木婉清轉頭向他,背脊向著南海鱷神,低聲道:「你是世上第一個見到我容貌的男子!」緩緩拉開了面幕。段譽登時全身一震,眼前所見,如新月清暉,如花樹堆雪,一張臉秀麗絕俗。
第四回:崖高人遠
《天龍八部》一直是我最喜歡的金庸著作之一,最近重新翻閱,有很多新的感受。
閱讀到一半我突發奇想,決定嘗試用深度學習以及 TensorFlow 2.0 來訓練一個能夠生成《天龍八部》的循環神經網路。生成結果仍不完美,但我認為已經很有娛樂性質,且有時能夠產生令人驚嘆或是捧腹大笑的文章了。
因此我決定使用 Tensorflow.js 將訓練出來的模型弄上線,讓你也能實際看看這個 AI 嗑了什麼藥。

在 demo 之後,我將以此文的 AI 應用為例,用 TensorFlow 2.0 帶你走過深度學習專案中常見的 7 個步驟:
希望閱讀本文後能讓你學到點東西,從中獲得些啟發,並運用自己的想像力創造點新的東西。
前言夠長了,讓我們馬上進入 demo 吧!
生成新的天龍八部橋段¶
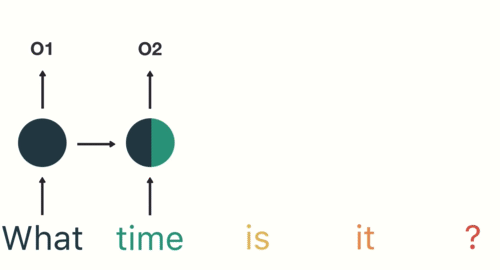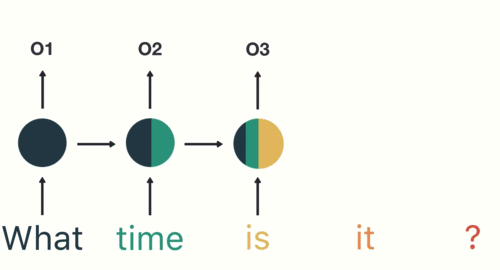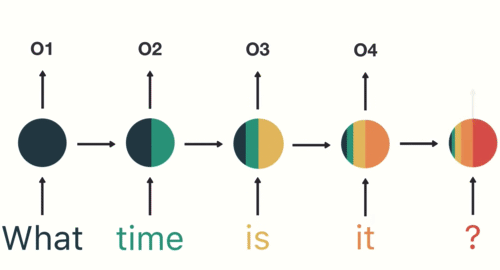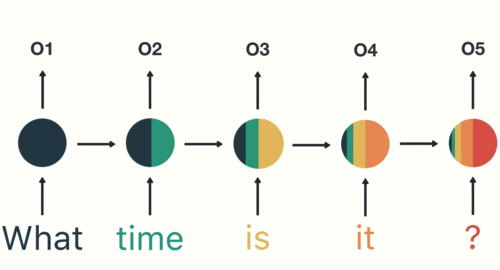
本篇使用一個十分簡單的長短期記憶 RNN 來生成文章。在多次「閱讀」天龍八部之後,這個模型可以在給定一段文本的情況下,逐字產生類似天龍八部小說的文章。
比方說給定書中的一個橋段:
烏老大偏生要考一考慕容復,說道:「慕容公子,你瞧這不是大大的
你會怎麼接下去?
本文的模型順著上面的話生成的其中一次結果:
不算?」馬夫人道:「不錯,咱們非要尋死不可。」
段譽大喜,說道:「小姑娘,你待我這麼好,鬼鬼祟祟,一切又不聽你的話,你管甚麼老兄弟不相干,我去幫過彥之。」
王夫人哼了一聲,說道:「這裏是甚麼話?」段譽道:「不行!你別過來。用真蠻子,我便將這件事了,一大惡人擠在地下,立時便會斃命,那便如何是好?」
文章內容很ㄎ一ㄤ,惹人發笑,但用詞本身很天龍八部。(至少我自己寫不出這樣的內容)

現在馬上就讓我們產生一些新的橋段吧!首先將已經訓練好的模型載入你的瀏覽器。
(建議在網速快的地方載入模型以減少等待時間,或者點擊載入後先閱讀模型是怎麼被訓練的,等等再回來查看)
成功載入模型後,你將可以用它不斷地產生新的橋段:
另外你會發現有 2 個可供你調整的參數:
第一次可以直接使用預設值。現在點擊生成文章來產生全新的天龍八部橋段:
如何?希望模型產生的結果有成功令你嘴角上揚。當初它可快把我逗死了。
現在你可以嘗試幾件事情:
- 點生成文章來讓模型依據同輸入產生新橋段
- 點重置輸入來隨機取得一個新的起始句子
- 增加模型生成的文章長度
- 調整生成溫度來改變文章的變化性

生成溫度是一個實數值,而當溫度越高,模型產生出來的結果越隨機、越不可預測(也就越ㄎㄧㄤ);而溫度越低,產生的結果就會越像天龍八部原文。優點是真實,但同時字詞的重複性也會提升。
機器並沒有情感,只有人類可以賦予事物意義。我們無法讓機器自動找出最佳的生成溫度,因為人的感覺十分主觀:找出你自己覺得最適合的溫度來生成文章。
如果你沒有打算深入探討技術細節,那只需要記得在這篇文章裡頭的模型是一個以「字」為單位的語言模型(Character-based Language Model)即可:給定一連串已經出現過的字詞,模型會想辦法去預測出下一個可能出現的字。

值得注意的是,我們並不單純是拿出現機率最高的字出來當生成結果,這樣太無趣了。
每次機器做預測前都會拿著一個包含大量中文字的機率分布 p,在決定要吐出哪個字時,會對該機率分佈 p 做抽樣,從中隨機選出一個字。
因此就跟你在上面 demo 看到的一樣,就算輸入的句子相同,每次模型仍然會生成完全不同的文章。

因為隨機抽樣的關係,每次模型產生的結果基本上都是獨一無二的。
如果你在生成文章的過程中得到什麼有趣的虛擬橋段,都歡迎與我分享:)

