這是一篇 BERT 科普文,帶你直觀理解並實際運用現在 NLP 領域的巨人之力。
如果你還有印象,在自然語言處理(NLP)與深度學習入門指南裡我使用了 LSTM 以及 Google 的語言代表模型 BERT 來分類中文假新聞。而最後因為 BERT 本身的強大,我不費吹灰之力就在該 Kaggle 競賽達到 85 % 的正確率,距離第一名 3 %,總排名前 30 %。

當初我是使用 TensorFlow 官方釋出的 BERT 進行 fine tuning,但使用方式並不是那麼直覺。最近適逢 PyTorch Hub 上架 BERT,李宏毅教授的機器學習課程也推出了 BERT 的教學影片,我認為現在正是你了解並實際運用 BERT 的最佳時機!
這篇文章會簡單介紹 BERT 並展示如何使用 BERT 做遷移學習(Transfer Learning)。我在文末也會提供一些有趣的研究及應用 ,讓你可以進一步探索變化快速的 NLP 世界。
如果你完全不熟 NLP 或是壓根子沒聽過什麼是 BERT,我強力建議你之後找時間(或是現在!)觀看李宏毅教授說明 ELMo、BERT 以及 GPT 等模型的影片,淺顯易懂:
我接下來會花點篇幅闡述 BERT 的基礎概念。如果你已經十分熟悉 BERT 而且迫不及待想要馬上將 BERT 應用到自己的 NLP 任務上面,可以直接跳到用 BERT fine tune 下游任務一節。
BERT:理解上下文的語言代表模型¶
一個簡單的 convention,等等文中會穿插使用的:
- 代表
- representation
- repr.
- repr. 向量
指的都是一個可以用來代表某詞彙(在某個語境下)的多維連續向量(continuous vector)。
現在在 NLP 圈混的,應該沒有人會說自己不曉得 Transformer 的經典論文 Attention Is All You Need 以及其知名的自注意力機制(Self-attention mechanism)。BERT 全名為 Bidirectional Encoder Representations from Transformers,是 Google 以無監督的方式利用大量無標註文本「煉成」的語言代表模型,其架構為 Transformer 中的 Encoder。
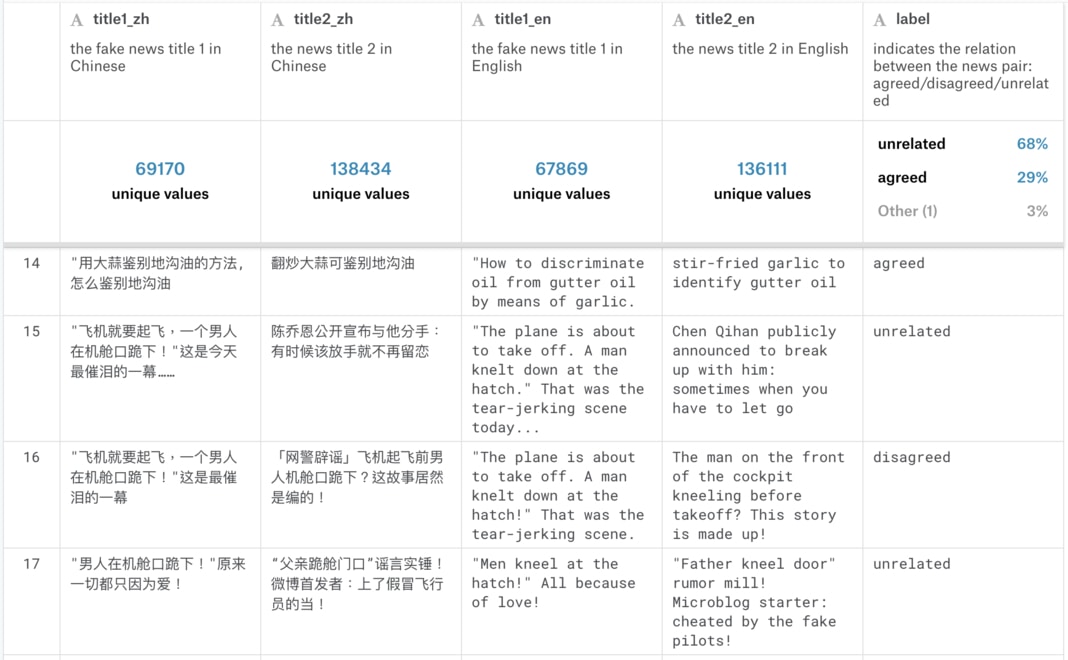
我在淺談神經機器翻譯 & 用 Transformer 英翻中一文已經鉅細靡遺地解說過所有 Transformer 的相關概念,這邊就不再贅述。
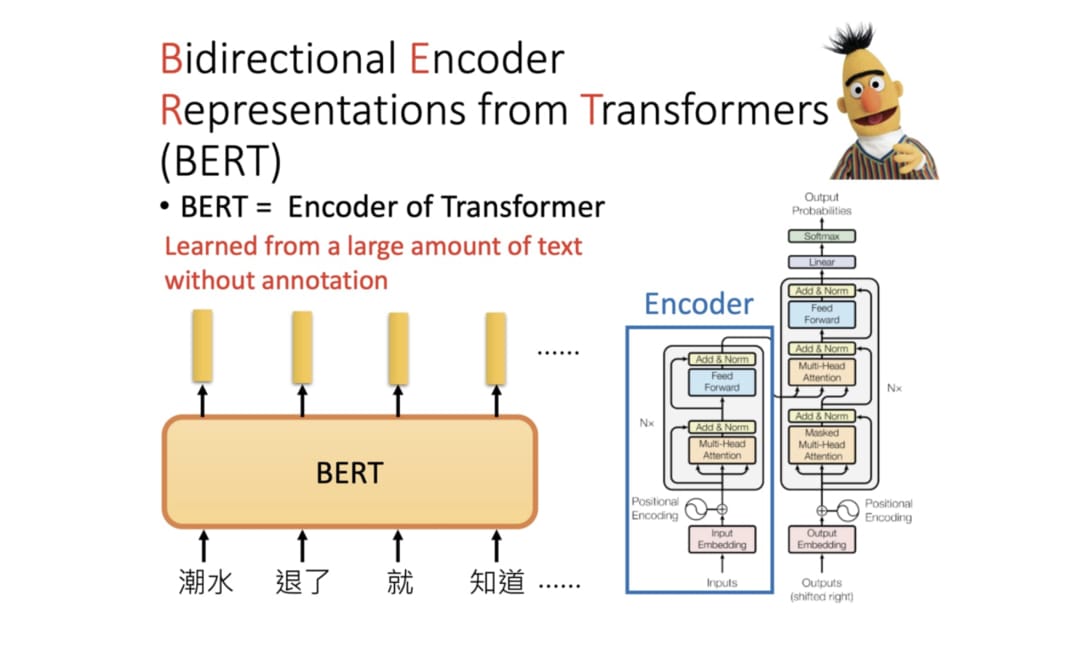
BERT 是傳統語言模型的一種變形,而語言模型(Language Model, LM)做的事情就是在給定一些詞彙的前提下, 去估計下一個詞彙出現的機率分佈。在讓 AI 給我們寫點金庸裡的 LSTM 也是一個語言模型 ,只是跟 BERT 差了很多個數量級。

為何會想要訓練一個 LM?因為有種種好處:
- 好處 1:無監督數據無限大。不像 ImageNet 還要找人標注數據,要訓練 LM 的話網路上所有文本都是你潛在的資料集(BERT 預訓練使用的數據集共有 33 億個字,其中包含維基百科及 BooksCorpus)
- 好處 2:厲害的 LM 能夠學會語法結構、解讀語義甚至指代消解。透過特徵擷取或是 fine-tuning 能更有效率地訓練下游任務並提升其表現
- 好處 3:減少處理不同 NLP 任務所需的 architecture engineering 成本
一般人很容易理解前兩點的好處,但事實上第三點的影響也十分深遠。以往為了解決不同的 NLP 任務,我們會為該任務設計一個最適合的神經網路架構並做訓練。以下是一些簡單例子:
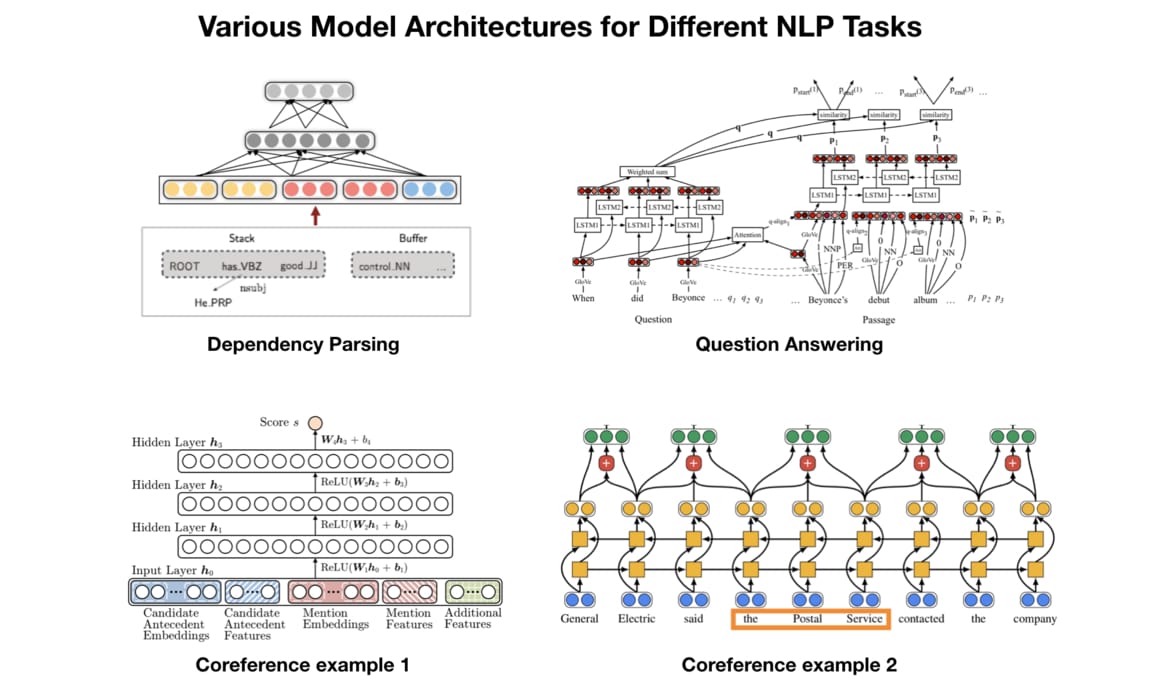
在這篇文章裡頭我不會一一介紹上述模型的運作原理,在這邊只是想讓你了解不同的 NLP 任務通常需要不同的模型,而設計這些模型並測試其 performance 是非常耗費成本的(人力、時間、計算資源)。
如果有一個能直接處理各式 NLP 任務的通用架構該有多好?
