監控資本主義在 21 世紀主導資料科學以及 AI 的發展方向,並持續往大多數人不樂見的方向邁進。只有在大眾能夠認知到並理解其商業邏輯,我們才能透過集體意識去改善每個人的數位未來。
─ 1 分鐘懶人包
這是本文最想傳達的訊息。因為資訊量龐大,如果你現在還無法消化也沒有關係。閱讀完本文,你將能夠了解在背後驅使數位世界光速運轉的商業邏輯,並用一個可說是駭人卻又無比清晰的視角理解自己正身處在一個怎麼樣的數位時代。
引言¶
2018 年 5 月,我在揭開資料科學的神秘面紗中粗略地說明過為何注意力經濟(Attention Economy)促使近年大數據、資料科學以及人工智慧的蓬勃發展。注意力經濟將人類的注意力視為資訊過載時代下最寶貴的資源,而谷歌(Google)與臉書(Facebook)在一般使用者不知情或是沒有明確允許的情況下貪婪地蒐集、累積、分析進而預測其廣告點擊行為。他們想盡辦法使你我對其服務上癮,以將我們有限的注意力榨取成龐大的商業利益。
長年下來,越來越多人注意到「免費」的代價並看到此經濟邏輯的可怕之處,不少專家則開始將此經濟邏輯與商業模式稱之為監控資本主義(Surveillance Capitalism)。

今天我想用簡單的經濟學、心理學與資料科學的角度帶你理解其背後的運作原理以及其對人類社會帶來的負面影響。
本文章節安排¶
儘管其商業模式早就統治了我們的世界,關於監控資本主義的結構性描述一直要等待哈佛商學院榮譽教授肖莎娜・祖博夫(Shoshana Zuboff) 的《監控資本主義時代》(後簡稱為《監控》)出版後才比較被一般大眾所知。此書也名列歐巴馬在 2019 年最愛的書籍之一。
我在第一章會先以知名的臉書為例,簡述科技公司現在是如何監控我們的數位行為。接著,我將花 2 個章節跟你一起拿著祖博夫的放大鏡,用經濟學以及心理學直觀地理解監控資本主義的起源以及運作邏輯。然後我們會用資料科學 (Data Science)的視角來理解監控科技是如何被實現的。你將清楚地了解監控資本主義的商業邏輯是如何跟資料科學緊密耦合的。

閱讀完本文,你將能用更全面的視角思考這些大哉問:
- 為何社群網站助長了 2021 美國國會騷亂?
- 推特是否有權關閉美國總統川普帳號?
- 為何蘋果新的隱私權條款讓臉書大跳腳?
為了讓你更輕鬆地掌握本文架構,我也附上各章節的傳送門(你也可以點擊左側導覽圖例):
- 第一章 進入臉書監控你我的時代
- 第二章 以用戶出發的資訊服務:行為價值再投資循環
- 第三章 使用者淪為屍塊:發現並汲取大規模行為剩餘
- 第四章 數據神父手中的演算法與資料結構是生產手段
- 最終章 21 世紀第 3 個十年的認知革命
建議依序閱讀。

在了解監控資本主義及其利弊後(劇透:長遠的弊遠大於利),我在最終章則會說明你能做些什麼來讓自己身處的數位環境變得更好。在繼續閱讀之前,我想給你個「自我數位專注挑戰」:看你能不能在將本文閱讀完以前都不做以下行為:
- 不點開任何 App 送給你的通知
- 不回覆任何電子郵件以及訊息
- 不滑臉書、推特、IG 和 YouTube(除了文中嵌入的影片)
我得承認這在現代非常不易做到。如果當前的客觀環境不允許,把本文存入書籤或 Pocket 並為自己找個能在 30 分鐘內專注閱讀並思考的地點與時間吧!閱讀完本文並完成挑戰的你將會發現,從中獲益最多的人將是自己。
第一章 進入臉書監控你我的時代¶
前陣子我在 Dcard 的一個分享會上問了台下的聽眾一個簡單的問題:
有多少人有這樣的經驗:在滑臉書時跳出了某個「準」到不行、燒到你的廣告,讓你相信臉書正在「監視」你的瀏覽網頁與朋友的聊天記錄或是「監聽」你的麥克風?