本文接著將詳細解說此應用是怎麼被開發出來的。如果你現在沒有打算閱讀,可以直接跳到結語。
模型是怎麼被訓練的¶
在看完 demo 以後,你可能會好奇這個模型是怎麼被訓練出來的。
實際的開發流程大致可以分為兩個部分:
這些在 TensorFlow 以及 TensorFlow.js 的官網都有詳細的教學以及程式碼供你參考。
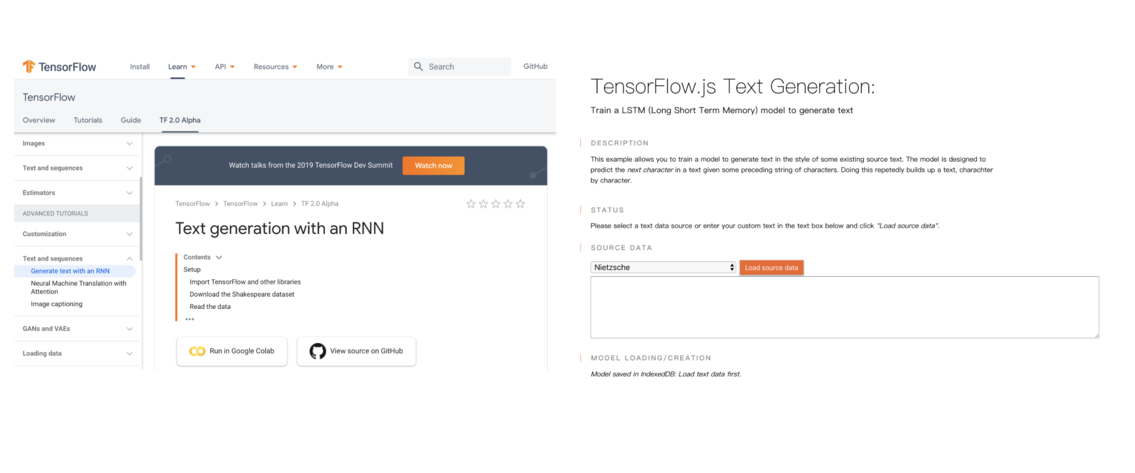
如果你也想開發一個類似的應用,閱讀官方教學中你所熟悉的語言版本(Python / JavaScript)是最直接的作法:
- TensorFlow 2.0 Alpha - Text generation with an RNN
- TensorFlow.js Example: Train LSTM to Generate Text
因為官方已經有提供能在 Google Colab 上使用 GPU 訓練 LSTM 的教學筆記本,本文便不再另行提供。

另外,具備以下背景可以讓你更輕鬆地閱讀接下來的內容:
- 熟悉 Python
- 碰過 Keras 或是 TensorFlow
- 具備機器學習 & 深度學習基礎
- 了解何謂循環神經網路以及長短期記憶
如果你是喜歡先把基礎打好的人,可以先查閱我上面附的這些資源連結。
TensorFlow 2.0 開發¶
平常有在接觸深度學習的讀者或許都已經知道,最近 TensorFlow 隆重推出 2.0 Alpha 預覽版,希望透過全新的 API 讓更多人可以輕鬆地開發機器學習以及深度學習應用。
當初撰寫本文的其中一個目的,也是想趁著這次大改版來讓自己熟悉一下 TensorFlow 2.0 的開發方式。
TensorFlow 2.0 值得關注的更新不少,但以下幾點跟一般的 ML 開發者最為相關:
- tf.keras 被視為官方高級 API,強調其地位
- 方便除錯的 Eager Execution 成為預設值
- 負責讀取、處理大量數據的 tf.data API
- 自動幫你建構計算圖的 tf.function
在這篇文章裡頭會看到前 3 者。下節列出的程式碼皆在 Google Colab 上用最新版本的 TensorFlow 2.0 Nightly 執行。
pip install tf-nightly-gpu-2.0-preview
如果有 GPU 則強烈建議安裝 GPU 版本的 TF Nightly,訓練速度跟 CPU 版本可以差到 10 倍以上。
深度學習專案步驟¶
好戲終於登場。
如同多數的深度學習專案,要訓練一個以 LSTM 為基礎的語言模型,你大致需要走過以下幾個步驟:

這個流程是一個大方向,依據不同情境你可能需要做些調整來符合自己的需求,且很多步驟需要重複進行。
這篇文章會用 TensorFlow 2.0 簡單地帶你走過所有步驟。
1. 定義問題及要解決的任務¶
很明顯地,在訓練模型前首先得確認我們的問題(Problem)以及想要交給機器解決的任務(Task)是什麼。
前面已經提過,我們的目標就是要找出一個天龍八部的語言模型(Language Model),讓該模型在被餵進一段文字以後,能吐出類似天龍八部的文章。
這實際上是一個序列生成(Sequence Generation)問題,而機器所要解決的任務也變得明確:給定一段文字單位的序列,它要能吐出下一個合理的文字單位。
這邊說的文字單位(Token)可以是
- 字(Character,如劍、寺、雲)
- 詞(Word,如吐蕃、師弟、阿修羅)
本文則使用「字」作為一個文字單位。現在假設有一個天龍八部的句子:
『六脈神劍經』乃本寺鎮寺之寶,大理段氏武學的至高法要。
這時候句子裡的每個字(含標點符號)都是一個文字單位,而整個句子就構成一個文字序列。我們可以擷取一部份句子:
『六脈神劍經』乃本寺鎮寺之寶,大理段氏武
接著在訓練模型時要求它讀入這段文字,並預測出原文裡頭出現的下一個字:學。
一旦訓練完成,就能得到你開頭看到的那個語言模型了。
2. 準備原始數據、資料清理¶
巧婦難為無米之炊,沒有數據一切免談。

我在網路上蒐集天龍八部原文,做些簡單的數據清理後發現整本小說總共約含 120 萬個中文字,實在是一部曠世巨作。儘管因為版權問題不宜提供下載連結,你可以 Google 自己有興趣的文本。
現在假設我們把原文全部存在一個 Python 字串 text 裡頭,則部分內容可能如下:
# 隨意取出第 9505 到 9702 的中文字
print(text[9505:9702])
我們也可以看看整本小說裡頭包含多少中文字:
n = len(text)
w = len(set(text))
print(f"天龍八部小說共有 {n} 中文字")
print(f"包含了 {w} 個獨一無二的字")
相較於英文只有 26 個簡單字母,博大精深的中文裡頭有非常多漢字。