隨著時代演進,不少人很自然地有了這樣子的想法,而 BERT 就是其中一個將此概念付諸實踐的例子。BERT 論文的作者們使用 Transfomer Encoder、大量文本以及兩個預訓練目標,事先訓練好一個可以套用到多個 NLP 任務的 BERT 模型,再以此為基礎 fine tune 多個下游任務。
這就是近來 NLP 領域非常流行的兩階段遷移學習:
- 先以 LM Pretraining 的方式預先訓練出一個對自然語言有一定「理解」的通用模型
- 再將該模型拿來做特徵擷取或是 fine tune 下游的(監督式)任務
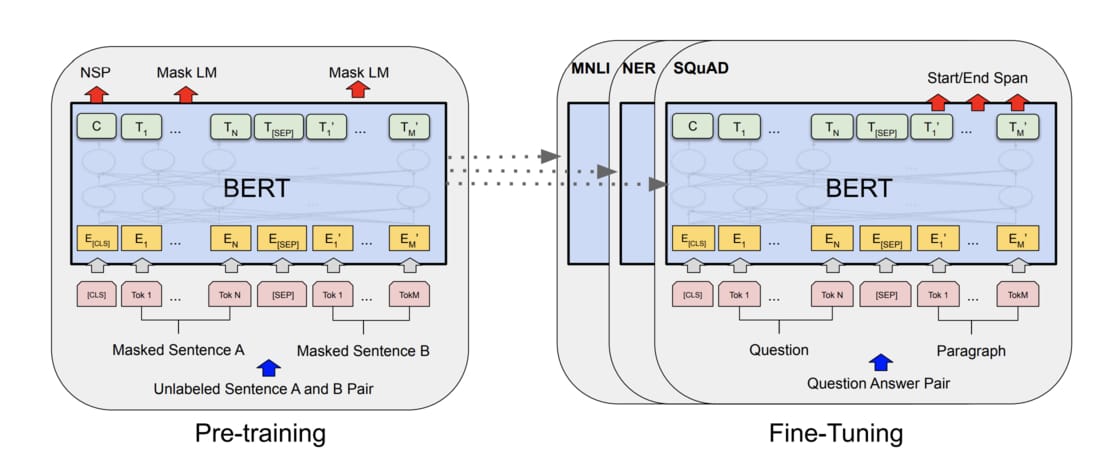
上面這個示意圖最重要的概念是預訓練步驟跟 fine-tuning 步驟所用的 BERT 是一模一樣的。當你學會使用 BERT 就能用同個架構訓練多種 NLP 任務,大大減少自己設計模型的 architecture engineering 成本,投資報酬率高到爆炸。
壞消息是,天下沒有白吃的午餐。
要訓練好一個有 1.1 億參數的 12 層 BERT-BASE 得用 16 個 TPU chips 跑上整整 4 天,花費 500 鎂;24 層的 BERT-LARGE 則有 3.4 億個參數,得用 64 個 TPU chips(約 7000 鎂)訓練。喔對,別忘了多次實驗得把這些成本乘上幾倍。最近也有 NLP 研究者呼籲大家把訓練好的模型開源釋出以減少重複訓練對環境造成的影響。
好消息是,BERT 作者們有開源釋出訓練好的模型,只要使用 TensorFlow 或是 PyTorch 將已訓練好的 BERT 載入,就能省去預訓練步驟的所有昂貴成本。好 BERT 不用嗎?
雖然一般來說我們只需要用訓練好的 BERT 做 fine-tuning,稍微瞭解預訓練步驟的內容能讓你直觀地理解它在做些什麼。
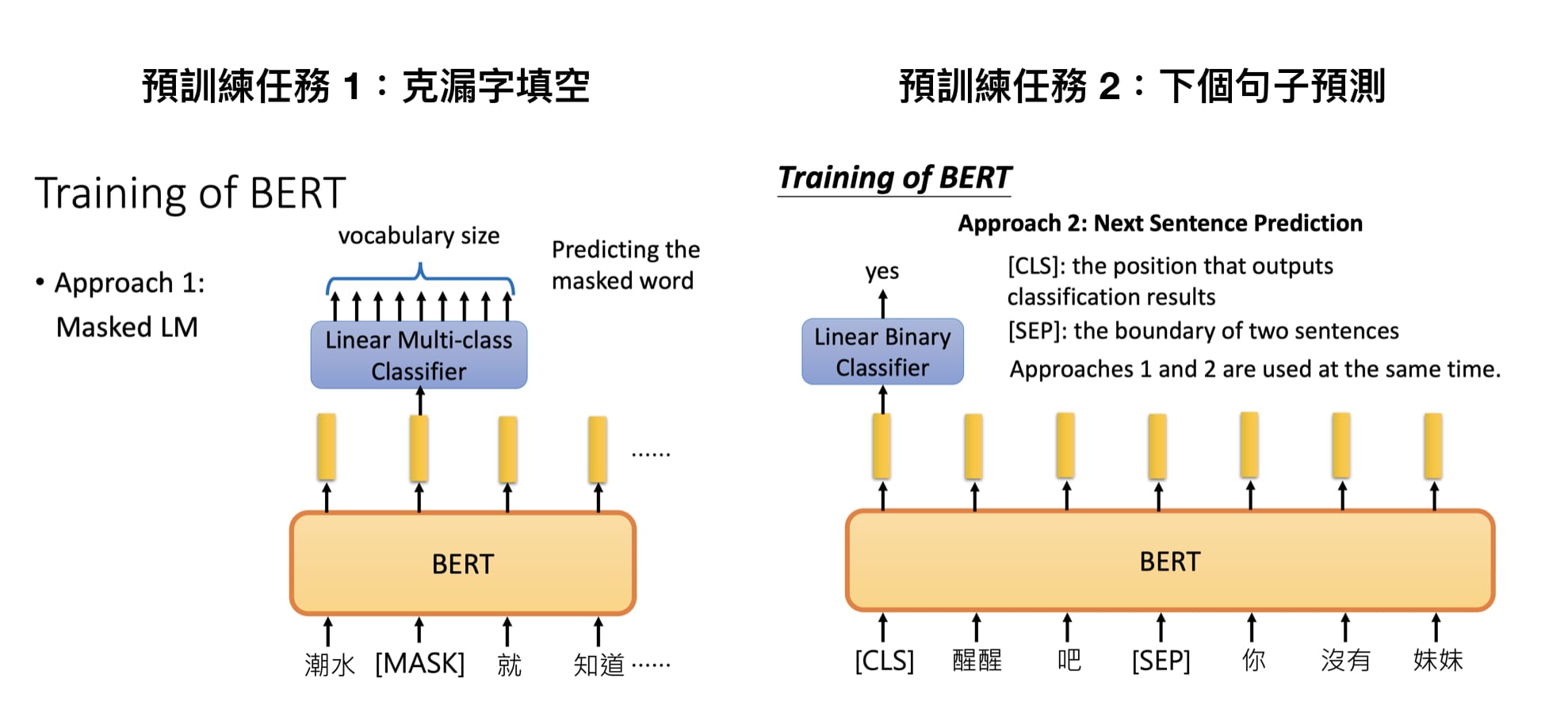
Google 在預訓練 BERT 時讓它同時進行兩個任務:
- 克漏字填空(1953 年被提出的 Cloze task,學術點的說法是 Masked Language Model, MLM)
- 判斷第 2 個句子在原始文本中是否跟第 1 個句子相接(Next Sentence Prediction, NSP)
對上通天文下知地理的鄉民們來說,要完成這兩個任務簡單到爆。只要稍微看一下前後文就能知道左邊克漏字任務的 [MASK] 裡頭該填 退了;而 醒醒吧 後面接 你沒有妹妹 也十分合情合理。
讓我們馬上載入 PyTorch Hub 上的 BERT 模型體驗看看。首先我們需要安裝一些簡單的函式庫:
(2019/10/07 更新:因應 HuggingFace 團隊最近將 GitHub 專案大翻新並更名成 transformers,本文已直接 import 該 repo 並使用新的方法調用 BERT。底下的程式碼將不再使用該團隊在 PyTorch Hub 上 host 的模型。感謝網友 Hsien 提醒)
%%bash
pip install transformers tqdm boto3 requests regex -q
接著載入中文 BERT 使用的 tokenizer:
import torch
from transformers import BertTokenizer
from IPython.display import clear_output
PRETRAINED_MODEL_NAME = "bert-base-chinese" # 指定繁簡中文 BERT-BASE 預訓練模型
# 取得此預訓練模型所使用的 tokenizer
tokenizer = BertTokenizer.from_pretrained(PRETRAINED_MODEL_NAME)
clear_output()
print("PyTorch 版本:", torch.__version__)
為了讓你直觀了解 BERT 運作,本文使用包含繁體與簡體中文的預訓練模型。 你可以在 Hugging Face 團隊的 repo 裡看到所有可從 PyTorch Hub 載入的 BERT 預訓練模型。截至目前為止有以下模型可供使用:
- bert-base-chinese
- bert-base-uncased
- bert-base-cased
- bert-base-german-cased
- bert-base-multilingual-uncased
- bert-base-multilingual-cased
- bert-large-cased
- bert-large-uncased
- bert-large-uncased-whole-word-masking
- bert-large-cased-whole-word-masking
這些模型的參數都已經被訓練完成,而主要差別在於:
- 預訓練步驟時用的文本語言
- 有無分大小寫
- 層數的不同
- 預訓練時遮住 wordpieces 或是整個 word
除了本文使用的中文 BERT 以外,常被拿來應用與研究的是英文的 bert-base-cased 模型。
現在讓我們看看 tokenizer 裡頭的字典資訊:
vocab = tokenizer.vocab
print("字典大小:", len(vocab))
如上所示,中文 BERT 的字典大小約有 2.1 萬個 tokens。沒記錯的話,英文 BERT 的字典則大約是 3 萬 tokens 左右。我們可以瞧瞧中文 BERT 字典裡頭紀錄的一些 tokens 以及其對應的索引:
import random
random_tokens = random.sample(list(vocab), 10)
random_ids = [vocab[t] for t in random_tokens]
print("{0:20}{1:15}".format("token", "index"))
print("-" * 25)
for t, id in zip(random_tokens, random_ids):
print("{0:15}{1:10}".format(t, id))
BERT 使用當初 Google NMT 提出的 WordPiece Tokenization ,將本來的 words 拆成更小粒度的 wordpieces,有效處理不在字典裡頭的詞彙 。中文的話大致上就像是 character-level tokenization,而有 ## 前綴的 tokens 即為 wordpieces。
以詞彙 fragment 來說,其可以被拆成 frag 與 ##ment 兩個 pieces,而一個 word 也可以獨自形成一個 wordpiece。wordpieces 可以由蒐集大量文本並找出其中常見的 pattern 取得。
另外有趣的是ㄅㄆㄇㄈ也有被收錄:
indices = list(range(647, 657))
some_pairs = [(t, idx) for t, idx in vocab.items() if idx in indices]
for pair in some_pairs:
print(pair)
讓我們利用中文 BERT 的 tokenizer 將一個中文句子斷詞看看:
text = "[CLS] 等到潮水 [MASK] 了,就知道誰沒穿褲子。"
tokens = tokenizer.tokenize(text)
ids = tokenizer.convert_tokens_to_ids(tokens)
print(text)
print(tokens[:10], '...')
print(ids[:10], '...')