毫不意外地,幾乎所有人都舉了手。大家都能想像臉書、谷歌與推特(Twitter)等科技公司的廣告以及內容推薦系統(Recommender system, 在後面章節我們會討論它)在螢幕的另一頭「監控」著我們數位足跡的事實。
第一次是我在使用 Messenger 時無意間跟朋友提到「奶粉」,接著大腦就被硬生生地植入一個自己從沒聽過、這輩子估計也不會曉得的奶粉商的廣告,無力抵抗。對廣告麻木的人可能覺得「只是個廣告,大驚小怪」。但這實際隱含的是:臉書可以在用戶不知情或是不情願的情況下,透過蒐集其行為數據來預測並改變用戶對世界的認知。改變了認知,就能在你我沒有意識到的情況下操弄我們的行為,使得我們的「行為」符合他們與廣告商承諾的「保證結果」:使用者點擊(clicks)。
順帶一提,你可以透過鮮為人知的 Facebook 站外動態功能查看臉書透過上述影片的方法(即 Facebook 像素)從網路蒐集到的你的行為。資料顯示,臉書目前已經從 235 個應用程式以及網站蒐集到我的數位行為以進行再行銷(retargeting):將我曾拜訪過的網站的產品在我下次「免費」滑臉書時透過其競標系統推出我的「個人化」廣告以誘使我點擊。
截至 2020 年 10 月為止,臉書的每日用戶數達到 18.2 億人,意味著每一天全球都會有 24% 的人口造訪臉書並接受臉書為他們精心打造的「個人化」貼文與廣告。這可是人類歷史上最成功的實時監控系統之一,也超越任何極權主義家的瘋狂夢想。
事實上,祖博夫在《監控》裡就表示,這些私營科技公司跟被稱為數位極權主義的中國信用系統的差別,只在於前者是以經濟取向發展監控科技,後者則是為了政治權力。很多人忘了這些科技公司存在這世上的最大目的始終都是最大化股東價值,而不是優化你我的心理健康、減少假新聞傳播、避免社會分裂或是確保民主價值。

在對一般民眾說明時,臉書與谷歌等科技公司一直以來都將「監控」解釋為科技發展下的必然結果以及實現個人化(personalization)的必要之惡(或是否認有這回事)。但近年越來越多的用戶意識到了矛盾:一方面確實感受到這些服務帶給自己的便利之處,另一方面則持續感受到自己的隱私受到侵犯以及無可自拔的科技上癮。
全世界只有兩種產業把客戶稱為「使用者」,一個是毒品,一個是軟體。
─ 統計學家 愛德華塔夫特
Netflix 劇情紀錄片《智能社會:進退兩難》(The Social Dilemma)生動地描述了這樣的情境。透過對自己親手打造的產物敲響警鐘的科技專家,該片探究了社群媒體的危險人為影響,如陰謀論的廣泛傳播、青少年心理健康議題以及政治極化。
另一部紀錄片《個資風暴:劍橋分析事件》(The Great Hack)則探究名為劍橋分析的數據公司如何不當地取得 5000 萬名臉書使用者的個資(超過全台灣人口的 2 倍)並在 2016 年美國總統選舉後成為社群媒體黑暗面的象徵。
接下來的章節在探討監控資本主義時會以《監控》一書的內容為主,上述紀錄片的內容為輔(本文截圖之使用已獲 Netflix 同意)。想保留觀影新鮮感的讀者可以先去觀看這兩部紀錄片再回來閱讀本文(好啦,你可以重新開始專注挑戰)。
第二章 以用戶出發的資訊服務:行為價值再投資循環¶
文章開頭我以臉書作為當代監控資本家的一個例子,不過事實上依照《監控》一書的描述,谷歌才是監控資本主義的先驅。谷歌之於監控資本主義,如同一百年前的福特汽車或通用汽車之於工業資本主義。
為了更好地理解監控資本主義,讓我們先把時針倒回到距今超過 20 年前的 1998 年,也就是谷歌成立的那一年。
在谷歌成立時已經有 Mosaic 等瀏覽器讓所有電腦使用者都能連上全球資訊網。最初,谷歌也實踐了資訊資本主義的承諾,提供免費的線上搜尋服務讓大眾搜尋數位資訊。憑藉著卓越的搜尋引擎(Search Engine),谷歌搜尋的使用者越來越多。僅僅不到一年,谷歌的搜尋引擎就得每天處理 700 萬筆搜尋指令,這些搜尋指令也是使用者與系統互動的主要方式。