如同寫給所有人的自然語言處理與深度學習入門指南裡頭說過的,要將文本數據丟入只懂數字的神經網路,我們得先做些前處理。
具體來說,得將這些中文字對應到一個個的索引數字(Index)或是向量才行。
我們可以使用 tf.keras 裡頭的 Tokenizer 幫我們把整篇小說建立字典,並將同樣的中文字對應到同樣的索引數字:
import tensorflow as tf
# 初始化一個以字為單位的 Tokenizer
tokenizer = tf.keras\
.preprocessing\
.text\
.Tokenizer(
num_words=num_words,
char_level=True,
filters=''
)
# 讓 tokenizer 讀過天龍八部全文,
# 將每個新出現的字加入字典並將中文字轉
# 成對應的數字索引
tokenizer.fit_on_texts(text)
text_as_int = tokenizer\
.texts_to_sequences([text])[0]
# 隨機選取一個片段文本方便之後做說明
s_idx = 21004
e_idx = 21020
partial_indices = \
text_as_int[s_idx:e_idx]
partial_texts = [
tokenizer.index_word[idx] \
for idx in partial_indices
]
# 渲染結果,可忽略
print("原本的中文字序列:")
print()
print(partial_texts)
print()
print("-" * 20)
print()
print("轉換後的索引序列:")
print()
print(partial_indices)
很明顯地,現在整部天龍八部都已經被轉成一個巨大的數字序列,每一個數字代表著一個獨立的中文字。
我們可以換個方向再看一次:
3. 建立能丟入模型的資料集¶
做完基本的數據前處理以後,我們需要將 text_as_int 這個巨大的數字序列轉換成神經網路容易消化的格式與大小。
text_as_int[:10]
_type = type(text_as_int)
n = len(text_as_int)
print(f"text_as_int 是一個 {_type}\n")
print(f"小說的序列長度: {n}\n")
print("前 5 索引:", text_as_int[:5])
在建立資料集時,你要先能想像最終交給模型的數據長什麼樣子。這樣能幫助你對數據做適當的轉換。
依照當前機器學習任務的性質,你會需要把不同格式的數據餵給模型。
在本文的序列生成任務裡頭,理想的模型要能依據前文來判斷出下一個中文字。因此我們要丟給模型的是一串代表某些中文字的數字序列:
print("實際丟給模型的數字序列:")
print(partial_indices[:-1])
print()
print("方便我們理解的文本序列:")
print(partial_texts[:-1])
而模型要給我們的理想輸出應該是向左位移一個字的結果:
print("實際丟給模型的數字序列:")
print(partial_indices[1:])
print()
print("方便我們理解的文本序列:")
print(partial_texts[1:])
為什麼是這樣的配對?

讓我們將輸入序列及輸出序列拿來對照看看:
司 空 玄 雙 掌 飛 舞 , 逼 得 牠 無 法 近
空 玄 雙 掌 飛 舞 , 逼 得 牠 無 法 近 前
從左看到右你會發現,一個模型如果可以給我們這樣的輸出,代表它:
- 看到第一個輸入字
司時可以正確輸出空 - 在之前看過
司,且新輸入字為空的情況下,可以輸出玄 - 在之前看過
司空,且新輸入字為玄的情況下,可以輸出雙 - 在之前看過
司空玄雙掌飛,且新輸入字為舞的情況下,可以輸出,
當一個語言模型可以做到這樣的事情,就代表它已經掌握了訓練文本(此文中為天龍八部)裡頭用字的統計結構,因此我們可以用它來產生新的天龍八部文章。
你現在應該也可以了解,這個語言模型是專為天龍八部的文本所誕生的。畢竟日常生活中,給你 舞 這個字,你接 , 的機率有多少呢?

為了讓你加深印象,讓我把序列擺直,再次列出模型的輸入以及輸出關係:
每一列(row)是一個時間點,而
- 輸入索引代表模型在當下時間吃進去的輸入
- 輸出索引則代表我們要模型輸出的結果
輸入字・輸出字則只是方便我們理解對照,實際上模型只吃數字。

現在我們了解一筆輸入・輸出該有的數據格式了。兩者皆是一個固定長度的數字序列,而後者是前者往左位移一個數字的結果。
但這只是一筆數據(以下說的一筆數據,都隱含了輸入序列以及對應的輸出序列的 2 個數字序列)。
在有 GPU 的情況下,我們常常會一次丟一批(batch)數據,讓 GPU 可以平行運算,加快訓練速度。

現在假設我們想要一個資料集,而此資料集可以一次給我們 128 筆長度為 10 的輸入・輸出序列,則我們可以用 tf.data 這樣做:
# 方便說明,實際上我們會用更大的值來
# 讓模型從更長的序列預測下個中文字
SEQ_LENGTH = 10 # 數字序列長度
BATCH_SIZE = 128 # 幾筆成對輸入/輸出
# text_as_int 是一個 python list
# 我們利用 from_tensor_slices 將其
# 轉變成 TensorFlow 最愛的 Tensor <3
characters = tf\
.data\
.Dataset\
.from_tensor_slices(
text_as_int)
# 將被以數字序列表示的天龍八部文本
# 拆成多個長度為 SEQ_LENGTH (10) 的序列
# 並將最後長度不滿 SEQ_LENGTH 的序列捨去
sequences = characters\
.batch(SEQ_LENGTH + 1,
drop_remainder=True)
# 天龍八部全文所包含的成對輸入/輸出的數量
steps_per_epoch = \
len(text_as_int) // SEQ_LENGTH
# 這個函式專門負責把一個序列
# 拆成兩個序列,分別代表輸入與輸出
# (下段有 vis 解釋這在做什麼)
def build_seq_pairs(chunk):
input_text = chunk[:-1]
target_text = chunk[1:]
return input_text, target_text
# 將每個從文本擷取出來的序列套用上面
# 定義的函式,拆成兩個數字序列
# 作為輸入/輸出序列
# 再將得到的所有數據隨機打亂順序
# 最後再一次拿出 BATCH_SIZE(128)筆數據
# 作為模型一次訓練步驟的所使用的資料
ds = sequences\
.map(build_seq_pairs)\
.shuffle(steps_per_epoch)\
.batch(BATCH_SIZE,
drop_remainder=True)
這段建構 tf.data.Dataset 的程式碼雖然不短,但有超過一半是我寫給你的註解。
事實上用 tf.data 架構一個資料集並不難,且學會以後你每次都可用類似的方式呼叫 TensorFlow Data API 來處理任何文本數據,而不需要每次遇到新文本都從頭開始寫類似的功能(batch、shuffle etc)。

再次提醒,如果你想自己動手可以參考官方用 TensorFlow 2.0 訓練 LSTM 的 Colab 筆記本。
雖然我不是酷拉皮卡,但如果要把上面 build_seq_pairs 的處理具現化的話,大概就像是下面這樣(假設序列長度為 6):
擷取的片段序列 輸入/輸出序列
-------------------------------
-> 烏老大拱手還
|
烏老大拱手還禮 -----
|
-> 老大拱手還禮
-> 星宿派人數遠
|
星宿派人數遠較 -----
|
-> 宿派人數遠較
-> 過不多時,賈
|
過不多時,賈老 -----
|
-> 不多時,賈老
你會發現針對序列長度 SEQ_LENGTH 為 6 的情況,我會刻意將天龍八部文本切成長度為 SEQ_LENGTH + 1:7 的句子,再從這些句子建立出輸入及輸出序列。
到此為止,我們已經用 tf.data 建立出一個可以拿來訓練語言模型的資料集了。

