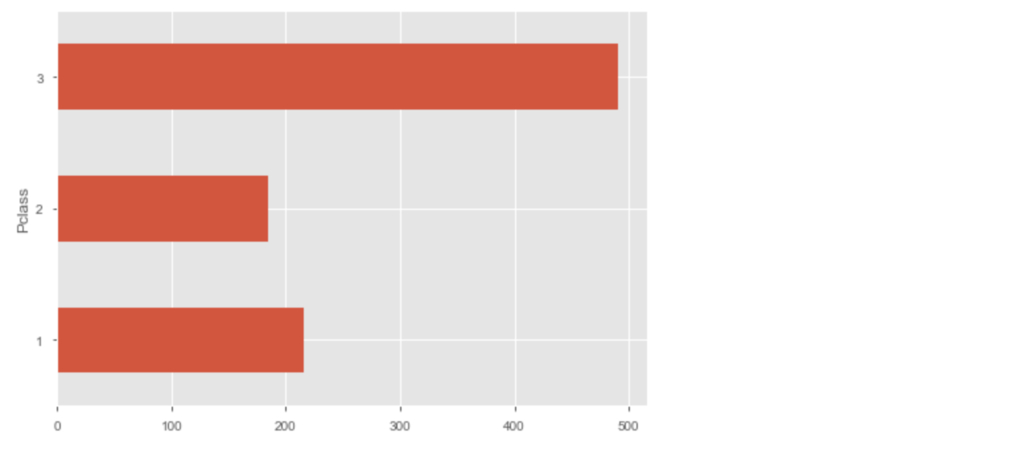
我們都是視覺動物,pandas 的 plot 函式讓你在進行探索型數據分析(Exploratory Data Analysis, EDA)、試著快速了解手上數據集時十分方便。我們在淺談資料視覺化以及 ggplot2 實踐一文也已經探討過類似概念:
另外 pandas 底層預設使用 Matplotlib 繪圖,而用過 Matplotlib 的人都知道其初始的繪圖樣式實在不太討喜。你可以透過 plt.style.available 查看所有可供使用的繪圖樣式(style),並將喜歡的樣式透過 plt.style.use() 套用到所有 DataFrames 的 plot 函式:
plt.style.available
與 pandas 相得益彰的實用工具¶
前面幾個章節介紹了不少 pandas 的使用技巧與操作概念,這節則介紹一些我認為十分適合跟 pandas 一起搭配使用的數據工具 / 函式庫。在說明每個工具的功能時,我都會使用你已經十分熟悉的鐵達尼號數據集作為範例 DataFrame:
df = df_titanic.copy()
df.head()
tqdm 是一個十分強大的 Python 進度條工具,且有整合 pandas。此工具可以幫助我們了解 DataFrame apply 函式的進度。回想一下我們在對某一軸套用相同運算一節做的一個簡單 apply 運算:
df['存活'] = df.Survived.apply(lambda x: '倖存' if x else '死亡')
df.loc[:5, 'Survived':'存活']
在這個不到 1,000 筆的 DataFrame 做這樣的簡單運算不用一秒鐘,但實務上你可能常常需要對幾十萬、幾百萬筆數據分別做複雜的運算,這時候了解執行進度就是一件非常重要的事情。首先透過 Anaconda 安裝 tqdm:
conda install -c conda-forge tqdm
如果你是在 Juypter 筆記本裡執行 pandas,可以用以下的方式將 tqdm 進度條整合到 apply 函式:
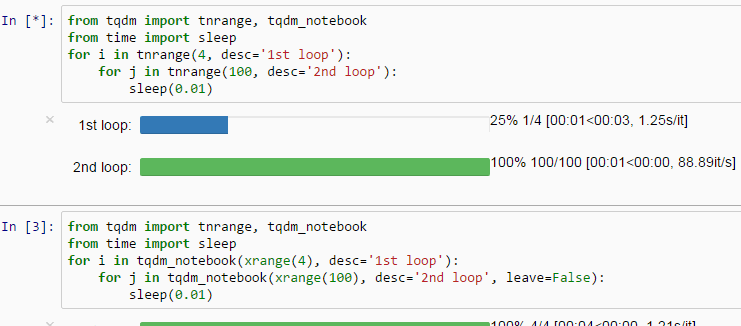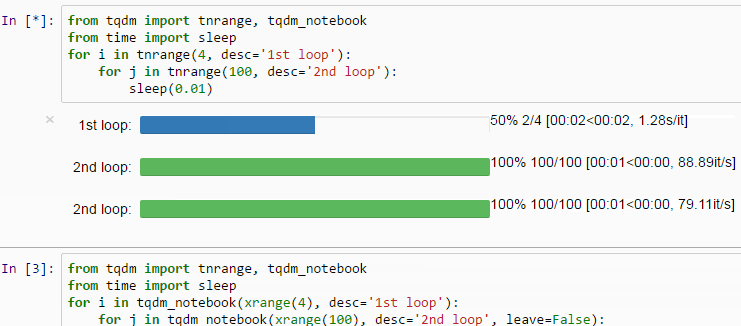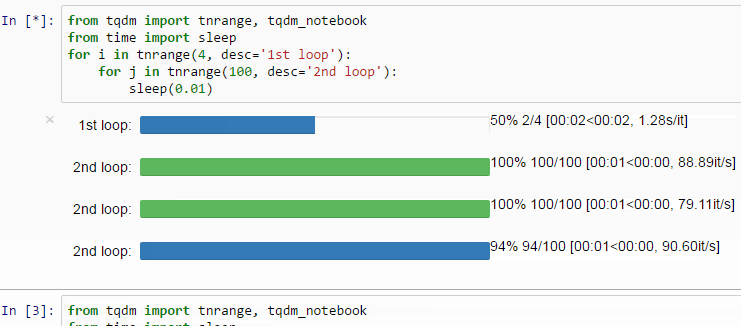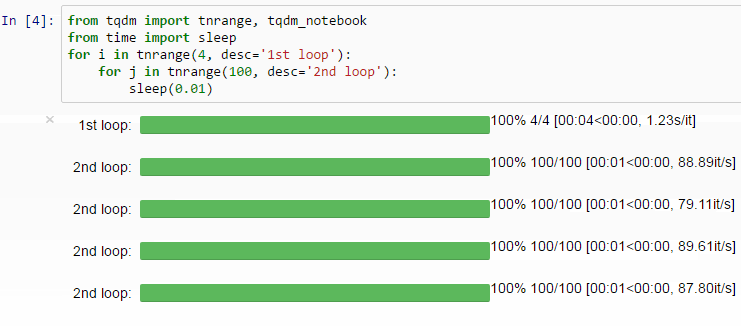
from tqdm import tqdm_notebook
tqdm_notebook().pandas()
clear_output()
# 只需將 `apply` 替換成 `progress_apply`
df['存活'] = df.Survived.progress_apply(lambda x: '倖存' if x else '死亡')
df.loc[:5, 'Survived':'存活']
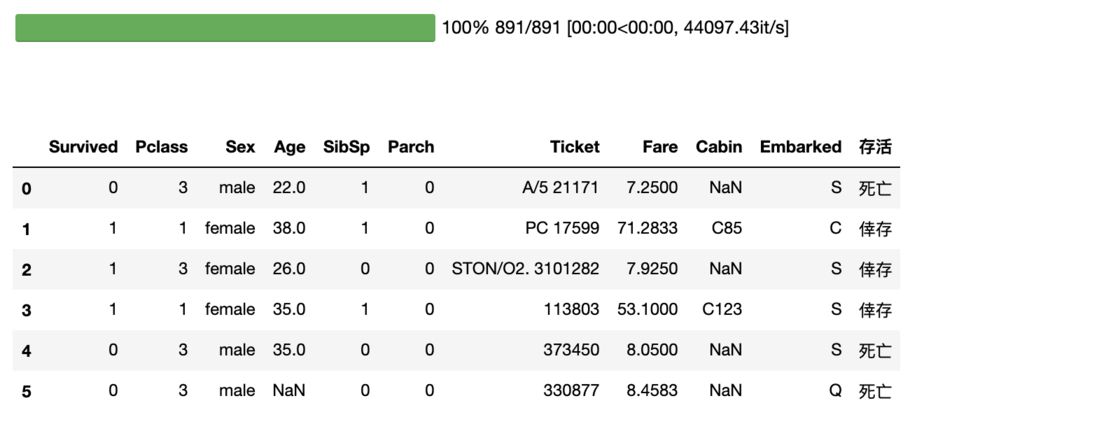
透過使用 progress_apply 函式,我們可以得到跟使用 apply 函式一樣的結果,附贈進度條。相信我,在你 apply 的函式很複雜且樣本數很大時,你會很感謝有進度條的存在。你可以查看 tqdm repo 了解更多使用案例:
swifter 函式庫能以最有效率的方式執行 apply 函式。同樣可以使用 Anaconda 安裝:
conda install -c conda-forge swifter
接著讓我建立一個有 100 萬筆樣本的 DataFrame ,測試 swifter 與原版 apply 函式的效能差異:
import swifter
df = pd.DataFrame(pd.np.random.rand(1000000, 1), columns=['x'])
%timeit -n 10 df['x2'] = df['x'].apply(lambda x: x**2)
%timeit -n 10 df['x2'] = df['x'].swifter.apply(lambda x: x**2)
在這個簡單的平方運算中,swifter 版的 apply 函式在我的 mac 上的效率是原始 apply 函式的 48 倍。而要使用 swifter 你也只需要加上 swifter 關鍵字即可,何樂而不為?