除了一般的 wordpieces 以外,BERT 裡頭有 5 個特殊 tokens 各司其職:
[CLS]:在做分類任務時其最後一層的 repr. 會被視為整個輸入序列的 repr.[SEP]:有兩個句子的文本會被串接成一個輸入序列,並在兩句之間插入這個 token 以做區隔[UNK]:沒出現在 BERT 字典裡頭的字會被這個 token 取代[PAD]:zero padding 遮罩,將長度不一的輸入序列補齊方便做 batch 運算[MASK]:未知遮罩,僅在預訓練階段會用到
如上例所示,[CLS] 一般會被放在輸入序列的最前面,而 zero padding 在之前的 Transformer 文章裡已經有非常詳細的介紹。[MASK] token 一般在 fine-tuning 或是 feature extraction 時不會用到,這邊只是為了展示預訓練階段的克漏字任務才使用的。
現在馬上讓我們看看給定上面有 [MASK] 的句子,BERT 會填入什麼字:
"""
這段程式碼載入已經訓練好的 masked 語言模型並對有 [MASK] 的句子做預測
"""
from transformers import BertForMaskedLM
# 除了 tokens 以外我們還需要辨別句子的 segment ids
tokens_tensor = torch.tensor([ids]) # (1, seq_len)
segments_tensors = torch.zeros_like(tokens_tensor) # (1, seq_len)
maskedLM_model = BertForMaskedLM.from_pretrained(PRETRAINED_MODEL_NAME)
clear_output()
# 使用 masked LM 估計 [MASK] 位置所代表的實際 token
maskedLM_model.eval()
with torch.no_grad():
outputs = maskedLM_model(tokens_tensor, segments_tensors)
predictions = outputs[0]
# (1, seq_len, num_hidden_units)
del maskedLM_model
# 將 [MASK] 位置的機率分佈取 top k 最有可能的 tokens 出來
masked_index = 5
k = 3
probs, indices = torch.topk(torch.softmax(predictions[0, masked_index], -1), k)
predicted_tokens = tokenizer.convert_ids_to_tokens(indices.tolist())
# 顯示 top k 可能的字。一般我們就是取 top 1 當作預測值
print("輸入 tokens :", tokens[:10], '...')
print('-' * 50)
for i, (t, p) in enumerate(zip(predicted_tokens, probs), 1):
tokens[masked_index] = t
print("Top {} ({:2}%):{}".format(i, int(p.item() * 100), tokens[:10]), '...')
Google 在訓練中文 BERT 鐵定沒看批踢踢,還無法預測出我們最想要的那個 退 字。而最接近的 過 的出現機率只有 2%,但我會說以語言代表模型以及自然語言理解的角度來看這結果已經不差了。BERT 透過關注 潮 與 水 這兩個字,從 2 萬多個 wordpieces 的可能性中選出 來 作為這個情境下 [MASK] token 的預測值 ,也還算說的過去。
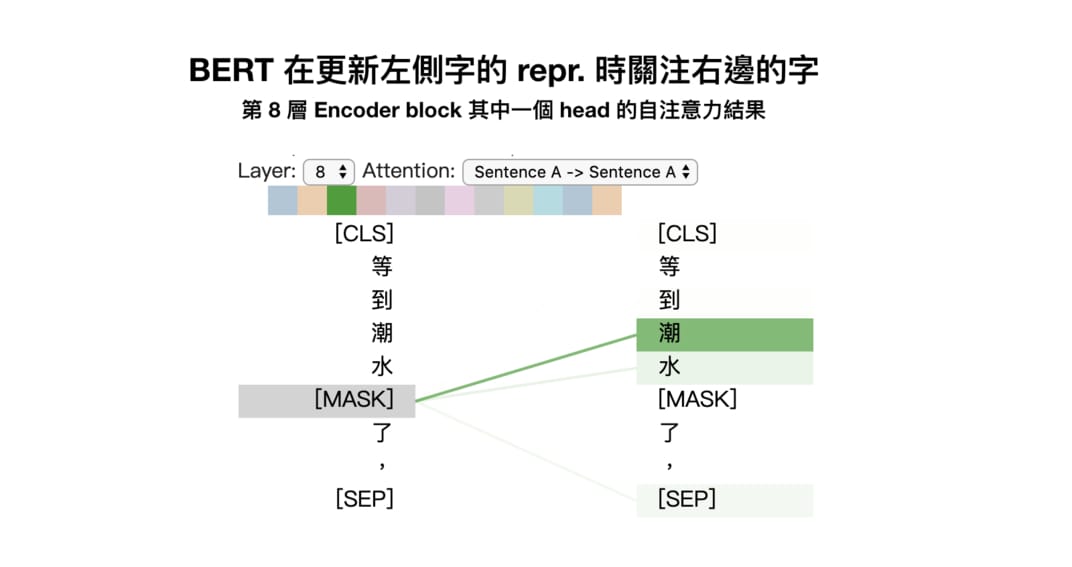
這是 BertViz 視覺化 BERT 注意力的結果,我等等會列出安裝步驟讓你自己玩玩。值得一提的是,以上是第 8 層 Encoder block 中 Multi-head attention 裡頭某一個 head 的自注意力結果。並不是每個 head 都會關注在一樣的位置。透過 multi-head 自注意力機制,BERT 可以讓不同 heads 在不同的 representation subspaces 裡學會關注不同位置的不同 repr.。
學會填克漏字讓 BERT 更好地 model 每個詞彙在不同語境下該有的 repr.,而 NSP 任務則能幫助 BERT model 兩個句子之間的關係,這在問答系統 QA、自然語言推論 NLI 或是後面我們會看到的假新聞分類任務都很有幫助。
這樣的 word repr. 就是近年十分盛行的 contextual word representation 概念。跟以往沒有蘊含上下文資訊的 Word2Vec、GloVe 等無語境的詞嵌入向量有很大的差異。用稍微學術一點的說法就是:
Contextual word repr. 讓同 word type 的 word token 在不同語境下有不同的表示方式;而傳統的詞向量無論上下文,都會讓同 type 的 word token 的 repr. 相同。
直覺上 contextual word representation 比較能反映人類語言的真實情況,畢竟同個詞彙的含義在不同情境下相異是再正常不過的事情。在不同語境下給同個詞彙相同的 word repr. 這件事情在近年的 NLP 領域裡頭顯得越來越不合理。
為了讓你加深印象,讓我再舉個具體的例子:
情境 1:
胖虎叫大雄去買漫畫,回來慢了就打他。
情境 2:
妹妹說胖虎是「胖子」,他聽了很不開心。
很明顯地,在這兩個情境裡頭「他」所代表的語義以及指稱的對象皆不同。如果仍使用沒蘊含上下文 / 語境資訊的詞向量,機器就會很難正確地「解讀」這兩個句子所蘊含的語義了。
現在讓我們跟隨這個 Colab 筆記本安裝 BERT 的視覺化工具 BertViz,看看 BERT 會怎麼處理這兩個情境:
# 安裝 BertViz
import sys
!test -d bertviz_repo || git clone https://github.com/jessevig/bertviz bertviz_repo
if not 'bertviz_repo' in sys.path:
sys.path += ['bertviz_repo']
# import packages
from transformers import BertTokenizer, BertModel