TensorFlow 2.0 預設就是 Eager Execution,因此你不再需要使用老朋友 tf.Session() 或是 tf.placeholder 就能非常直覺地存取數據:
# print 是用來幫你理解 tf.data.Dataset
# 的內容,實際上存取資料集非常簡單
# 現在先關注下面的 print 結果
for b_inp, b_tar in ds.take(1):
print("起始句子的 batch:")
print(b_inp, "\n")
print("目標句子的 batch:")
print(b_tar, "\n")
print("-" * 20, "\n")
print("第一個起始句子的索引序列:")
first_i = b_inp.numpy()[0]
print(first_i, "\n")
print("第一個目標句子的索引序列:")
first_t = b_tar.numpy()[0]
print(first_t, "\n")
print("-" * 20, "\n")
d = tokenizer.index_word
print("第一個起始句子的文本序列:")
print([d[i] for i in first_i])
print()
print("第一個目標句子的文本序列:")
print([d[i] for i in first_t])
為了讓你理解資料集回傳的內容,上面用了不少 print。但事實上這個資料集 ds 負責的就是每次吐出 2 個 128 筆數據的 Tensor,分別代表輸入與輸出的批次數據(Batch)。
而每筆數據則包含了一個長度為 10 的數字序列,代表著天龍八部裡頭的一段文本。
減少一些 print,你要從資料集 ds 取得一個 batch 的輸入/輸出非常地簡單:
for b_inp, b_tar in ds.take(1):
# 蒙多想去哪就去哪
# 想怎麼存取 b_iup, b_tar 都可以
print("b_inp 是個 Tensor:\n")
print(b_inp)
print("\nb_tar 也是個 Tensor,")
print("只是每個數字序列都是"
"對應的輸入序列往左位"
"移一格的結果\n")
print(b_tar)
4. 定義能解決問題的函式集¶
呼!我們花了不少時間在建構資料集,是時候捲起袖子將這些資料丟入模型了!

回想資料集內容,你現在應該已經很清楚我們想要模型解決的問題是什麼了:丟入一個數字序列,模型要能產生包含下個時間點的數字序列,最好是跟當初的輸出序列一模一樣!
如同我們在 AI 如何找出你的喵裡頭說過的:
任何類型的神經網路本質上都是一個映射函數。它們會在內部進行一連串特定的數據轉換步驟,想辦法將給定的輸入數據轉換成指定的輸出形式。
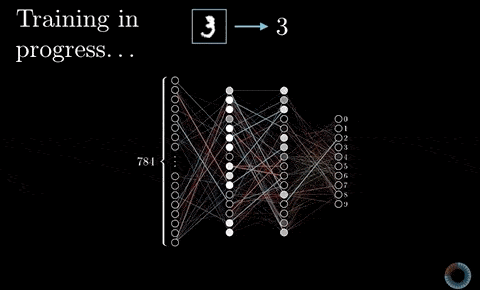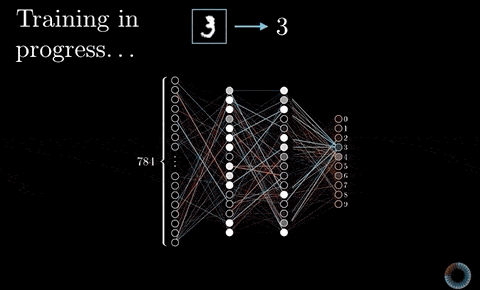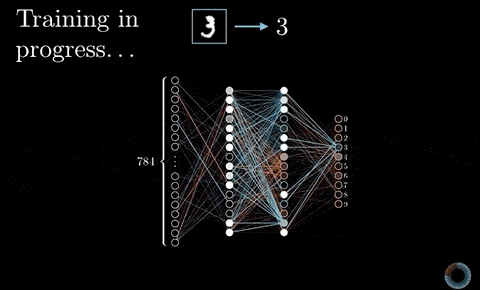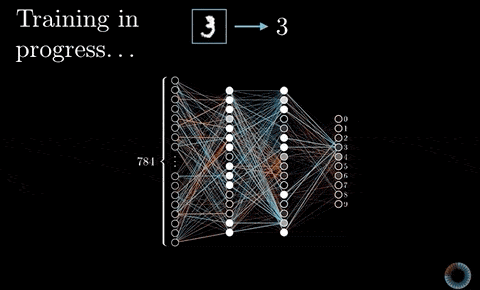
我們現在要做的就是定義一個神經網路架構,讓這個神經網路(或稱函式)幫我們把輸入的數字序列轉換成對應的輸出序列。
我們期待這個模型具有「記憶」,能考慮以前看過的所有歷史資訊,進而產生最有可能的下個中文字。
而在自然語言處理與深度學習入門指南我們也已經看到,循環神經網路中的 LSTM 模型非常適合拿來做這件事情。
因此雖然理論上你可以用任意架構的神經網路(如基本的前饋神經網路)來解決這個問題,使用 LSTM(或 GRU,甚至是 1D CNN)是一個相對安全的起手式。

在 TensorFlow 裡頭,使用 Keras API 建立一個神經網路就像是在疊疊樂,一層一層蓋上去:
# 超參數
EMBEDDING_DIM = 512
RNN_UNITS = 1024
# 使用 keras 建立一個非常簡單的 LSTM 模型
model = tf.keras.Sequential()
# 詞嵌入層
# 將每個索引數字對應到一個高維空間的向量
model.add(
tf.keras.layers.Embedding(
input_dim=num_words,
output_dim=EMBEDDING_DIM,
batch_input_shape=[
BATCH_SIZE, None]
))
# LSTM 層
# 負責將序列數據依序讀入並做處理
model.add(
tf.keras.layers.LSTM(
units=RNN_UNITS,
return_sequences=True,
stateful=True,
recurrent_initializer='glorot_uniform'
))
# 全連接層
# 負責 model 每個中文字出現的可能性
model.add(
tf.keras.layers.Dense(
num_words))
model.summary()

這邊我們建立了一個由詞嵌入層、LSTM 層以及全連接層組成的簡單 LSTM 模型。此模型一次吃 128 筆長度任意的數字序列,在內部做些轉換,再吐出 128 筆同樣長度,4330 維的 Tensor。

這跟你懷疑一個資料集的特徵 x 跟目標值 y 成線性關係,然後想用 a * x + b = y 的直線去 fit y 的道理是一樣的。
你相信 a * x + b = y 形式的映射函數能幫你把輸入 x 有效地對應到目標 y,你只是還不知道最佳的參數組合 (a, b) 該設多少罷了。
同理,很多研究結果顯示 LSTM 模型能很好地處理序列數據,我們只是還不知道最適合生成天龍八部文章的參數組合是什麼而已。
參數 a 以及 b 有無限多種組合,而每一組 a 與 b 的組合都對應到一個實際的函數。每個函數都能幫你把 x 乘上 a 倍再加上 b 去 fit 目標值 y,只是每個函數的表現不一而已。而把所有可能的函數放在一起,就是所謂的函數集合。

針對 a * x + b = y 這個簡單例子,我們可以直接用線性代數從整個函式集合裡頭瞬間找出最佳的函數 f(即最佳的 (a, b))。
而在深度學習領域裡頭,我們會透過梯度下降(Gradient Descent)以及反向傳播算法(Backpropagation)來幫我們在浩瀚無垠的函式集合(如本文中的 LSTM 網路架構)裡頭找出一個好的神經網路(某個 1,300 萬個參數的組合)。