每位用戶的每個行動,都視為可進行分析並再次投進系統中的信號。
─ 范里安, 谷歌首席經濟學家
但之後讓谷歌跟其他搜尋服務競爭者拉開距離的,是谷歌工程師將自家的搜尋引擎轉變成一個能持續學習的遞迴系統。他們透過「使用者與系統互動所產生的行為副產品」來持續改善搜尋結果並刺激產品創新:拼字檢查、翻譯以及語音辨識。
有些人也把「行為副產品」稱作數據廢氣(Data Exhaust),也就是谷歌搜尋指令的附帶數據,比方說搜尋詞彙的拼字、停留時間、點擊模式以及地點。谷歌發現,這些儲存在數據緩存內的行為副產品能用來「回推」出每位使用者的思想、感受以及興趣。被譽為「谷歌經濟學的亞當・斯密」的哈爾・范里安則表示這是逆向工程(reverse engineering):從使用者的行為數據回推他或她的意圖,提供更相關的搜尋結果。
在谷歌搜尋引擎發展的初期,其使用者無意間提供的珍貴行為數據,全部都被谷歌拿來提昇服務品質並「全然」回饋給使用者,比方說提升搜尋的精確度與相關性。《監控》作者祖博夫將這種從用戶出發的循環稱之為行為價值再投資循環(Behavioral Value Reinvestment Cycle):行為數據中隱含的價值經過再投資後被用來提升產品或服務品質。
在這個循環裡頭,谷歌跟使用者互相需要,達到一種力量平衡:
- 用戶需要「使用」谷歌的優秀搜尋功能完成知識獲取的需求
- 谷歌需要「消耗」用戶創造的價值來改善產品,而該價值可從用戶的行為副產品中汲取
群眾被視為企業營運的唯一目的,跟谷歌使命:「彙整全球資訊,供大眾使用,使人人受惠。」的宗旨完美契合。
當初一切看來都是那麼地美好,令人莞爾。
但如果你是當初在 1999 年投資谷歌並急著想要回本的矽谷創投企業家,可能就笑不出來了。因為值得聲明的是谷歌的這個循環還不是你在下個章節會看到的監控資本主義,甚至不是你在大一經濟學碰過的資本主義(Capitalism)。谷歌搜尋引擎的這個行為價值再投資循環並無法將資金轉為收益。
資本主義是一齣由每一個投資者、員工、企業家、消費者攜手演出的一場毫無是非道德之分的鬧劇。
─ 《矽谷潑猴》
雖然此循環概念是效仿之前蘋果(Apple Inc.)大紅大紫的 iPod 而來,谷歌並不像蘋果那樣具有 iPod 或數位歌曲。沒有利潤、沒有盈餘,完全沒有可銷售並轉換成收益的「實體商品」。
在谷歌與使用者之間完美的力量平衡下,向使用者收費會帶來極高財務風險,而在未付費的情況下把谷歌的網路爬蟲(web crawler)從他人手中取來的索引資訊貼上價格也是非常危險的先例。

第三章 使用者淪為屍塊:發現並汲取大規模行為剩餘¶
為了減輕投資者們的焦慮,谷歌宣告例外狀態以擁抱廣告。但該怎麼說服成千上萬名用戶呢?
為了向大眾合理化新的商業操作,谷歌創辦人賴利歐・佩吉(Larry Page)決定不走當年盛行的廣告關鍵字模式,堅持廣告商不能干預關鍵字的選擇:谷歌會替他們選擇關鍵字。谷歌向大眾表示會利用蒐集到的大量數據、運算能力以及科技專長確保如果「搜尋時顯示了廣告」,這些廣告也會保證跟「下搜尋指令的使用者相關」。

換句話說,這意味著谷歌會將特定廣告「對準」特定用戶,而不是讓廣告跟使用者搜尋指令中特定的關鍵字相連。秉持這項原則,谷歌宣稱可以兼顧所有人的顧慮:
- 投資者角度:穩定獲取利潤並使其成指數增長
- 廣告商角度:確保自己廣告能被目標用戶點擊
- 使用者角度:谷歌顯示的廣告會與其高度相關
上面這套操作要成功,關鍵不在技術實現,而在於谷歌得暗中「監視」。如果當年谷歌公開跟每位使用者說:
嘿!我為了過活,要拿你的搜尋以及網路上的行為數據去建構你的個人檔案喔!我還會把它拿去跟那些你這輩子沒聽過的廣告商的廣告比對,預估你會點擊哪一個。在你下次搜尋時我就會把廣告顯示出來給你看溜!別忘了點進去瞧瞧:)
基於最基本的隱私考量,我想應該沒有一個理性的用戶會直接點頭同意這筆交易的。
儘管沒跟大眾說白,谷歌與後來的臉書為了目標廣告投放將包含你在內的所有用戶都建檔了。諷刺的是,這檔案裡雖然都是關於你的數位資訊,但卻不是為了你而建立,因此自然也不會讓你存取或是認知到它的存在。《監控》一書將其命名為「影子文本」,相對於你在網路上看得到的所有公開資訊(公開文本)。
在這個商業模式底下,使用者的行為數據仍然會被用來提升服務品質,但是更多的附帶數據被用來建立能夠預測使用者點擊行為的預測產品(Prediction Products)。用了這些能精準預測用戶行為的產品後,谷歌在行為未來市場(Markets in Future Behaviors)讓貪婪的廣告商們即時競價使用者對廣告的曝光(impressions)以及未來的點擊行為。
你現在可以回顧一下剛剛前面看到的五角形。我們會在第四章詳細說明有哪些生產手段。
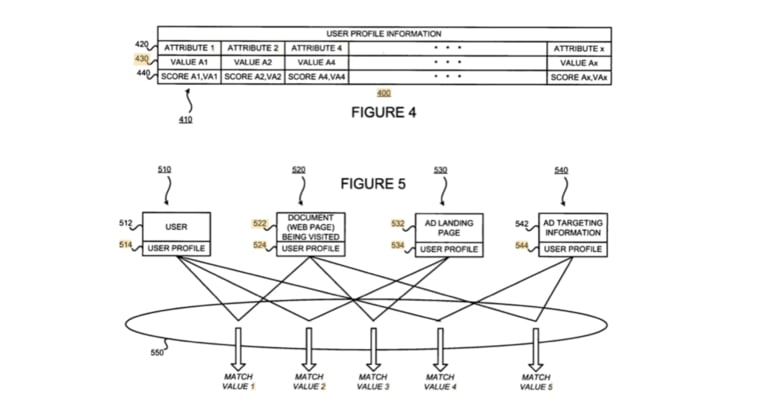
依據 2003 年谷歌持有的一個具指標性的專利《為廣告指定目標生成使用者資訊》(Generating User Information for Use in Targeted Advertising),谷歌掌握的行為剩餘包含但不限於:
- 使用者曾瀏覽之網頁
- 心理變數(別問我谷歌怎麼取得這項的,我也不知道)
- 瀏覽活動
- 使用者先前被選定或投放之廣告資訊
- 使用者是否在瀏覽廣告後出現消費行為
進入 21 世紀第 3 個十年,更新後的名單可能比本文還長了。這些使用者屬性/特質數據交互組合起來,就是專利內所謂的用戶檔案資訊(User Profile Information, UPI)。3 名谷歌頂尖的資訊工程科學家跟其真正的顧客:廣告商們表示,透過 UPI 就不用再玩傳統的廣告猜謎遊戲,不需浪費廣告預算就能夠確保使用者點擊。
而且他們也向顧客說明最大的瓶頸不是技術問題,而是社會層面的隱私問題:使用者可能不願交出自己的資料。但他們也讓顧客安心:他們有辦法在使用者不知情的情況下透過使用者行為推論、假設並演繹出其正確的 UPI 以跟廣告比對。
谷歌將每次點擊之價格,乘以他們估算的使用者點擊廣告之機率,並根據此運算結果,將最好的搜尋位置提供給可能支付最高報酬的廣告商,藉此最大化來自珍貴資產的收益。
─ 彭博社, 2006 年
要能估算成千上萬的使用者以及廣告組合的點擊機率,需要為每位使用者都建構出具代表性的 UPI。而要具代表性,自然需要蒐集特定使用者的大量行為剩餘。理解了這邏輯,谷歌便從一開始無意間「發現」行為剩餘,逐步演變成無所不用其極地「獵捕」用戶行為數據。而這一切都是為了能更精準地預測使用者的點擊行為。
當年彭博記者筆下的「珍貴資產」,正是谷歌在絕多數用戶不知情的情況下,從其與搜尋系統的互動轉換而來的行為剩餘。
至此,新的資本主義變種隨之誕生:谷歌用以致富的行為剩餘即為監控資產,其既為賺取監控收益的原物料,也是監控資本的重要來源。最適合用來描述這套資本累積邏輯的詞彙,自然就是監控資本主義(Surveillance Capitalism)了。依據 2020 財年第三季度財報,谷歌母公司 Alphabet 的整體營收達到 461.7 億美元(約新台幣 1 兆 3205 億元),而其中廣告收入就佔了 8 成(包含搜尋廣告以及 YouTube 廣告)。
為了最大化其監控收益,谷歌在 21 世紀發展了一系列監控科技以及免費服務,務求讓每位使用者都能像隻小老鼠一樣,持續盯著眼前誘人的數位內容並在轉輪上留下數位足跡。監控資本家想不斷地從我們的數位與實體行為中汲取出不只更大量,還要更多元的行為剩餘。除了搜尋以外,我們還有其他便利的飼料:
深諳監控資本主義邏輯的企業家們朗朗上口的台詞:「數據是新的石油!」背後真正的意思昭然若揭。

說白點,在監控資本主義裡頭實際進行價值交換的主體是谷歌與廣告商。我們這些使用者只是原物料(行為剩餘)抽取以及徵收的目標。因此你可能聽人說過:「如果有什麼東西免費,那真正的商品其實就是你。」
但《監控》一書的作者祖博夫針對這句話有更進一步的說明。她認為谷歌與臉書等監控資本家盜獵我們行為剩餘的程度,恰似盜獵者為了象牙殘殺大象的暴行,扔下我們體內、腦內、跳動心臟內蘊含的意義。她表示前面那句已經過時,事實上:
你才不是商品,你是被捨棄的屍塊,真正的「商品」源於從你人生奪取的剩餘。
─ 《監控資本主義時代》
在監控資本主義的思維下,要賺取更多的廣告收益,就需要更多的廣告點擊。因此「跟使用者相關」很自然地就跟「使用者點擊」劃上了等號。谷歌創造了新的人類行為預測科學:「點擊物理學」,持續召募最聰明的 AI 人才去優化上述五角形中的生產工具,為的是更精準地預測使用者對個人化廣告的點擊率(Click-Throught Rate, CTR)。
一般來說,這些複雜的廣告預測系統的最佳化目標是最大化 CTR,因此並不會關心(也沒有意識)一名特定用戶在點擊某廣告時,內心是憤怒、悲傷還是快樂的。「我其實不在乎你的想法、感受或是靈魂,但我要確保你的(點擊)行為符合我的預測。」這樣的激進想法是監控資本主義從激進行為主義(Radical behaviorism)的「以他人觀點客觀地觀察某生物個體在環境中的行為」延伸而來,祖博夫則將其稱為「激進冷漠」。
谷歌透過這樣的想法打造出來的預測產品是所有公司夢寐以求的:能夠保證只要刊登廣告,就會有不錯的效果。一個谷歌能夠向其真正的顧客:廣告商販賣近似確定性(certainty)的市場:只要你給我足夠的錢,我就能用自家的預測產品給你要的保證結果:保證讓負責點擊的使用者買單。

在絕大多數用戶還不知情的情況下,處於市場循環之外的使用者就已不再是 21 世紀多數科技公司營運的主要目的,淪落成了一個手段,一個為了達成陌生、貪婪廣告商的營利目的的手段。以上就是長達 800 頁的《監控資本主義時代》想傳達的核心概念。相信你現在也對其有一定的瞭解了。
對某些人來說,這一切可能聽起來十分地黑暗且令人焦慮。或許還會有人選擇直接視而不見並關掉此頁面。但要馴服一頭野獸,我們得先克服恐懼、直視它的雙眼並嘗試理解。轉頭奔逃很有可能只會讓你更快被其吞噬。
要能建立精準的預測產品,比方說廣告推薦系統,只有大量的行為剩餘是不成氣候的。監控資本家也需要全新的生產手段來打造這些資訊系統。在了解監控資本主義的商業操作以後,讓我們用資料科學的角度看看科技公司是怎麼打造這些神奇產品的。
喔對了!值得一提的是,與谷歌及臉書「冷漠」的廣告競標系統相比,採付費訂閱制的電影推薦服務 Netflix 比較有「人性」,看似接近以用戶出發的資訊服務。但一般內容推薦系統仍有其原罪:「無上限」地渴望著用戶的「有限」注意力,因此這類服務(Netflix 上看不完的電影、推特滑不完的動態 )都存在著讓用戶沈迷於其服務的隱憂。
第四章 數據神父手中的演算法與資料結構是生產手段¶
《監控》一書將打造預測產品的「全新生產技術」(請回顧前一章的五角形)統稱為機器智慧(Machine Intelligence),對應到我們已耳濡目染的資訊科技技術:人工智慧、資料科學、深度學習(Deep Learning)以及預測分析。而使用這些技術打造預測模型的資料工程師、資料科學家以及機器學習工程師就是祖博夫筆下的「數據神父」。
用「機器智慧」來概括監控資本主義中的科技很方便,卻也讓前幾章對監控資本家們的「指控」顯得十分抽象。在這章節裡,我會用資料科學的角度描述數據神父們是如何地實作對科技公司來說最重要的預測產品:推薦系統。這章內容能讓你更直觀地連接監控資本主義的商業邏輯以及與之掛鉤的資料科學概念。