from bertviz import head_view
# 在 jupyter notebook 裡頭顯示 visualzation 的 helper
def call_html():
import IPython
display(IPython.core.display.HTML('''
<script src="/static/components/requirejs/require.js"></script>
<script>
requirejs.config({
paths: {
base: '/static/base',
"d3": "https://cdnjs.cloudflare.com/ajax/libs/d3/3.5.8/d3.min",
jquery: '//ajax.googleapis.com/ajax/libs/jquery/2.0.0/jquery.min',
},
});
</script>
'''))
clear_output()
Setup 以後就能非常輕鬆地將 BERT 內部的注意力機制視覺化出來:
# 記得我們是使用中文 BERT
model_version = 'bert-base-chinese'
model = BertModel.from_pretrained(model_version, output_attentions=True)
tokenizer = BertTokenizer.from_pretrained(model_version)
# 情境 1 的句子
sentence_a = "胖虎叫大雄去買漫畫,"
sentence_b = "回來慢了就打他。"
# 得到 tokens 後丟入 BERT 取得 attention
inputs = tokenizer.encode_plus(sentence_a, sentence_b, return_tensors='pt', add_special_tokens=True)
token_type_ids = inputs['token_type_ids']
input_ids = inputs['input_ids']
attention = model(input_ids, token_type_ids=token_type_ids)[-1]
input_id_list = input_ids[0].tolist() # Batch index 0
tokens = tokenizer.convert_ids_to_tokens(input_id_list)
call_html()
# 交給 BertViz 視覺化
head_view(attention, tokens)
# 注意:執行這段程式碼以後只會顯示下圖左側的結果。
# 為了方便你比較,我把情境 2 的結果也同時附上
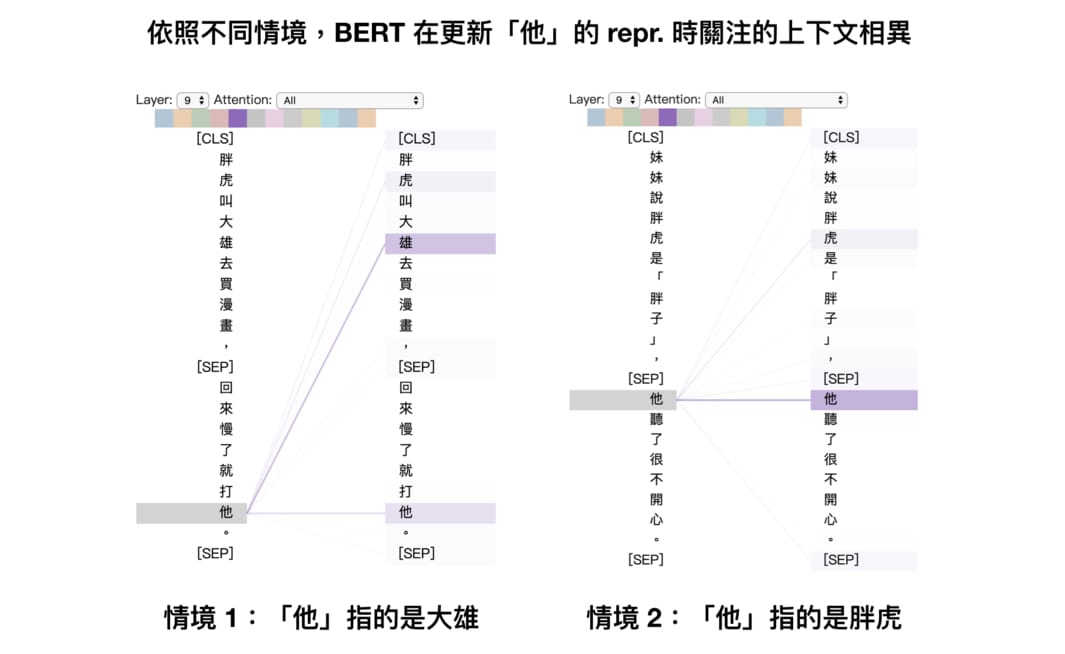
這是 BERT 裡第 9 層 Encoder block 其中一個 head 的注意力結果。
圖中的線條代表該 head 在更新「他」(左側)的 repr. 時關注其他詞彙(右側)的注意力程度。越粗代表關注權重(attention weights)越高。很明顯地這個 head 具有一定的指代消解(Coreference Resolution)能力,能正確地關注「他」所指代的對象。
要處理指代消解需要對自然語言有不少理解,而 BERT 在沒有標注數據的情況下透過自注意力機制、深度雙向語言模型以及「閱讀」大量文本達到這樣的水準,是一件令人雀躍的事情。
當然 BERT 並不是第一個嘗試產生 contextual word repr. 的語言模型。在它之前最知名的例子有剛剛提到的 ELMo 以及 GPT:
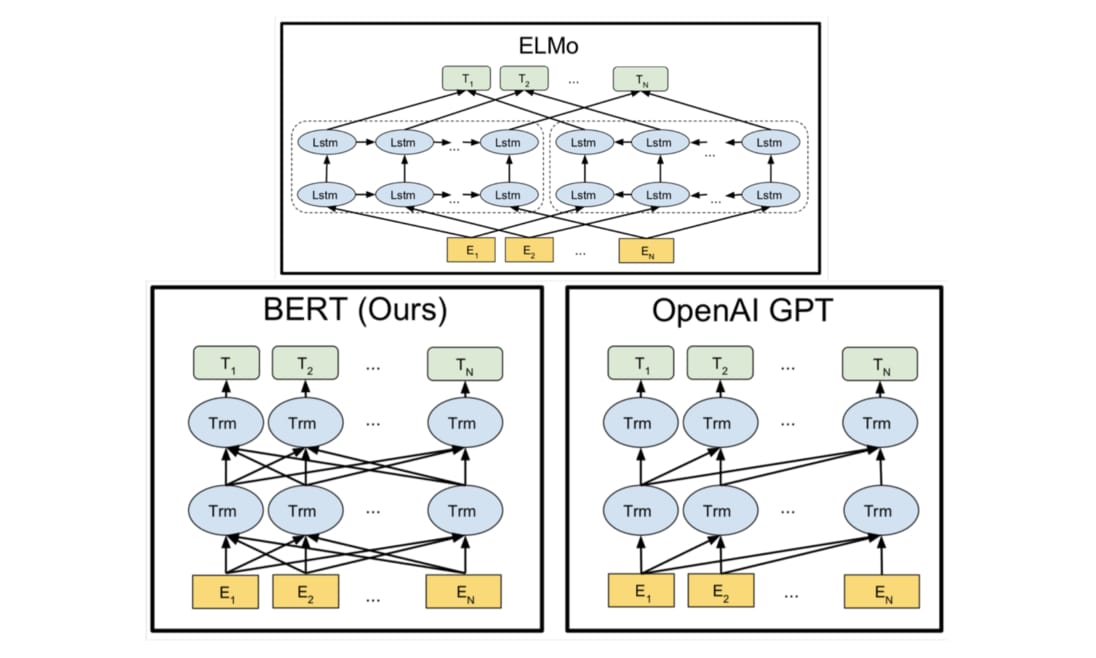
ELMo 利用獨立訓練的雙向兩層 LSTM 做語言模型並將中間得到的隱狀態向量串接當作每個詞彙的 contextual word repr.;GPT 則是使用 Transformer 的 Decoder 來訓練一個中規中矩,從左到右的單向語言模型。你可以參考我另一篇文章:直觀理解 GPT-2 語言模型並生成金庸武俠小說來深入了解 GPT 與 GPT-2。
BERT 跟它們的差異在於利用 MLM(即克漏字)的概念及 Transformer Encoder 的架構,擺脫以往語言模型只能從單個方向(由左到右或由右到左)估計下個詞彙出現機率的窘境,訓練出一個雙向的語言代表模型。這使得 BERT 輸出的每個 token 的 repr. Tn 都同時蘊含了前後文資訊,真正的雙向 representation。
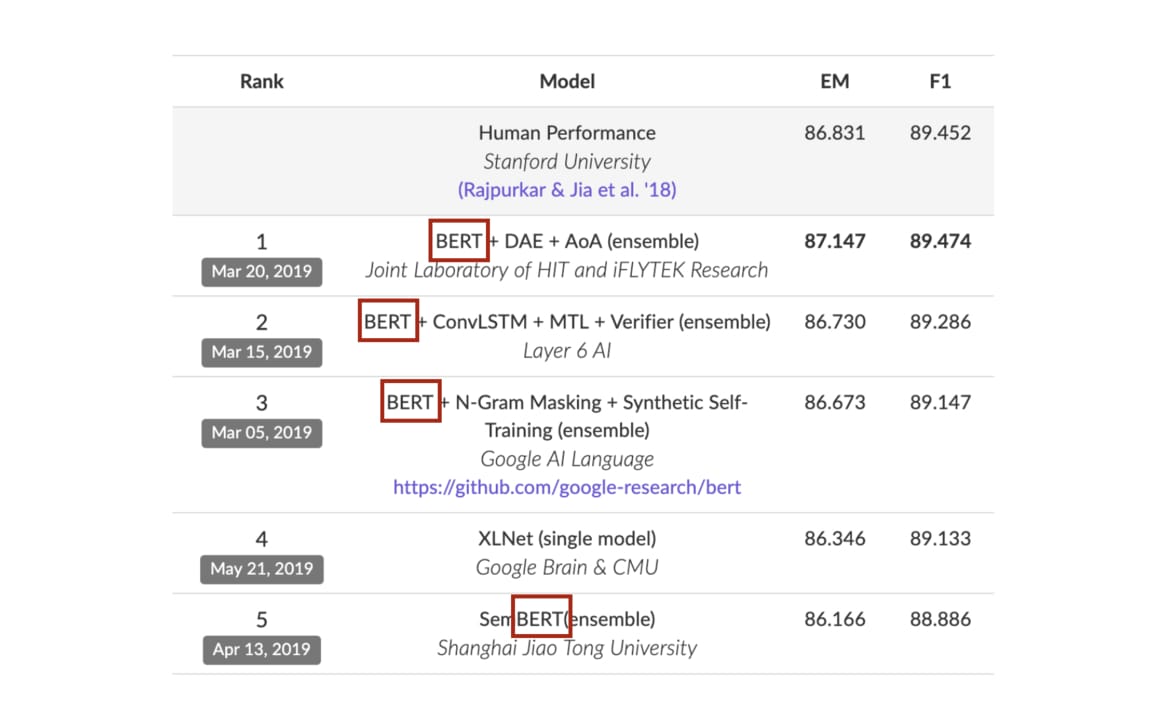
跟以往模型相比,BERT 能更好地處理自然語言,在著名的問答任務 SQuAD2.0 也有卓越表現:
我想我又犯了解說癖,這些東西你可能在看這篇文章之前就全懂了。但希望這些對 BERT 的 high level 介紹能幫助更多人直覺地理解 BERT 的強大之處以及為何值得學習它。
假如你仍然似懂非懂,只需記得:
BERT 是一個強大的語言代表模型,給它一段文本序列,它能回傳一段相同長度且蘊含上下文資訊的 word repr. 序列,對下游的 NLP 任務很有幫助。
有了這樣的概念以後,我們接下來要做的事情很簡單,就是將自己感興趣的 NLP 任務的文本丟入 BERT ,為文本裡頭的每個 token 取得有語境的 word repr.,並以此 repr. 進一步 fine tune 當前任務,取得更好的結果。
用 BERT fine tune 下游任務¶
我們在給所有人的 NLP 入門指南碰過的假新聞分類任務將會是本文拿 BERT 來做 fine-tuning 的例子。選擇這個任務的最主要理由是因為中文數據容易理解,另外網路上針對兩個句子做分類的例子也較少。
就算你對假新聞分類沒興趣也建議繼續閱讀。因為本節談到的所有概念完全可以被套用到其他語言的文本以及不同的 NLP 任務之上。因此我希望接下來你能一邊閱讀一邊想像如何用同樣的方式把 BERT 拿來處理你自己感興趣的 NLP 任務。
fine tune BERT 來解決新的下游任務有 5 個簡單步驟:
對,就是那麼直覺。而且你應該已經看出步驟 1、4 及 5 都跟訓練一般模型所需的步驟無太大差異。跟 BERT 最相關的細節事實上是步驟 2 跟 3:
- 如何將原始數據轉換成 BERT 相容的輸入格式?
- 如何在 BERT 之上建立 layer(s) 以符合下游任務需求?