幸好我們後面會看到,像是 TensorFlow、Pytorch 等深度學習框架幫我們把這件事情變得簡單多了。
5. 定義評量函式好壞的指標¶
有了資料集以及 LSTM 模型架構以後,我們得定義一個損失函數(Loss Function)。
在監督式學習裡頭,一個損失函數評估某個模型產生出來的預測結果 y_pred 跟正確解答 y 之間的差距。一個好的函式/模型,要能最小化損失函數。
有了損失函數以後,我們就能讓模型計算當前預測結果與正解之間的差異(Loss),據此調整模型內的參數以降低這個差異。

依照不同情境、不同機器學習任務你會需要定義不同的損失函數。
如同前述,其實我們要 LSTM 模型做的是一個分類問題(Classification Problem):
給定之前看過的文字序列以及當下時間點的新輸入字,從 4330 個字裡頭預測下一個出現的字。
因此本文的問題可以被視為一個有 4330 個分類(字)的問題。而要定義分類問題的損失相對簡單,使用 sparse_categorical_crossentropy 是個不錯的選擇:
# 超參數,決定模型一次要更新的步伐有多大
LEARNING_RATE = 0.001
# 定義模型預測結果跟正確解答之間的差異
# 因為全連接層沒使用 activation func
# from_logits= True
def loss(y_true, y_pred):
return tf.keras.losses\
.sparse_categorical_crossentropy(
y_true, y_pred, from_logits=True)
# 編譯模型,使用 Adam Optimizer 來最小化
# 剛剛定義的損失函數
model.compile(
optimizer=tf.keras\
.optimizers.Adam(
learning_rate=LEARNING_RATE),
loss=loss
)
model.compile 讓我們告訴模型在訓練的時候該使用什麼優化器(optimizers)來最小化剛剛定義的損失函數。
完成這個步驟以後,我們就能開始訓練模型了。
6. 訓練並選擇出最好的函式¶
在完成前 5 個步驟以後,訓練一個 Keras 模型本身是一件非常簡單的事情,只需要呼叫 model.fit:
EPOCHS = 10 # 決定看幾篇天龍八部文本
history = model.fit(
ds, # 前面使用 tf.data 建構的資料集
epochs=EPOCHS
)
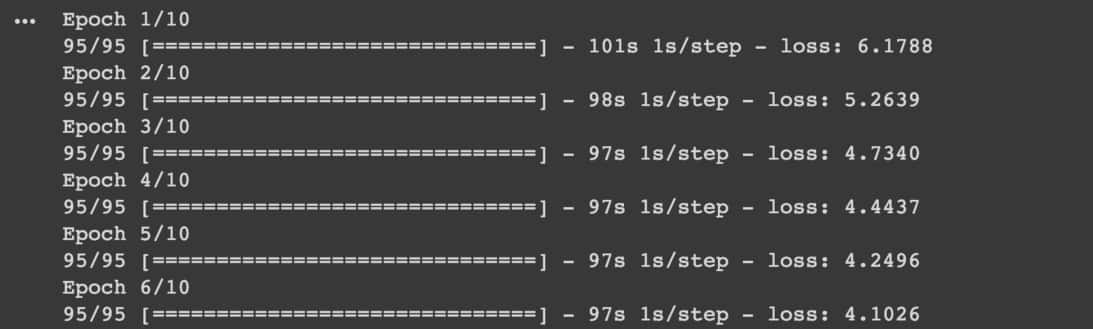
但很多時候你需要跑很多次 fit。
一般來說,你事先並不知道要訓練多少個 epochs 模型才會收斂,當然也不知道怎麼樣的超參數會表現最好。

大多時候,你會想要不斷地驗證腦中的點子、調整超參數、訓練新模型,並再次依照實驗結果嘗試新點子。
這時候 TensorFlow 的視覺化工具 TensorBoard 就是你最好的朋友之一:
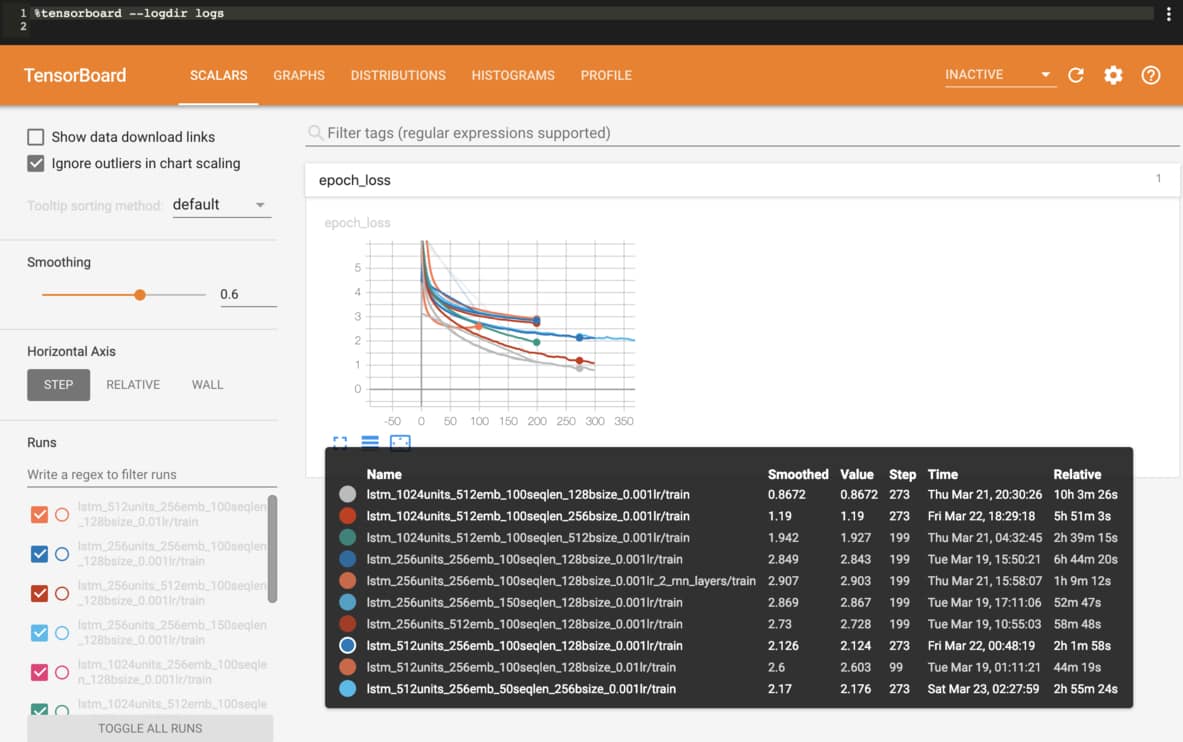
TensorFlow 2.0 新增了 JupyterNotebook 的 Extension,讓你可以直接在筆記本或是 Google Colab 上邊訓練模型邊查看結果。
跟以往使用 TensorBoard 一樣,你需要為 Keras 模型增加一個 TensorBoard Callback:
callbacks = [
tf.keras.callbacks\
.TensorBoard("logs"),
# 你可以加入其他 callbacks 如
# ModelCheckpoint,
# EarlyStopping
]
history = model.fit(
ds,
epochs=EPOCHS,
callbacks=callbacks
)
接著在訓練開始之後(之前也行)載入 Extension 並執行 TensorBoard 即可:
%load_ext tensorboard.notebook
%tensorboard --logdir logs
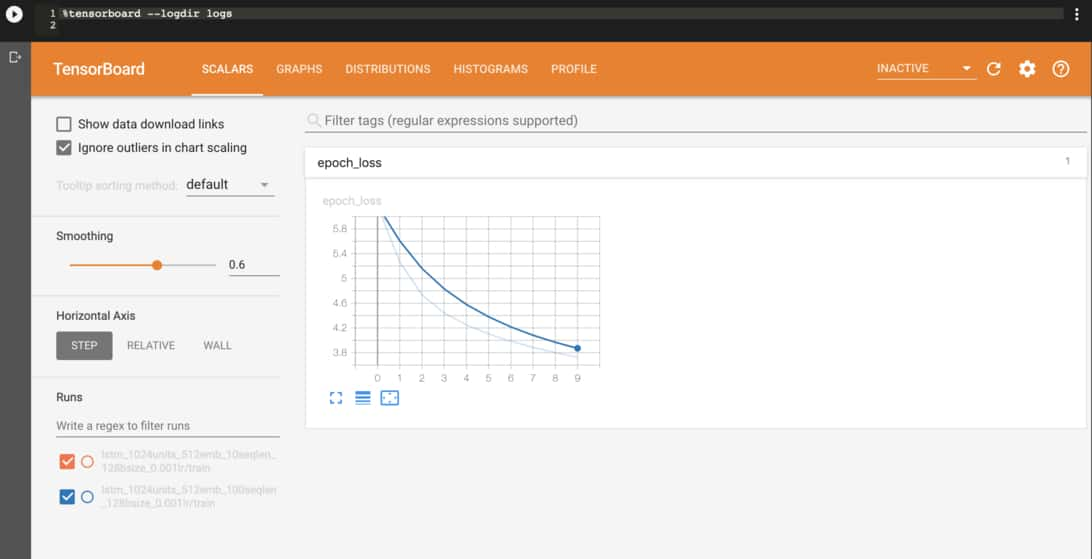
除了確保模型有一直努力在降低損失函數以外,我們也可以觀察模型在訓練過程中生成的文章內容。比方說給定一個句子:
喬峯指著深谷,
模型在完全沒有訓練的情況下生成的結果為:
喬峯指著深谷,鑠淆孤癸抑私磚簧麥笠簸殯膽稼匿聲罪殖省膻臆啟殖
》斥酒燥弄咪薔鬃衝矚理蝗驗吞柢舌滴漂撿毛等櫈磁槃鞭爛辣諱輝母犢楊拜攜戛婉額虐延久鋒幟懸質迸飭南軌忸瑩娘檔麵獎逍菌包怖續敗倨凍赭彈暖顴衽劑街榻裝貨啕畿驛吳