回到上古時代:基於協同過濾的推薦系統¶
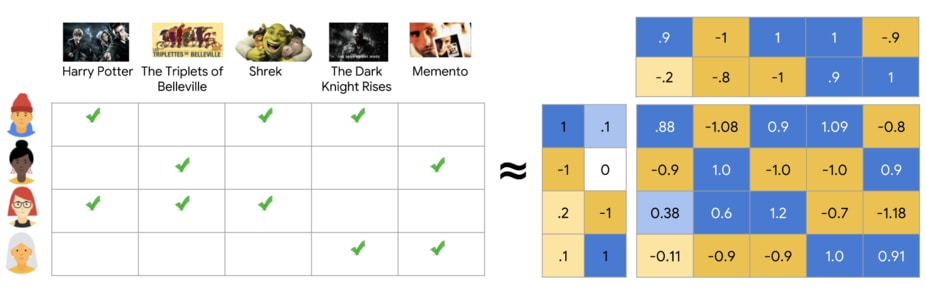
我在 2015 年完成 Coursera 上的推薦系統課程時,協同過濾(collaborative filtering)仍是初學者必學的推薦方法之一。以 Netflix 的電影推薦場景來說,其原理是透過矩陣拆解(matrix decomposition)將所有用戶與所有物品互動的矩陣(電影評分紀錄) $\mathbf{A}$ 拆解成最具代表性的用戶潛在興趣矩陣 $\mathbf{U}$ 與物品潛在屬性矩陣 $\mathbf{V^{T}}$,使得 $\mathbf{U}\mathbf{V}^{T} \approx \mathbf{A}$。
一旦有了這兩個子矩陣,我們就能預測任意使用者 $u$ 給任意電影 $v$ 的評分(先不考慮新用戶)。該系統只要在用戶登入時將他或她還沒看過的電影的預測分數從高到低排序,並把預測評分前 N 個大的電影顯示給該用戶即可完成最簡單的電影推薦。這邊值得一提的是,任一用戶只能存取自己的評分紀錄(公開文本),而 Netflix 可以存取截至 2020 年為止其在全球獲得的近 2 億訂閱用戶的所有評分行為(影子文本),創造了和單一用戶之間龐大的知識與力量鴻溝。
另外在推薦系統領域中,所有人都已習慣將每一名用戶簡化為一個紀錄其喜好的高維向量了。
快轉到基於深度學習的推薦系統王朝¶
2016 年,Google Play 推薦團隊推出 Wide & Deep 模型,整合邏輯回歸(logistic regression)以及深度神經網路(deep neural network)的優點來做 App 推薦並看到卓越的指標提昇。隨後業界爭相使用此架構(或其變形)來改善自家的推薦系統。此研究也是讓深度學習更快普及到推薦系統領域的主要推手之一。
谷歌的論文用實際的業務成長說明其模型的卓越性。谷歌對當時的用戶進行線上 A/B 測試:讓 1 % 的用戶繼續使用原始版本的 App 推薦系統(對照組),讓另外 1% 的用戶使用類神經網路加持的 Wide & Deep 模型(實驗組)。實驗結果顯示谷歌可以讓實驗組在 Google Play 多點擊下載 3.9% 的應用程式。要知道 Google Play 在 2016 年有 550 億下載,到了 2020 年更達到上千億。以這個規模來評估模型帶來的影響力就十分驚人了。當然,一般用戶不會知曉這場偉大的實驗。
在 App 推薦取得巨大突破後,沒道理不應用到指定目標廣告投放的點擊率預測。你一樣可以把每一個廣告商的廣告視為一個物品,並依據用戶過去的點擊與瀏覽行為去預測他/她點擊每個廣告的機率。搭配無數廣告商的競標預算,谷歌在你搜尋任何東西時顯示他們有信心能讓你點擊的廣告。2017 年史丹佛大學與谷歌的 Deep & Cross Network for Ad Click Predictions 的論文標題就直白地說明了他們是改造 Wide & Deep 模型來做廣告點擊預測。
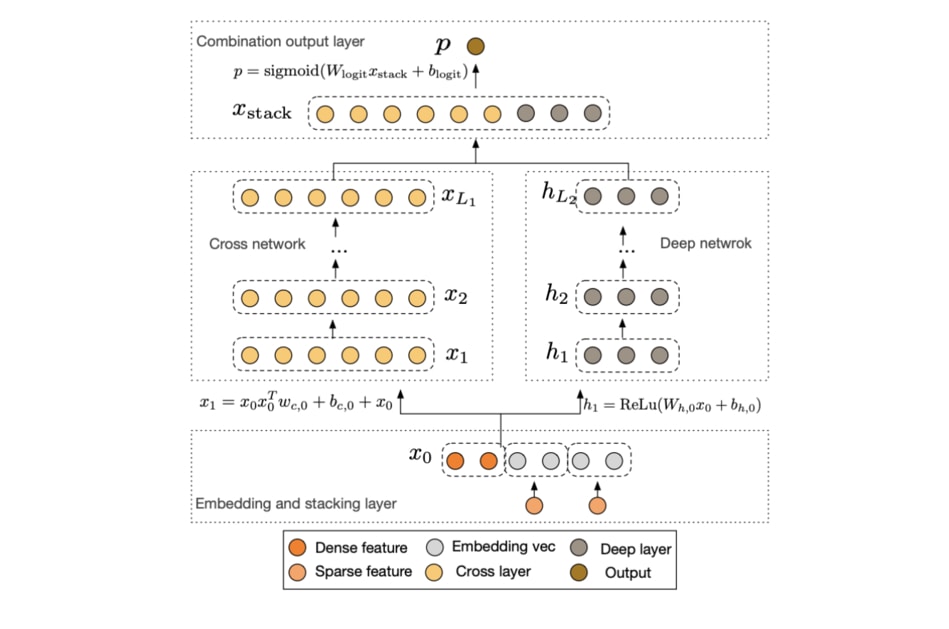
為了避免失焦,我在這篇文章裡頭不會討論過多技術細節。值得強調的是,這些模型是科技公司與數據神父們的嘔心瀝血之作,但從一般人的角度來看可以說是不知所云。所以我完全可以理解心理學與經濟學背景的祖博夫給這些技術下的評論:
成千上百份研究成果,無論是小成就還是大躍進,全都是那昂貴、複雜、晦澀難懂,而且獨一無二的二十一世紀「生產手段」。
─ 《監控資本主義時代》