事不宜遲,讓我們馬上以假新聞分類任務為例回答這些問題。我在之前的文章已經說明過,這個任務的輸入是兩個句子,輸出是 3 個類別機率的多類別分類任務(multi-class classification task),跟 NLP 領域裡常見的自然語言推論(Natural Language Inference)具有相同性質。
1. 準備原始文本數據¶
為了最大化再現性(reproducibility)以及幫助有興趣的讀者深入研究,我會列出所有的程式碼,你只要複製貼上就能完整重現文中所有結果並生成能提交到 Kaggle 競賽的預測檔案。你當然也可以選擇直接閱讀,不一定要下載數據。
因為 Kaggle 網站本身的限制,我無法直接提供數據載點。如果你想要跟著本文練習以 BERT fine tune 一個假新聞的分類模型,可以先前往該 Kaggle 競賽下載資料集。下載完數據你的資料夾裡應該會有兩個壓縮檔,分別代表訓練集和測試集:
import glob
glob.glob("*.csv.zip")
接著就是我實際處理訓練資料集的程式碼。再次申明,你只需稍微瀏覽註解並感受一下處理邏輯即可,no pressure。
因為競賽早就結束,我們不必花費時間衝高分數。比起衝高準確度,讓我們做點有趣的事情:從 32 萬筆訓練數據裡頭隨機抽樣 1 % 來讓 BERT 學怎麼分類假新聞。
我們可以看看 BERT 本身的語言理解能力對只有少量標註數據的任務有什麼幫助:
"""
前處理原始的訓練數據集。
你不需了解細節,只需要看註解了解邏輯或是輸出的數據格式即可
"""
import os
import pandas as pd
# 解壓縮從 Kaggle 競賽下載的訓練壓縮檔案
os.system("unzip train.csv.zip")
# 簡單的數據清理,去除空白標題的 examples
df_train = pd.read_csv("train.csv")
empty_title = ((df_train['title2_zh'].isnull()) \
| (df_train['title1_zh'].isnull()) \
| (df_train['title2_zh'] == '') \
| (df_train['title2_zh'] == '0'))
df_train = df_train[~empty_title]
# 剔除過長的樣本以避免 BERT 無法將整個輸入序列放入記憶體不多的 GPU
MAX_LENGTH = 30
df_train = df_train[~(df_train.title1_zh.apply(lambda x : len(x)) > MAX_LENGTH)]
df_train = df_train[~(df_train.title2_zh.apply(lambda x : len(x)) > MAX_LENGTH)]
# 只用 1% 訓練數據看看 BERT 對少量標註數據有多少幫助
SAMPLE_FRAC = 0.01
df_train = df_train.sample(frac=SAMPLE_FRAC, random_state=9527)
# 去除不必要的欄位並重新命名兩標題的欄位名
df_train = df_train.reset_index()
df_train = df_train.loc[:, ['title1_zh', 'title2_zh', 'label']]
df_train.columns = ['text_a', 'text_b', 'label']
# idempotence, 將處理結果另存成 tsv 供 PyTorch 使用
df_train.to_csv("train.tsv", sep="\t", index=False)
print("訓練樣本數:", len(df_train))
df_train.head()

事情變得更有趣了。因為我們在抽樣 1 % 的數據後還將過長的樣本去除,實際上會被拿來訓練的樣本數只有 2,657 筆,佔不到參賽時可以用的訓練數據的 1 %,是非常少量的數據。
我們也可以看到 unrelated 的樣本佔了 68 %,因此我們用 BERT 訓練出來的分類器最少最少要超過多數決的 68 % baseline 才行:
df_train.label.value_counts() / len(df_train)
接著我也對最後要預測的測試集做些非常基本的前處理,方便之後提交符合競賽要求的格式。你也不需了解所有細節,只要知道我們最後要預測 8 萬筆樣本:
os.system("unzip test.csv.zip")
df_test = pd.read_csv("test.csv")
df_test = df_test.loc[:, ["title1_zh", "title2_zh", "id"]]
df_test.columns = ["text_a", "text_b", "Id"]
df_test.to_csv("test.tsv", sep="\t", index=False)
print("預測樣本數:", len(df_test))
df_test.head()

ratio = len(df_test) / len(df_train)
print("測試集樣本數 / 訓練集樣本數 = {:.1f} 倍".format(ratio))
因為測試集的樣本數是我們迷你訓練集的 30 倍之多,後面你會看到反而是推論需要花費比較久的時間,模型本身一下就訓練完了。
2. 將原始文本轉換成 BERT 相容的輸入格式¶
處理完原始數據以後,最關鍵的就是了解如何讓 BERT 讀取這些數據以做訓練和推論。這時候我們需要了解 BERT 的輸入編碼格式。
這步驟是本文的精華所在,你將看到在其他只單純說明 BERT 概念的文章不會提及的所有實務細節。以下是原論文裡頭展示的成對句子編碼示意圖:
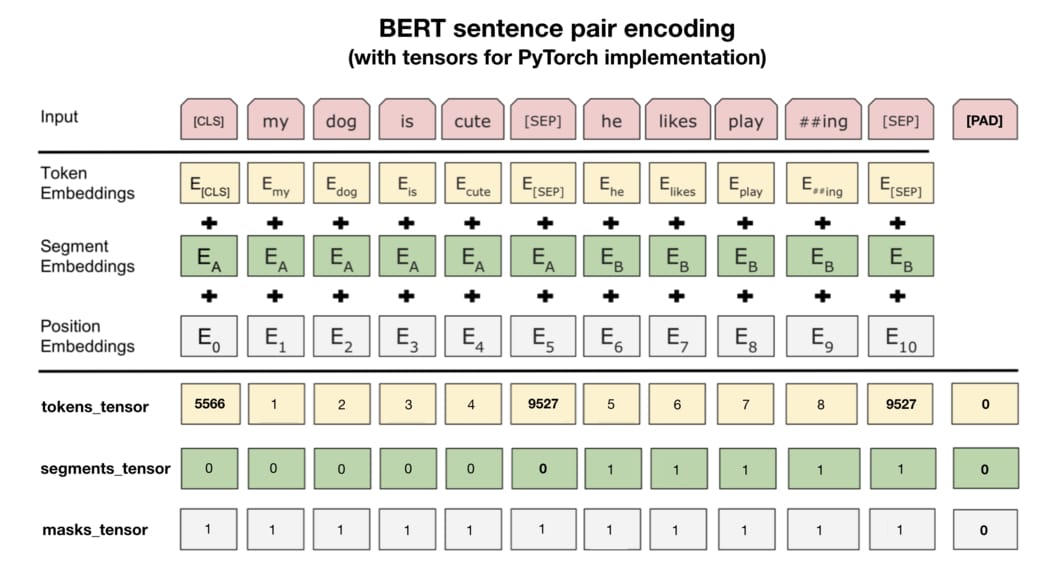
第二條分隔線之上的內容是論文裡展示的例子。圖中的每個 Token Embedding 都對應到前面提過的一個 wordpiece,而 Segment Embeddings 則代表不同句子的位置,是學出來的。Positional Embeddings 則跟其他 Transformer 架構中出現的位置編碼同出一轍。
實際運用 PyTorch 的 BERT 時最重要的則是在第二條分隔線之下的資訊。我們需要將原始文本轉換成 3 種 id tensors:
tokens_tensor:代表識別每個 token 的索引值,用 tokenizer 轉換即可segments_tensor:用來識別句子界限。第一句為 0,第二句則為 1。另外注意句子間的[SEP]為 0masks_tensor:用來界定自注意力機制範圍。1 讓 BERT 關注該位置,0 則代表是 padding 不需關注
論文裡的例子並沒有說明 [PAD] token,但實務上每個 batch 裡頭的輸入序列長短不一,為了讓 GPU 平行運算我們需要將 batch 裡的每個輸入序列都補上 zero padding 以保證它們長度一致。另外 masks_tensor 以及 segments_tensor 在 [PAD] 對應位置的值也都是 0,切記切記。
有了這些背景知識以後,要實作一個 Dataset 並將原始文本轉換成 BERT 相容的格式就變得十分容易了:
"""
實作一個可以用來讀取訓練 / 測試集的 Dataset,這是你需要徹底了解的部分。
此 Dataset 每次將 tsv 裡的一筆成對句子轉換成 BERT 相容的格式,並回傳 3 個 tensors:
- tokens_tensor:兩個句子合併後的索引序列,包含 [CLS] 與 [SEP]
- segments_tensor:可以用來識別兩個句子界限的 binary tensor
- label_tensor:將分類標籤轉換成類別索引的 tensor, 如果是測試集則回傳 None
"""
from torch.utils.data import Dataset
class FakeNewsDataset(Dataset):
# 讀取前處理後的 tsv 檔並初始化一些參數
def __init__(self, mode, tokenizer):
assert mode in ["train", "test"] # 一般訓練你會需要 dev set
self.mode = mode
# 大數據你會需要用 iterator=True
self.df = pd.read_csv(mode + ".tsv", sep="\t").fillna("")
self.len = len(self.df)
self.label_map = {'agreed': 0, 'disagreed': 1, 'unrelated': 2}
self.tokenizer = tokenizer # 我們將使用 BERT tokenizer
# 定義回傳一筆訓練 / 測試數據的函式
def __getitem__(self, idx):
if self.mode == "test":
text_a, text_b = self.df.iloc[idx, :2].values
label_tensor = None
else:
text_a, text_b, label = self.df.iloc[idx, :].values
# 將 label 文字也轉換成索引方便轉換成 tensor
label_id = self.label_map[label]
label_tensor = torch.tensor(label_id)
# 建立第一個句子的 BERT tokens 並加入分隔符號 [SEP]
word_pieces = ["[CLS]"]
tokens_a = self.tokenizer.tokenize(text_a)
word_pieces += tokens_a + ["[SEP]"]
len_a = len(word_pieces)
# 第二個句子的 BERT tokens
tokens_b = self.tokenizer.tokenize(text_b)
word_pieces += tokens_b + ["[SEP]"]
len_b = len(word_pieces) - len_a
# 將整個 token 序列轉換成索引序列
ids = self.tokenizer.convert_tokens_to_ids(word_pieces)
tokens_tensor = torch.tensor(ids)
# 將第一句包含 [SEP] 的 token 位置設為 0,其他為 1 表示第二句
segments_tensor = torch.tensor([0] * len_a + [1] * len_b,
dtype=torch.long)
return (tokens_tensor, segments_tensor, label_tensor)
def __len__(self):
return self.len
# 初始化一個專門讀取訓練樣本的 Dataset,使用中文 BERT 斷詞
trainset = FakeNewsDataset("train", tokenizer=tokenizer)
這段程式碼不難,我也很想硬掰些台詞撐撐場面,但該說的重點都寫成註解給你看了。如果你想要把自己手上的文本轉換成 BERT 看得懂的東西,那徹底理解這個 Dataset 的實作邏輯就非常重要了。
現在讓我們看看第一個訓練樣本轉換前後的格式差異:
# 選擇第一個樣本
sample_idx = 0
# 將原始文本拿出做比較
text_a, text_b, label = trainset.df.iloc[sample_idx].values
# 利用剛剛建立的 Dataset 取出轉換後的 id tensors
tokens_tensor, segments_tensor, label_tensor = trainset[sample_idx]
# 將 tokens_tensor 還原成文本
tokens = tokenizer.convert_ids_to_tokens(tokens_tensor.tolist())
combined_text = "".join(tokens)
# 渲染前後差異,毫無反應就是個 print。可以直接看輸出結果
print(f"""[原始文本]
句子 1:{text_a}
句子 2:{text_b}
分類 :{label}
--------------------
[Dataset 回傳的 tensors]
tokens_tensor :{tokens_tensor}
segments_tensor:{segments_tensor}
label_tensor :{label_tensor}
--------------------
[還原 tokens_tensors]
{combined_text}
""")
好啦,我很雞婆地幫你把處理前後的差異都列了出來,你現在應該了解我們定義的 trainset 回傳的 tensors 跟原始文本之間的關係了吧!如果你之後想要一行行解析上面我定義的這個 Dataset,強烈建議安裝在 Github 上已經得到超過 1 萬星的 PySnooper:
!pip install pysnooper -q
import pysnooper
class FakeNewsDataset(Dataset):
...
@pysnooper.snoop() # 加入以了解所有轉換過程
def __getitem__(self, idx):
...
加上 @pysnooper.snoop()、重新定義 FakeNewsDataset、初始化一個新的 trainset 並將第一個樣本取出即可看到這樣的 logging 訊息:

有了 Dataset 以後,我們還需要一個 DataLoader 來回傳成一個個的 mini-batch。畢竟我們不可能一次把整個數據集塞入 GPU,對吧?
痾 ... 你剛剛應該沒有打算這麼做吧?