這模型並沒有中邪。只不過模型中 1,300 萬個參數的值完全隨機,你可不能期待模型能做什麼有意義的數據處理。
而在模型看了 20 遍天龍八部以後產生的結果:
喬峯指著深谷,說道:「我不知道,不是你的好人,你就是你的好。」木婉清道:「他……你……我……我……師父是誰?」
段正淳道:「王姑娘,你還是不是?」段譽道:「你說過的話,他……我……你……你……」
那女郎道:「嗯
結果差強人意,「你我他」後面只會加一大堆點點點。
但如果你仔細觀察,其實也已經有不少值得注意的地方:
- 模型已經知道怎麼產生正確的人名
- 知道
道後面要接冒號以及上括號 - 知道有上括號時後面應該要有下括號
- 知道要適時加入換行
這其實已經是不小的成就了!
而在看過 100 遍天龍八部以後產生的結果:
喬峯指著深谷,往前走去。
段譽見到這等慘狀,心下大驚,當即伸手去撫摸她的頭髮,心想:「我想叫你滾出去!」一面說,一面擤了些鼻涕拋下。
那大漢掙扎著要站起身來,只見一條大漢身披獸皮,眼前青光閃閃,雙手亂舞
擤了些鼻涕拋下 很不段譽,但我還是笑了。
文章本身順暢很多,而且內容也豐富不少。另外用字也挺天龍八部的。