這些生產工具為監控資本家帶來了巨大收益。在一篇 2017 年的微軟跟 Bing 搜尋相關的廣告論文開頭就寫著:「對搜尋引擎的收益來說,精準預估廣告的點擊率相當關鍵,就算只有將精準度提升 0.1%,也能增加數億美元的營收。」而他們最後顯示能夠用該論文提出的深度學習推薦模型提升 0.9% 的離線與線上精準度。真正的卓越成就。
有趣的是,實際打造谷歌這些「生產工具」的是他們大力推行的開源軟體庫 TensorFlow,也是無數機器學習工程師與資料科學家日夜使用的開發工具。所以現在大家一窩蜂在學的 TensorFlow 以及 PyTorch 可以說是生產工具的生產工具。
以下則是谷歌向開發者(developer)展示如何透過 TensorFlow 打造 Wide & Deep 模型的範例程式碼:
estimator = DNNLinearCombinedClassifier(
linear_feature_columns=my_wide_features,
dnn_feature_columns=my_deep_features,
dnn_hidden_units=[256, 64, 16],
...)
estimator.fit(...)
estimator.evaluate(...)
而因為這些開源軟體庫使用上十分便利,讓建構複雜神經網路模型像是在疊疊樂,業界內的工程師有時會自娛娛人:

更有趣的是,這些終日研讀技術文檔、開發的數據神父們有很大機率並不曉得自己在這樣的商業世界裡頭。
這我們等等還會提到。
一張圖說明監控資本主義與資料科學的聯姻¶
讀完上節,我相信你已經能夠直觀地將資料科學與監控資本主義的商業邏輯結合了。但我在撰寫此文時一直在想:「有沒有更淺白、更直觀的方式讓我把到目前為止談過的所有概念用一張圖呈現給你看呢?」
人類是視覺的動物。一個可行方案是透過知識圖譜(knowledge graph)的想法,將所有重要概念(監控資本主義、推薦系統等)視為一個個的節點(node),並將節點其中的關係視為邊(edge)來繪圖。你要不要猜一猜世上最大的公開知識圖譜在哪?沒錯,就是維基數據(Wikidata)。我們可以用類似 SQL 的語法即時查詢有提及《監控資本主義時代》作者肖莎娜・祖博夫(Shoshana Zuboff)名字的所有維基頁面:
SELECT DISTINCT (concat(?itemLabel, " (", ?typeLabel, ")") AS ?name) ?itemLabel ?typeLabel
WHERE {
{
SELECT ?item WHERE {
SERVICE wikibase:mwapi {
bd:serviceParam wikibase:endpoint "en.wikipedia.org";
wikibase:api "Generator";
mwapi:generator "search";
mwapi:gsrsearch "'Shoshana Zuboff'";
mwapi:gsrlimit "max".
?item wikibase:apiOutputItem mwapi:item .
}
} LIMIT 100
}
hint:Prior hint:runFirst "true".
?item wdt:P31|wdt:P279 ?type.
OPTIONAL { ?item wdt:P18 ?pic }
SERVICE wikibase:label { bd:serviceParam wikibase:language "zh-hant,[AUTO_LANGUAGE]". }
} LIMIT 100
如果你開啟圖片來源連結,就能找到一些跟監控資本主義直接相關的概念:
- 資本主義
- 極權主義
- 精靈寶可夢 GO(還記得谷歌無所不用其極地蒐集你的行為剩餘嗎?)