除了上面的 FakeNewsDataset 實作以外,以下的程式碼是你在想將 BERT 應用到自己的 NLP 任務時會需要徹底搞懂的部分:
"""
實作可以一次回傳一個 mini-batch 的 DataLoader
這個 DataLoader 吃我們上面定義的 `FakeNewsDataset`,
回傳訓練 BERT 時會需要的 4 個 tensors:
- tokens_tensors : (batch_size, max_seq_len_in_batch)
- segments_tensors: (batch_size, max_seq_len_in_batch)
- masks_tensors : (batch_size, max_seq_len_in_batch)
- label_ids : (batch_size)
"""
from torch.utils.data import DataLoader
from torch.nn.utils.rnn import pad_sequence
# 這個函式的輸入 `samples` 是一個 list,裡頭的每個 element 都是
# 剛剛定義的 `FakeNewsDataset` 回傳的一個樣本,每個樣本都包含 3 tensors:
# - tokens_tensor
# - segments_tensor
# - label_tensor
# 它會對前兩個 tensors 作 zero padding,並產生前面說明過的 masks_tensors
def create_mini_batch(samples):
tokens_tensors = [s[0] for s in samples]
segments_tensors = [s[1] for s in samples]
# 測試集有 labels
if samples[0][2] is not None:
label_ids = torch.stack([s[2] for s in samples])
else:
label_ids = None
# zero pad 到同一序列長度
tokens_tensors = pad_sequence(tokens_tensors,
batch_first=True)
segments_tensors = pad_sequence(segments_tensors,
batch_first=True)
# attention masks,將 tokens_tensors 裡頭不為 zero padding
# 的位置設為 1 讓 BERT 只關注這些位置的 tokens
masks_tensors = torch.zeros(tokens_tensors.shape,
dtype=torch.long)
masks_tensors = masks_tensors.masked_fill(
tokens_tensors != 0, 1)
return tokens_tensors, segments_tensors, masks_tensors, label_ids
# 初始化一個每次回傳 64 個訓練樣本的 DataLoader
# 利用 `collate_fn` 將 list of samples 合併成一個 mini-batch 是關鍵
BATCH_SIZE = 64
trainloader = DataLoader(trainset, batch_size=BATCH_SIZE,
collate_fn=create_mini_batch)
加上註解,我相信這應該是你在整個網路上能看到最平易近人的實作了。這段程式碼是你要實際將 mini-batch 丟入 BERT 做訓練以及預測的關鍵,務必搞清楚每一行在做些什麼。
有了可以回傳 mini-batch 的 DataLoader 後,讓我們馬上拿出一個 batch 看看:
data = next(iter(trainloader))
tokens_tensors, segments_tensors, \
masks_tensors, label_ids = data
print(f"""
tokens_tensors.shape = {tokens_tensors.shape}
{tokens_tensors}
------------------------
segments_tensors.shape = {segments_tensors.shape}
{segments_tensors}
------------------------
masks_tensors.shape = {masks_tensors.shape}
{masks_tensors}
------------------------
label_ids.shape = {label_ids.shape}
{label_ids}
""")
建立 BERT 用的 mini-batch 時最需要注意的就是 zero padding 的存在了。你可以發現除了 lable_ids 以外,其他 3 個 tensors 的每個樣本的最後大都為 0,這是因為每個樣本的 tokens 序列基本上長度都會不同,需要補 padding。
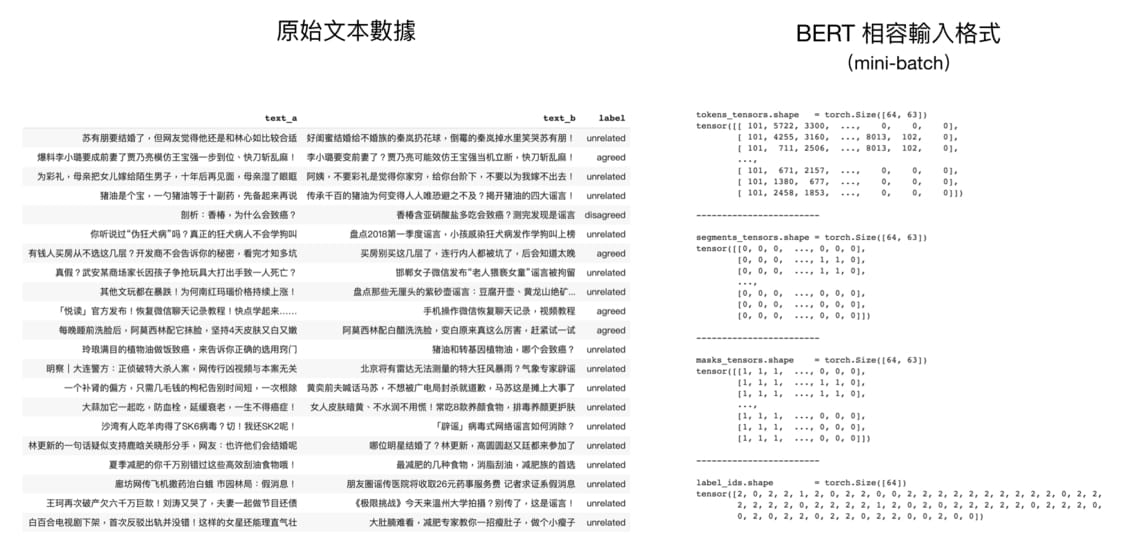
到此為止我們已經成功地將原始文本轉換成 BERT 相容的輸入格式了。這節是本篇文章最重要,也最需要花點時間咀嚼的內容。在有這些 tensors 的前提下,要在 BERT 之上訓練我們自己的下游任務完全是一塊蛋糕。
3. 在 BERT 之上加入新 layer 成下游任務模型¶
我從李宏毅教授講解 BERT 的投影片中擷取出原論文提到的 4 種 fine-tuning BERT 情境,並整合了一些有用資訊:
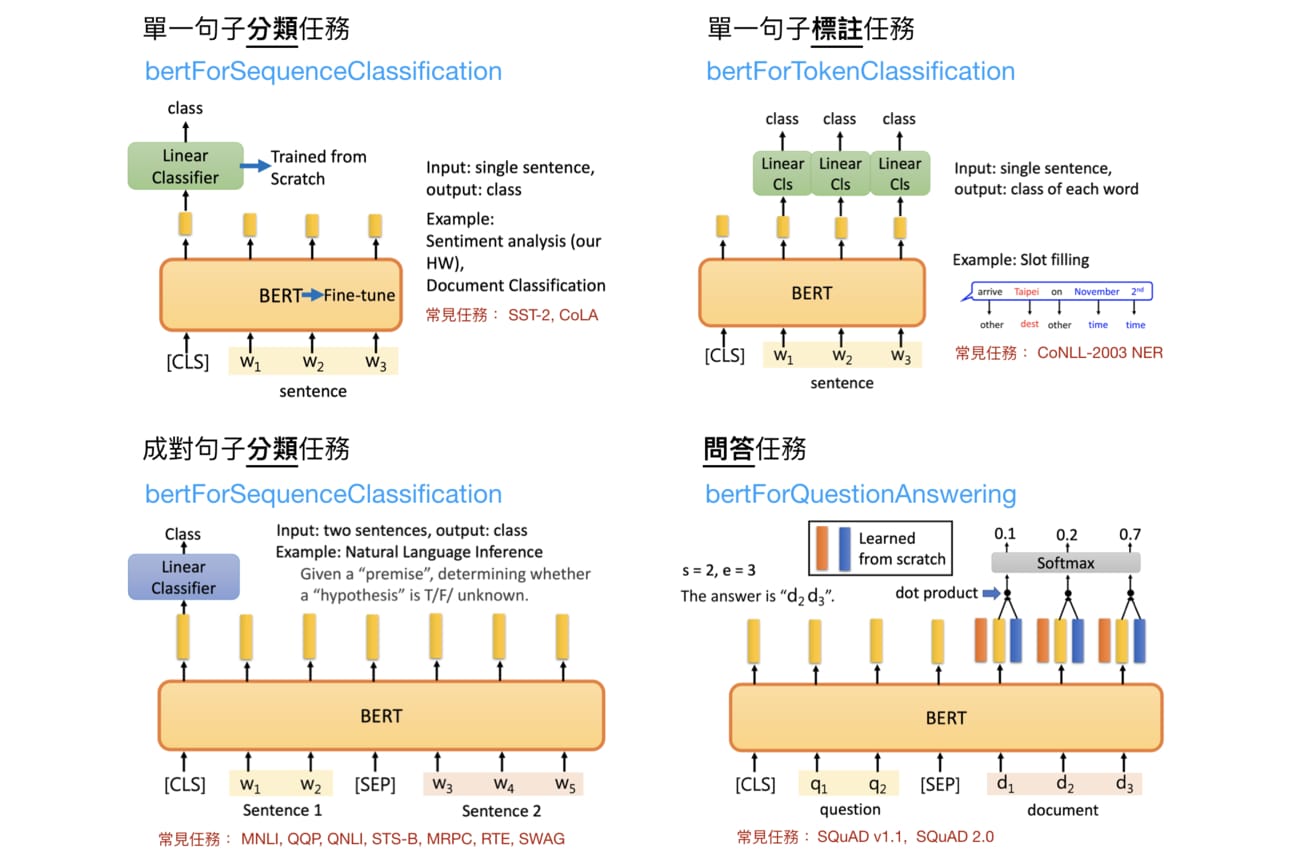
資訊量不少,但我假設你在前面教授的 BERT 影片或是其他地方已經看過類似的圖。
首先,我們前面一直提到的 fine-tuning BERT 指的是在預訓練完的 BERT 之上加入新的線性分類器(Linear Classifier),並利用下游任務的目標函式從頭訓練分類器並微調 BERT 的參數。這樣做的目的是讓整個模型(BERT + Linear Classifier)能一起最大化當前下游任務的目標。
圖中紅色小字則是該任務類型常被拿來比較的資料集,比方說 MNLI 及 SQuAD v1.1。
不過現在對我們來說最重要的是圖中的藍色字體。多虧了 HuggingFace 團隊,要用 PyTorch fine-tuing BERT 是件非常容易的事情。每個藍色字體都對應到一個可以處理下游任務的模型,而這邊說的模型指的是已訓練的 BERT + Linear Classifier。
按圖索驥,因為假新聞分類是一個成對句子分類任務,自然就對應到上圖的左下角。FINETUNE_TASK 則為 bertForSequenceClassification:
# 載入一個可以做中文多分類任務的模型,n_class = 3
from transformers import BertForSequenceClassification
PRETRAINED_MODEL_NAME = "bert-base-chinese"
NUM_LABELS = 3
model = BertForSequenceClassification.from_pretrained(
PRETRAINED_MODEL_NAME, num_labels=NUM_LABELS)
clear_output()
# high-level 顯示此模型裡的 modules
print("""
name module
----------------------""")
for name, module in model.named_children():
if name == "bert":
for n, _ in module.named_children():
print(f"{name}:{n}")
else:
print("{:15} {}".format(name, module))
沒錯,一行程式碼就初始化了一個可以用 BERT 做文本多分類的模型 model。我也列出了 model 裡頭最 high level 的模組,資料流則從上到下,通過:
- BERT 處理各種
embeddings的模組 - 在神經機器翻譯就已經看過的 Transformer Encoder
- 一個 pool
[CLS]token 在所有層的 repr. 的 BertPooler - Dropout 層
- 回傳 3 個類別 logits 的線性分類器
classifier
而 classifer 就只是將從 BERT 那邊拿到的 [CLS] token 的 repr. 做一個線性轉換而已,非常簡單。我也將我們實際使用的分類模型 BertForSequenceClassification 實作簡化一下供你參考:
class BertForSequenceClassification(BertPreTrainedModel):
def __init__(self, config, num_labels=2, ...):
super(BertForSequenceClassification, self).__init__(config)
self.num_labels = num_labels
self.bert = BertModel(config, ...) # 載入預訓練 BERT
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# 簡單 linear 層
self.classifier = nn.Linear(config.hidden_size, num_labels)
...
def forward(self, input_ids, token_type_ids=None, attention_mask=None, labels=None, ...):
# BERT 輸入就是 tokens, segments, masks
outputs = self.bert(input_ids, token_type_ids, attention_mask, ...)