你應該也已經注意到,句子之間沒有太大的故事關聯性。而這邊帶出一個很重要的概念:
這個語言模型只能學會天龍八部裡頭字與字之間的統計關係,而無法理解金庸的世界觀。
因此不要期待模型每次都能產生什麼深具含義的結果。
儘管還不完美,到此為止我們手上已經有訓練過的模型了。讓我們拿它來產生新的文本了吧!
7. 將函式 / 模型拿來做預測¶
大部分你在深度學習專案裡頭訓練出來的模型可以直接拿來做預測。
不過因為循環神經網路傳遞狀態的方式,一旦建好模型,BATCH_SIZE 就不能做變動了。但在實際生成文章時,我們需要讓 BATCH_SIZE 等於 1。
因此在這邊我們會重新建立一個一模一樣的 LSTM 模型架構,將其 BATCH_SIZE 設為 1 後讀取之前訓練時儲存的參數權重:
# 跟訓練時一樣的超參數,
# 只差在 BATCH_SIZE 為 1
EMBEDDING_DIM = 512
RNN_UNITS = 1024
BATCH_SIZE = 1
# 專門用來做生成的模型
infer_model = tf.keras.Sequential()
# 詞嵌入層
infer_model.add(
tf.keras.layers.Embedding(
input_dim=num_words,
output_dim=EMBEDDING_DIM,
batch_input_shape=[
BATCH_SIZE, None]
))
# LSTM 層
infer_model.add(
tf.keras.layers.LSTM(
units=RNN_UNITS,
return_sequences=True,
stateful=True
))
# 全連接層
infer_model.add(
tf.keras.layers.Dense(
num_words))
# 讀入之前訓練時儲存下來的權重
infer_model.load_weights(ckpt_path)
infer_model.build(
tf.TensorShape([1, None]))
除了讀取權重,這段程式碼對你來說應該已經十分眼熟。有了 infer_model 以後,接著我們要做的就是:
- 將起始文本丟入模型
- 抽樣得到新的中文字
- 將新得到的字再丟入模型
- 重複上述步驟
而實際預測的流程大概就長這個樣子:
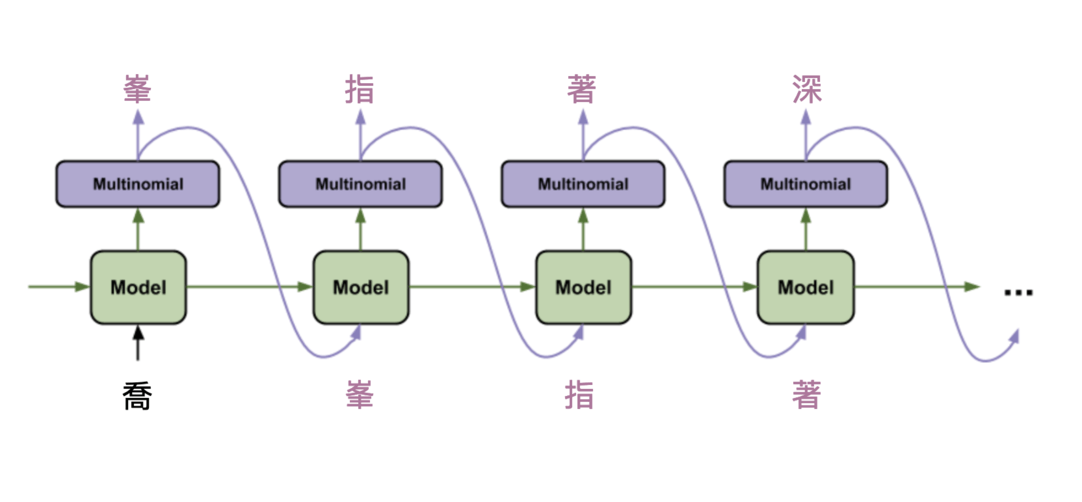
如同我們在生成新的天龍八部橋段所看到的,依照你設定的生成長度,我們需要重複上述步驟數次。
而要執行一次的抽樣也並沒有非常困難:
# 代表「喬」的索引
seed_indices = [234]
# 增加 batch 維度丟入模型取得預測結果後
# 再度降維,拿掉 batch 維度
input = tf.expand_dims(
seed_indices, axis=0)
predictions = infer_model(input)
predictions = tf.squeeze(
predictions, 0)
# 利用生成溫度影響抽樣結果
predictions /= temperature
# 從 4330 個分類值中做抽樣
# 取得這個時間點模型生成的中文字
sampled_indices = tf.random\
.categorical(
predictions, num_samples=1)
抽樣的程式碼為了方便解說有稍作刪減,如果你要實際動手跑看看,請參考官方的 Text generation with an RNN。
這邊我想要你看到的重點是如何利用生成溫度 temperature 的概念來影響最後的抽樣結果。
如同 demo 時說明的:
生成溫度是一個實數值,而當溫度越高,模型產生出來的結果越隨機、越不可預測
模型的輸出為一個 4330 維度的 Tensor,而其中的每一維都對應到一個中文字。維度值越大即代表該字被選到的機會越大。
而當我們把整個分佈 predictions除以一個固定值 temperature 時,越大的值被縮減的程度越大,進而讓各維度之間的絕對差異變小,使得原來容易被選到的字被抽到的機會變小,少出現的字被選到的機會稍微提升。
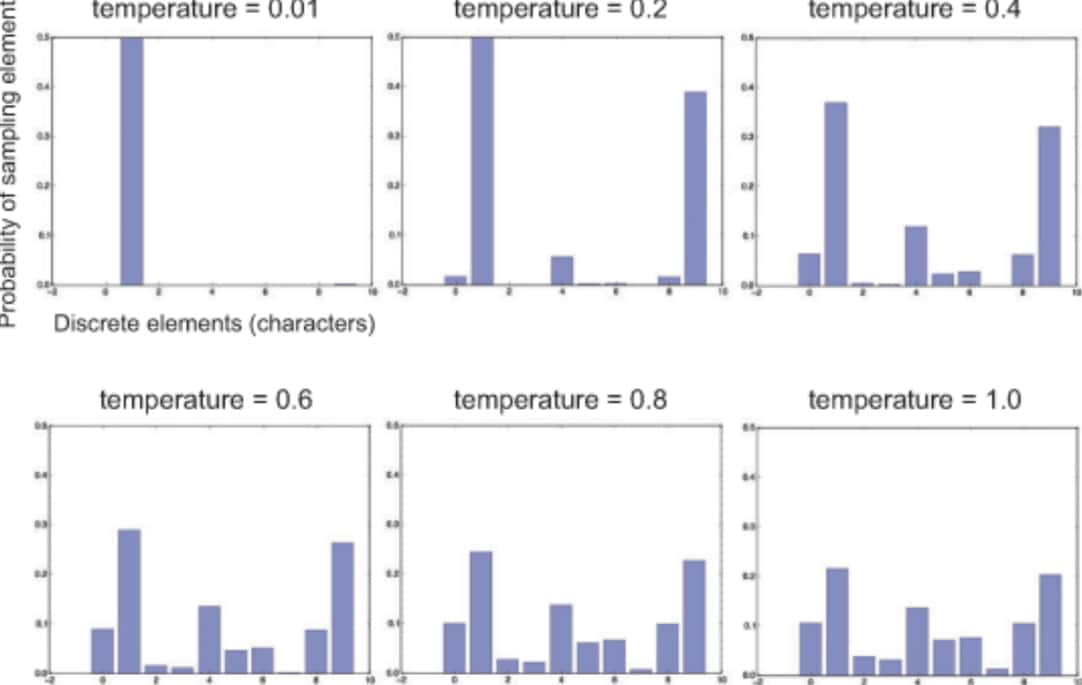