喔別擔心,剛剛的 tqdm 進度條仍然會繼續顯示:
df = pd.DataFrame(pd.np.random.rand(100000, 1), columns=['x'])
df['x2'] = df['x'].swifter.apply(lambda x: x**2)
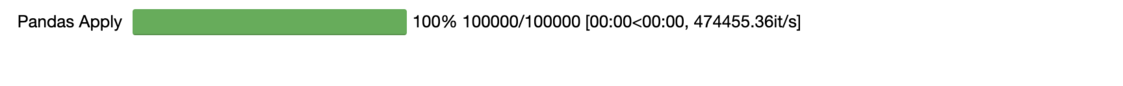
魚與熊掌兩者皆得。
qgrid 是一個能讓你在 Jupyter 筆記本裡使用簡單 UI 瀏覽並操作 DataFrame 的 widget。一樣透過 Anaconda 安裝:
conda install -c tim_shawver qgrid
jupyter nbextension enable --py --sys-prefix widgetsnbextension
實際的使用方式也非常簡單:
import qgrid
qgrid.set_grid_option('maxVisibleRows', 7)
q = qgrid.show_grid(df_titanic)
q
你可以簡單瀏覽 DataFrame 內容,也能依照欄位值篩選及排序樣本,甚至編輯裡頭的值。
如果你想要取得當前狀態的 DataFrame,也能使用 qgrid 裡頭的 get_changed_df 函式:
# 取得更改後的 DataFrame
df_changed = q.get_changed_df()
# styling
(df_changed.iloc[:8, :]
.style
.applymap(lambda x: 'color:red',
subset=pd.IndexSlice[829, 'SibSp'])
)
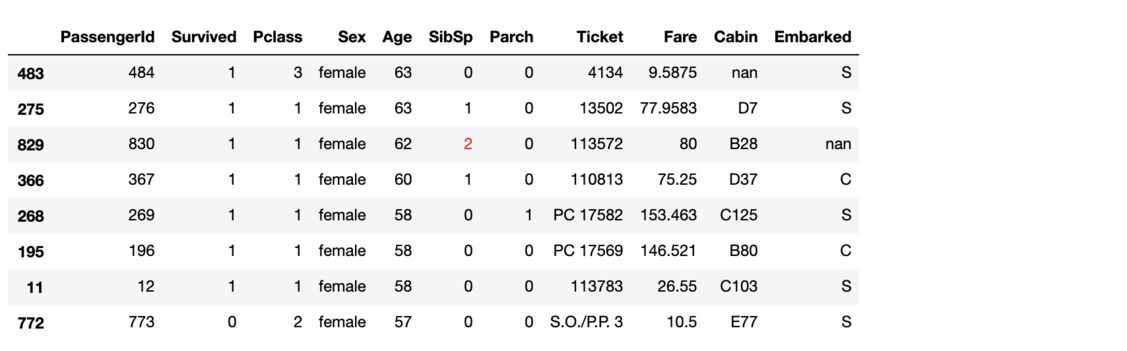
注意我剛剛在 qgrid 裡頭將 0 改成 2,而這個變動被反映到新的 DataFrame df_changed 裡頭。
pandas-profiling:你的一鍵 EDA 神器¶
廢話不多說,先附上安裝指令:
conda install -c conda-forge pandas-profiling
當碰到新的資料集時,你常會需要做 EDA 來探索並了解手上的數據。常見的基礎步驟有:
- 隨機抽樣 DataFrame 並用肉眼觀察樣本
- 了解樣本數有多少、各類型的變數有多少
- 了解 DataFrame 裡有多少空值
- 看數值欄位的分佈,欄位之間的相關係數
- 看分類型欄位的有多少不同的值,分佈為何
等等。這些在你熟悉本文的 pandas 技巧以後都應該跟吃飯喝水一樣,但很多時候就是例行公事。
這時你可以使用 pandas-profiling 讓它自動產生簡單報表,總結 DataFrame 裡的數據性質:
import pandas_profiling
df = df_titanic.copy()
# 一行報表:將想觀察的 DataFrame 丟進去就完工了
pandas_profiling.ProfileReport(df)
有了自動生成的數據分析報表,你不再需要自己寫繁瑣的程式碼就能「健檢」手上的數據集。這讓你能對數據更快地展開 domain-specific 的研究與分析,大大提升效率。
結語:實際運用所學¶
呼!本文的 pandas 旅程到此告一段落啦!
我想在其他地方你應該是找不到跟本文一樣囉哩八唆的 pandas 教學文章了。本文雖長,但涵蓋的都是我認為十分實用的 pandas 使用手法,希望你有從中學到些東西,並開始自己的數據處理與分析之旅。如果你之後想要複習,可以點開頁面左側的章節傳送門,測試自己還記得多少技巧。
接下來最重要的是培養你自己的 pandas 肌肉記憶:重複應用你在本文學到的東西,分析自己感興趣的任何數據並內化這些知識。

pandas 是一個非常強大的資料處理工具,本文雖長,仍無法涵蓋所有東西。不過你現在已經學會作為一個資料科學家所需要的所有基礎 pandas 手法。除了多加練習找手感以外,我能給你的最後一個建議就是在 Jupyter 筆記本裡頭多加利用 Shift + tab 查看 pandas 函式的 documentation,很多時候你會有新的發現。
如果你有任何其他 pandas 技巧,也請不吝留言與我分享!我懂的技巧不多,而現在輪到你教我了:)
跟資料科學相關的最新文章直接送到家。 只要加入訂閱名單,當新文章出爐時, 你將能馬上收到通知