...
pooled_output = self.dropout(pooled_output)
# 線性分類器將 dropout 後的 BERT repr. 轉成類別 logits
logits = self.classifier(pooled_output)
# 輸入有 labels 的話直接計算 Cross Entropy 回傳,方便!
if labels is not None:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
return loss
# 有要求回傳注意矩陣的話回傳
elif self.output_attentions:
return all_attentions, logits
# 回傳各類別的 logits
return logits
這樣應該清楚多了吧!我們的分類模型 model 也就只是在 BERT 之上加入 dropout 以及簡單的 linear classifier,最後輸出用來預測類別的 logits。 這就是兩階段遷移學習強大的地方:你不用再自己依照不同 NLP 任務從零設計非常複雜的模型,只需要站在巨人肩膀上,然後再做一點點事情就好了。
你也可以看到整個分類模型 model 預設的隱狀態維度為 768。如果你想要更改 BERT 的超參數,可以透過給一個 config dict 來設定。以下則是分類模型 model 預設的參數設定:
model.config
Dropout、LayerNorm、全連接層數以及 mutli-head attentions 的 num_attention_heads 等超參數我們也都已經在之前的 Transformer 文章看過了,這邊就不再贅述。
目前 PyTorch Hub 上有 8 種模型以及一個 tokenizer 可供使用,依照用途可以分為:
- 基本款:
- bertModel
- bertTokenizer
- 預訓練階段
- bertForMaskedLM
- bertForNextSentencePrediction
- bertForPreTraining
- Fine-tuning 階段
- bertForSequenceClassification
- bertForTokenClassification
- bertForQuestionAnswering
- bertForMultipleChoice
粗體是本文用到的模型。如果你想要完全 DIY 自己的模型,可以載入純 bertModel 並參考上面看到的 BertForSequenceClassification 的實作。當然建議盡量不要重造輪子。如果只是想要了解其背後實作邏輯,可以參考 pytorch-transformers。
有了 model 以及我們在前一節建立的 trainloader,讓我們寫一個簡單函式測試現在 model 在訓練集上的分類準確率:
"""
定義一個可以針對特定 DataLoader 取得模型預測結果以及分類準確度的函式
之後也可以用來生成上傳到 Kaggle 競賽的預測結果
2019/11/22 更新:在將 `tokens`、`segments_tensors` 等 tensors
丟入模型時,強力建議指定每個 tensor 對應的參數名稱,以避免 HuggingFace
更新 repo 程式碼並改變參數順序時影響到我們的結果。
"""
def get_predictions(model, dataloader, compute_acc=False):
predictions = None
correct = 0
total = 0
with torch.no_grad():
# 遍巡整個資料集
for data in dataloader:
# 將所有 tensors 移到 GPU 上
if next(model.parameters()).is_cuda:
data = [t.to("cuda:0") for t in data if t is not None]
# 別忘記前 3 個 tensors 分別為 tokens, segments 以及 masks
# 且強烈建議在將這些 tensors 丟入 `model` 時指定對應的參數名稱
tokens_tensors, segments_tensors, masks_tensors = data[:3]
outputs = model(input_ids=tokens_tensors,
token_type_ids=segments_tensors,
attention_mask=masks_tensors)
logits = outputs[0]
_, pred = torch.max(logits.data, 1)
# 用來計算訓練集的分類準確率
if compute_acc:
labels = data[3]
total += labels.size(0)
correct += (pred == labels).sum().item()
# 將當前 batch 記錄下來
if predictions is None:
predictions = pred
else:
predictions = torch.cat((predictions, pred))
if compute_acc:
acc = correct / total
return predictions, acc
return predictions
# 讓模型跑在 GPU 上並取得訓練集的分類準確率
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("device:", device)
model = model.to(device)
_, acc = get_predictions(model, trainloader, compute_acc=True)
print("classification acc:", acc)
毫不意外,模型裡新加的線性分類器才剛剛被初始化,整個分類模型的表現低於 68 % 的 baseline 是非常正常的。因為模型是隨機初始化的,你的執行結果可能跟我有點差距,但應該不會超過 68 %。
另外我們也可以算算整個分類模型以及裡頭的簡單分類器有多少參數:
def get_learnable_params(module):
return [p for p in module.parameters() if p.requires_grad]
model_params = get_learnable_params(model)
clf_params = get_learnable_params(model.classifier)
print(f"""
整個分類模型的參數量:{sum(p.numel() for p in model_params)}
線性分類器的參數量:{sum(p.numel() for p in clf_params)}
""")
新增的 classifier 的參數量在 BERT 面前可說是滄海一粟。而因為分類模型大多數的參數都是從已訓練的 BERT 來的,實際上我們需要從頭訓練的參數量非常之少,這也是遷移學習的好處。
當然,一次 forward 所需的時間也不少就是了。
4. 訓練該下游任務模型¶
接下來沒有什麼新玩意了,除了需要記得我們前面定義的 batch 數據格式以外,訓練分類模型 model 就跟一般你使用 PyTorch 訓練模型做的事情相同。
為了避免失焦,訓練程式碼我只保留核心部分:
%%time
# 訓練模式
model.train()
# 使用 Adam Optim 更新整個分類模型的參數
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)
EPOCHS = 6 # 幸運數字
for epoch in range(EPOCHS):
running_loss = 0.0
for data in trainloader:
tokens_tensors, segments_tensors, \
masks_tensors, labels = [t.to(device) for t in data]
# 將參數梯度歸零
optimizer.zero_grad()
# forward pass
outputs = model(input_ids=tokens_tensors,
token_type_ids=segments_tensors,
attention_mask=masks_tensors,
labels=labels)
loss = outputs[0]
# backward
loss.backward()
optimizer.step()
# 紀錄當前 batch loss
running_loss += loss.item()
# 計算分類準確率
_, acc = get_predictions(model, trainloader, compute_acc=True)
print('[epoch %d] loss: %.3f, acc: %.3f' %
(epoch + 1, running_loss, acc))
哇嗚!我們成功地 Fine-tune BERT 了!
儘管擁有 1 億參數的分類模型十分巨大,多虧了小訓練集的助攻(?),幾個 epochs 的訓練過程大概在幾分鐘內就結束了。從準確率看得出我們的分類模型在非常小量的訓練集的表現已經十分不錯,接著讓我們看看這個模型在真實世界,也就是 Kaggle 競賽上的測試集能得到怎麼樣的成績。
5. 對新樣本做推論¶
這邊我們要做的事情很單純,就只是用訓練過後的分類模型 model 為測試集裡的每個樣本產生預測分類。執行完以下程式碼,我們就能得到一個能直接繳交到 Kaggle 競賽的 csv 檔案:
%%time
# 建立測試集。這邊我們可以用跟訓練時不同的 batch_size,看你 GPU 多大
testset = FakeNewsDataset("test", tokenizer=tokenizer)
testloader = DataLoader(testset, batch_size=256,
collate_fn=create_mini_batch)
# 用分類模型預測測試集
predictions = get_predictions(model, testloader)
# 用來將預測的 label id 轉回 label 文字
index_map = {v: k for k, v in testset.label_map.items()}
# 生成 Kaggle 繳交檔案
df = pd.DataFrame({"Category": predictions.tolist()})
df['Category'] = df.Category.apply(lambda x: index_map[x])
df_pred = pd.concat([testset.df.loc[:, ["Id"]],
df.loc[:, 'Category']], axis=1)
df_pred.to_csv('bert_1_prec_training_samples.csv', index=False)
df_pred.head()

!ls bert*.csv
我們前面就說過測試集是訓練集的 30 倍,因此光是做推論就得花不少時間。廢話不多說,讓我將生成的預測結果上傳到 Kaggle 網站,看看會得到怎麼樣的結果:
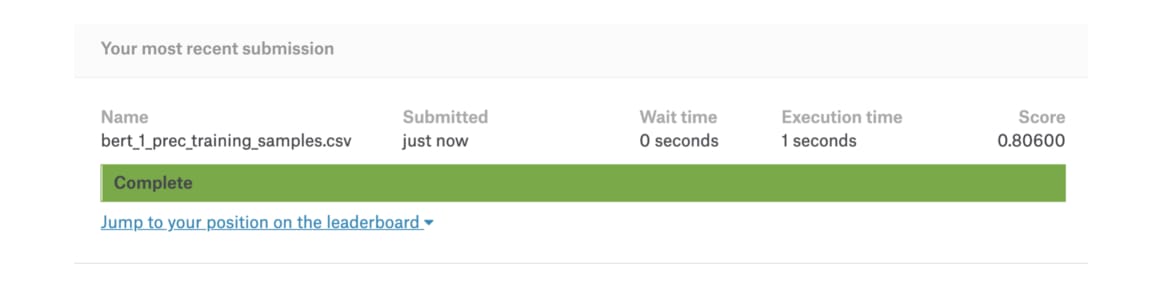
測試集是訓練集的 30 倍大,overfitting 完全是可預期的。不過跟我們一開始多數決的 68 % baseline 相比,以 BERT fine tune 的分類模型在測試集達到 80 %,整整上升了 12 %。雖然這篇文章的重點一直都不在最大化這個假新聞分類任務的準確率,還是別忘了我們只用了不到原來競賽 1 % 的數據以及不到 5 分鐘的時間就達到這樣的結果。
讓我們忘了準確率,看看 BERT 本身在 fine tuning 之前與之後的差異。以下程式碼列出模型成功預測 disagreed 類別的一些例子:
predictions = get_predictions(model, trainloader)
df = pd.DataFrame({"predicted": predictions.tolist()})
df['predicted'] = df.predicted.apply(lambda x: index_map[x])
df1 = pd.concat([trainset.df, df.loc[:, 'predicted']], axis=1)
disagreed_tp = ((df1.label == 'disagreed') & \
(df1.label == df1.predicted) & \
(df1.text_a.apply(lambda x: True if len(x) < 10 else False)))
df1[disagreed_tp].head()

其實用肉眼看看這些例子,以你對自然語言的理解應該能猜出要能正確判斷 text_b 是反對 text_a,首先要先關注「謠」、「假」等代表反對意義的詞彙,接著再看看兩個句子間有沒有含義相反的詞彙。
讓我們從中隨意選取一個例子,看看 fine tuned 後的 BERT 能不能關注到該關注的位置。再次出動 BertViz 來視覺化 BERT 的注意權重:
# 觀察訓練過後的 model 在處理假新聞分類任務時關注的位置
# 去掉 `state_dict` 即可觀看原始 BERT 結果
model_version = 'bert-base-chinese'
finetuned_model = BertModel.from_pretrained(model_version,
output_attentions=True, state_dict=model.state_dict())
# 兩個句子
sentence_a = "烟王褚时健去世"
sentence_b = "辟谣:一代烟王褚时健安好!"