這就是為何我們會想手動調整生成溫度的原因。
如何使用 TensorFlow.js 跑模型並生成文章¶
雖然本文以天龍八部為例,事實上你已經了解如何使用 TensorFlow 2.0 來架構出一個能產生任意文本的 LSTM 模型了。
一般而言,只要你把剛剛生成文本的 Keras 模型儲存下來,接著就可以在任何機器或雲端平台(如 GCP、AWS)上進行生成:
infer_model.save("model.h5")
最近適逢 TensorFlow.js 推出 1.0.0 版本,我決定嘗試使用 tfjs-converter 將 Keras 模型轉換成 TensorFlow.js 能夠運行的格式:
tensorflowjs_converter \
--input_format=keras \
model.h5 \
tfjs_model_folder
轉換完成後會得到 tfjs 的模型,接著只要把它放到伺服器或是 Github 上就能在任何靜態網頁上載入模型:
model = tf.loadLayersModel("url");
const output = model.predict(input);
我們在由淺入深的深度學習資源整理就曾介紹過 TensorFlow.js,他們有很多有趣的 Demos,想要在瀏覽器上實作 AI 應用的你可以去了解一下。
使用 TensorFlow.js 好處在於:
- 隱私有保障。使用者上傳、輸入的內容不會被上傳到伺服器
- 開發者不需租借伺服器或是建置 API 端點,無部署成本
當你能把模型讀入瀏覽器以後,只要將我們剛剛在前面介紹過的 Python 邏輯利用 TensorFlow.js API 實現即可。
熟悉 JavaScript 的你甚至還可以直接在瀏覽器上訓練類似本文的 LSTM 模型並生成文章。
結語¶
感謝你花費那麼多時間閱讀本文!
回顧一下,我們在文中談了非常多的東西:
- 如何利用深度學習 7 步驟開發 AI 應用
- 定義問題及要解決的任務
- 準備原始數據、資料清理
- 建立能丟入模型的資料集
- 定義能解決問題的函式集
- 定義評量函式好壞的指標
- 訓練並選擇出最好的函式
- 將函式 / 模型拿來做預測
- 了解如何利用深度學習解決序列生成任務
- 熟悉 TensorFlow 2.0 的重要功能
- tf.keras
- tf.data
- TensorBoard
我們也看到你可以如何運用 tfjs-converter 將 Python 與 JavaScript 這兩個世界結合起來,建立可以給任何人在任何裝置上執行的 AI 應用。
除了可以被用來解決「被動」的分類、迴歸問題,近年深度學習在「主動」的生成任務上也展現了卓越的成果。廣為人知的應用有 Google 的 DeepDream、神經風格轉換以及最近 NVIDIA 將塗鴉轉成風景照的例子。
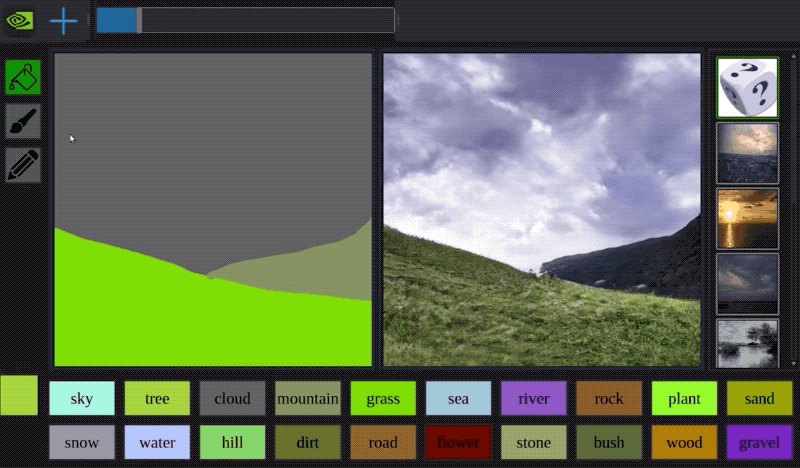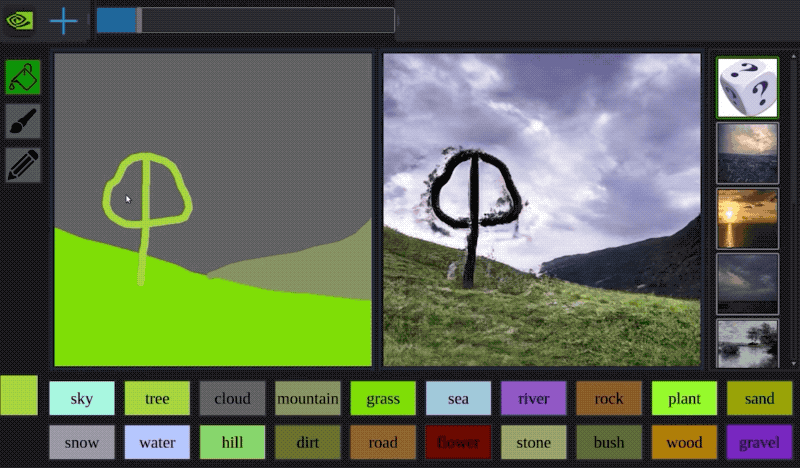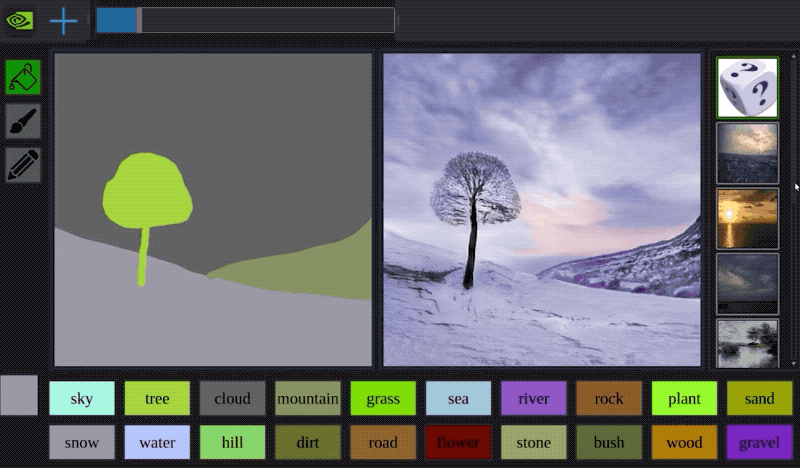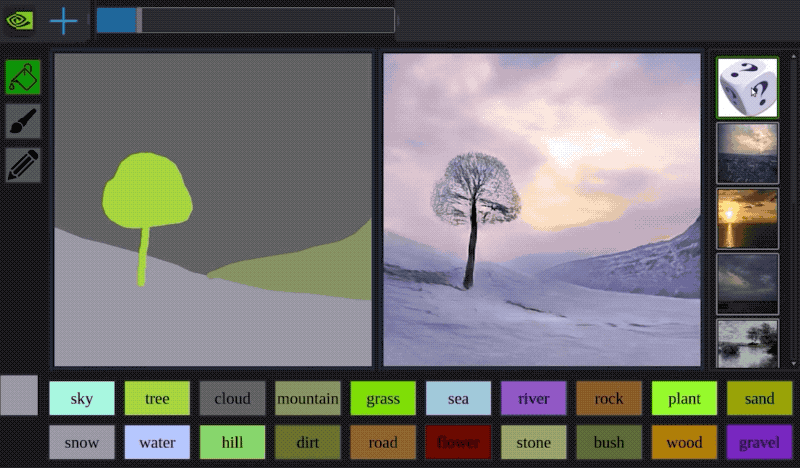
就像本文的天龍八部生成,儘管還未臻完美,讓機器自動生成全新、沒人看過的事物一直是人類追求的夢想之一。但這些人工智慧(Artifical Intelligence)的研究並不是一味地追求如何取代人類智慧;反之,AI 更像是增強我們的智慧(Augmented Intelligence):
最好的 AI 是為了讓我們的生活充滿更多智慧,而非取代我們的智慧。AI 能擴充我們對世界的想像,讓我們看到更多不同的可能性。

能一路聽我碎碎唸到這裡,代表你對 AI 以及深度學習的應用是抱持著很大的興趣的。希望在此之後你能運用本文學到的知識與技術,實踐你的瘋狂點子並分享給我知道。另外,如果你有興趣了解如何使用更進階、更強大的語言模型來生成比 LSTM 還厲害的金庸小說,可以參考另篇文章:直觀理解 GPT-2 語言模型並生成金庸武俠小說。
就這樣啦!現在我得回去看還沒看完的天龍八部了。
跟資料科學相關的最新文章直接送到家。 只要加入訂閱名單,當新文章出爐時, 你將能馬上收到通知