# 得到 tokens 後丟入 BERT 取得 attention
inputs = tokenizer.encode_plus(sentence_a, sentence_b, return_tensors='pt', add_special_tokens=True)
token_type_ids = inputs['token_type_ids']
input_ids = inputs['input_ids']
attention = finetuned_model(input_ids, token_type_ids=token_type_ids)[-1]
input_id_list = input_ids[0].tolist() # Batch index 0
tokens = tokenizer.convert_ids_to_tokens(input_id_list)
call_html()
head_view(attention, tokens)
# 這段程式碼會顯示下圖中右邊的結果
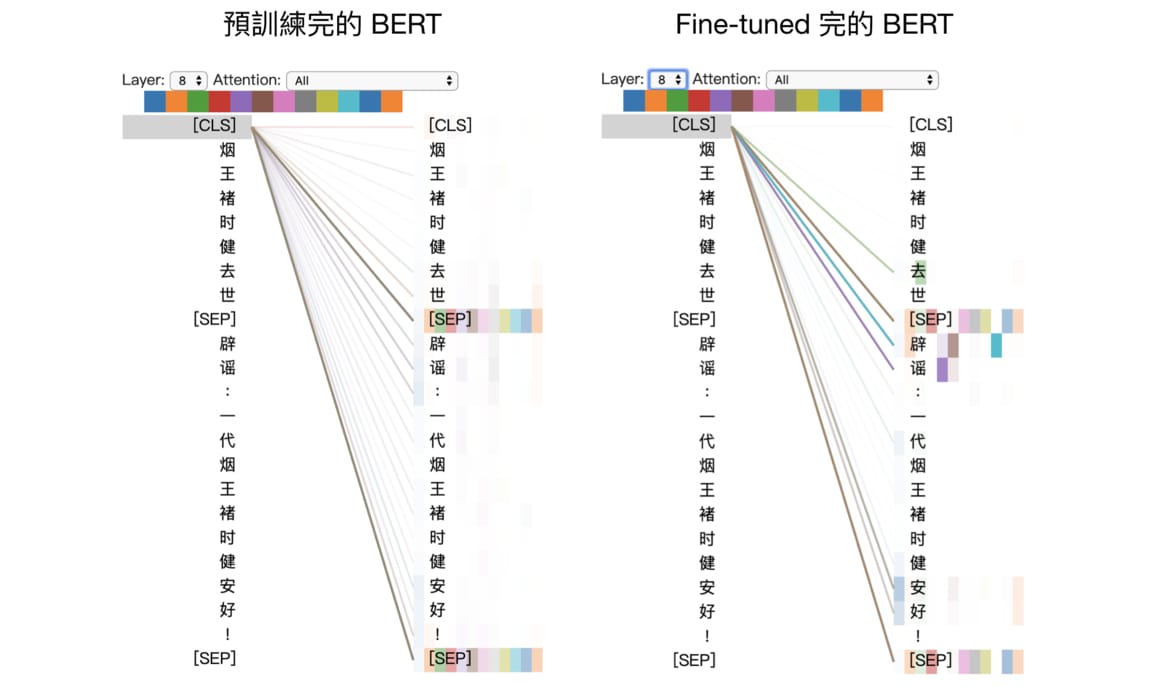
我們說過在 BERT 裡頭,第一個 [CLS] 的 repr. 代表著整個輸入序列的 repr.。
左邊是一般預訓練完的 BERT。如果你還記得 BERT 的其中一個預訓練任務 NSP 的話,就會了解這時的 [CLS] 所包含的資訊大多是要用來預測第二句本來是否接在第一句後面。以第 8 層 Encoder block 而言,你會發現大多數的 heads 在更新 [CLS] 時只關注兩句間的 [SEP]。
有趣的是在看過一些假新聞分類數據以後(右圖),這層的一些 heads 在更新 [CLS] 的 repr. 時會開始關注跟下游任務目標相關的特定詞彙:
- 闢謠
- 去世
- 安好
在 fine tune 一陣子之後, 這層 Encoder block 學會關注兩句之間「衝突」的位置,並將這些資訊更新到 [CLS] 裡頭。有了這些資訊,之後的 Linear Classifier 可以將其轉換成更好的分類預測。考慮到我們只給 BERT 看不到 1 % 的數據,這樣的結果不差。如果有時間 fine tune 整個訓練集,我們能得到更好的成果。
好啦,到此為止你應該已經能直觀地理解 BERT 並開始 fine tuning 自己的下游任務了。如果你要做的是如 SQuAD 問答等常見的任務,甚至可以用 transformers 準備好的 Python 腳本一鍵完成訓練與推論:
# 腳本模式的好處是可以透過改變參數快速進行各種實驗。
# 壞處是黑盒子效應,不過對閱讀完本文的你應該不是個問題。
# 選擇適合自己的方式 fine-tuning BERT 吧!
export SQUAD_DIR=/path/to/SQUAD
python run_squad.py \
--bert_model bert-base-uncased \
--do_train \
--do_predict \
--do_lower_case \
--train_file $SQUAD_DIR/train-v1.1.json \
--predict_file $SQUAD_DIR/dev-v1.1.json \
--train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2.0 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /tmp/debug_squad/
用腳本的好處是你不需要知道所有實作細節,只要調整自己感興趣的參數就好。我在用 CartoonGAN 與 TensorFlow 2 生成新海誠動畫一文也採用同樣方式,提供讀者一鍵生成卡通圖片的 Python 腳本。
當然,你也可以先試著一步步執行本文列出的程式碼,複習並鞏固學到的東西。最後,讓我們做點簡單的總結。
結語¶
一路過來,你現在應該已經能夠:
- 直觀理解 BERT 內部自注意力機制的物理意義
- 向其他人清楚解釋何謂 BERT 以及其運作的原理
- 了解 contextual word repr. 及兩階段遷移學習
- 將文本數據轉換成 BERT 相容的輸入格式
- 依據下游任務 fine tuning BERT 並進行推論
恭喜!你現在已經具備能夠進一步探索最新 NLP 研究與應用的能力了。
我還有不少東西想跟你分享,但因為時間有限,在這邊就簡單地條列出來:
- BERT 的 Encoder 架構很適合做自然語言理解 NLU 任務,但如文章摘要等自然語言生成 NLG 的任務就不太 okay。BertSum 則是一篇利用 BERT 做萃取式摘要並在 CNN/Dailymail 取得 SOTA 的研究,適合想要在 BERT 之上開發自己模型的人參考作法
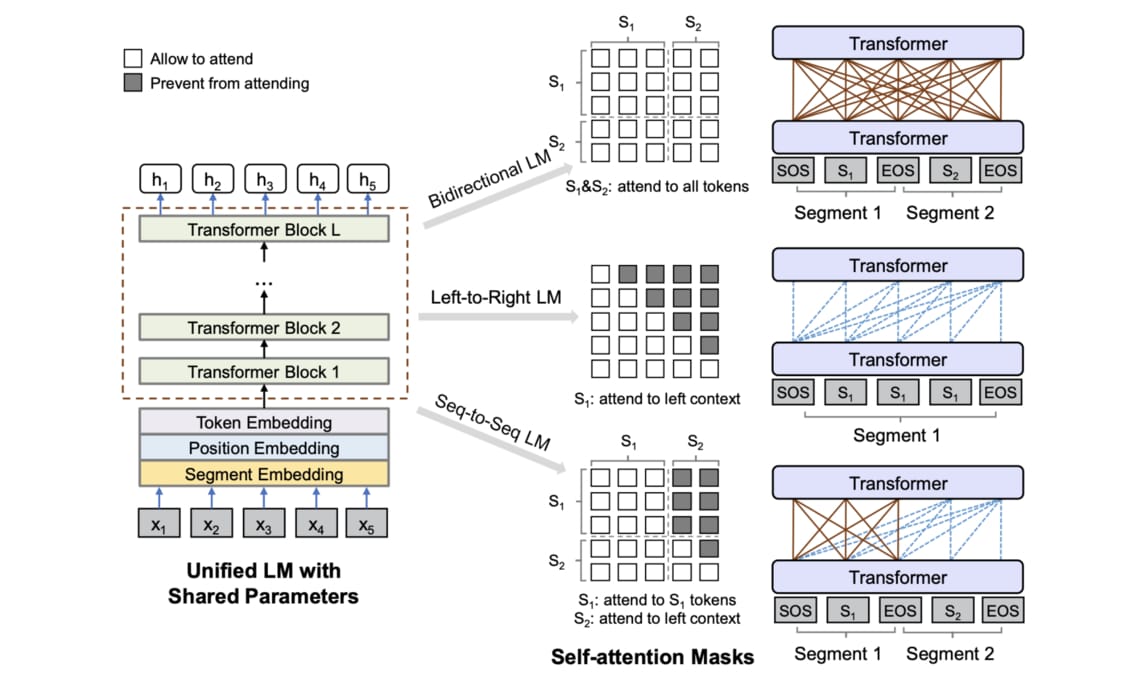
- UniLM 透過「玩弄」注意力遮罩使得其可以在預訓練階段同時訓練 3 種語言模型,讓 fine tune NLG 任務不再是夢想。如果你了解之前 Transformer 文章裡說明的遮罩概念,幾秒鐘就能直觀理解上面的 UniLM 架構
- 最近新的 NLP 王者非 XLNet 莫屬。其表現打敗 BERT 自然不需多言,但訓練該模型所需的花費令人不禁思考這樣的大公司遊戲是否就是我們要的未來
- 有些人認為 BERT 不夠通用,因為 Fine-tuning 時還要依照不同下游任務加入新的 Linear Classifier。有些人提倡使用 Multitask Learning 想辦法弄出更通用的模型,而 decaNLP 是一個知名例子。
- PyTorch 的 BERT 雖然使用上十分直覺,如果沒有強大的 GPU 還是很難在實務上使用。你可以嘗試特徵擷取或是 freeze BERT。另外如果你是以個人身份進行研究,但又希望能最小化成本並加快模型訓練效率,我會推薦花點時間學會在 Colab 上使用 TensorFlow Hub 及 TPU 訓練模型
其他的碎念留待下次吧。
當時在撰寫進入 NLP 世界的最佳橋樑一文時我希望能用點微薄之力搭起一座小橋,幫助更多人平順地進入 NLP 世界。作為該篇文章的延伸,這次我希望已經在 NLP 世界闖蕩的你能夠進一步掌握突破城牆的巨人之力,前往更遠的地方。
啊,我想這篇文章就是讓你變成智慧巨人的脊髓液了!我們牆外見。
跟資料科學相關的最新文章直接送到家。 只要加入訂閱名單,當新文章出爐時, 你將能馬上收到通知