- 網路訪客追蹤
- Netflix 紀錄片:《智能社會:進退兩難》
- 圓形監獄
但這樣還不夠,我相信我們能做得更好。我用 Pyvis 打造了一個涵蓋監控資本主義以及資料科學相關概念的知識圖譜(或者說是我的心智圖)。在有了前面幾章的背景知識之後,你可以很輕鬆地解讀這個知識圖譜。要理解谷歌、臉書以及推特是怎麼賺進大把鈔票的,你只需找到下方圖譜中的使用者 A(你我)圖標,接著一路順著箭頭探索就能理解監控資本家是如何將你我的注意力、行為與時間轉換成監控收益的了,magic!
你也可以自由縮放、拖曳圖譜。
我希望你在瀏覽此圖譜時不只有一個 Aha moment:比方說突然對世界的運作方式有了更深的領悟、頓悟資料科學跟監控資本主義的商業邏輯是如何緊密耦合的。如果你富有好奇心,應該會花不少時間瀏覽上圖並從中獲得一些有趣的發現:
- 紅色代表與監控資本主義相關的概念;藍色是資料科學;黑色則是指相關人物
- 影子文本是監控資本家的最大生財資產。一般用戶無法存取甚至不知道其存在
- 資訊科技不等於監控資本主義。後者是一種商業邏輯而前者是後者的生產手段
- 監控資本圈並不只科技公司牽涉其中。監控資本以及政治力量都會型塑著市場
- 行為未來市場最終能控制社會,且終將影響一般用戶以及打造它的數據神父們
- 行為價值再投資循環是一個相對健康的商業邏輯,但仍有前面提過的科技上癮
- 除了推薦系統,自然語言處理與電腦視覺也是監控資本主義中的生產手段之一
沒有藏頭,不用找了。我只是有點強迫症。
再訪影子文本:「我們絕不會賣用戶個資!」¶
有了我們的知識圖譜以後,上一節最後提到的論述應該都顯得十分直觀。不過我還是建議想深入了解監控資本主義的讀者找時間咀嚼《監控資本主義時代》。你可以透過該書深入了解祖博夫筆下的大他者以及機器蜂巢所代表的意義。
底下我再針對第 2 點提到的影子文本給一個實例說明。
如果你沒有在科技公司工作的經驗,可能難以想像祖博夫筆下的影子文本長什麼樣子。但對業界的工程師來說,所謂的影子文本自然指的是那些只能在企業內部存取的一筆筆使用者行為日誌(user behavior log)。這些日誌詳細紀錄了每一個用戶跟某個系統 / 網站 / App 的每一次互動,是萃取行為剩餘最好的原物料。科技公司對其隱密的程度讓維基上甚至沒有一個好的說明頁面。下圖則是微軟亞洲研究院於 2018 年發布的一篇新聞推薦論文中出現的案例研究:

在這篇論文裡,研究員們描述了他們怎麼使用微軟自有的 Satori 知識圖譜以及我以前寫過的注意力機制(attention mechanism)來為一名隨機抽樣出來的用戶提供更好的新聞推薦(更多點擊 = 更好):「我們看到注意力神經網路能準確地抓到此用戶喜歡汽車以及政治的喜好。因為在知識圖譜裡頭,通用汽車跟特斯拉距離很近。」
這邊的重點是所有你現在在用的數位服務都在做這件事情:研發最能抓住你注意力的演算法,讓你繼續點擊、往下滑並待在他們的 Apps 上以提升你的互動與參與程度(engagement)。當然,科技公司會跟你說這些私密數據都匿名化了,沒有隱私議題。而且你當初在下載 App 時也已經同意了使用者條款,不是嗎?(儘管沒人會/能仔細看冗長的說明書)。

透過蒐集成千上萬名用戶的數位行為,科技公司累積了人類史上最龐大的知識量,以此打造能夠緊緊抓住每一位用戶注意力的演算法。這些演算法與推薦系統是將知識轉成權力的最佳體現:「我比你還懂你自己,而且我覺得這個東西很重要,所以你應該馬上點開查看」。《人類大未來》作者,歷史學家哈拉瑞就在書中預言未來會是少數菁英統治 AI,AI 再統治絕大多數的人類。應該也有人跟我一樣嗅到經典的反烏托邦作品《美麗新世界》的味道:這些菁英怎麼聽起來那麼像阿爾法 $\alpha $ ?
Github 聯合創立人普雷斯頓・沃納在接受彭博採訪時也有類似的言論:
未來人類可能只會剩下兩種類型的工作:一種是你寫程式告訴機器怎麼做,另外一種則是機器告訴你該做什麼。
─ Preston-Werner, Github 聯合創辦人
這就是影子文本的強大之處:累積巨大知識並能用來預測並引導底下用戶的未來行為。這是上對下的關係。
懂了這個以後,你就知道外界常常控訴「科技公司將用戶個資賣給第三方!」的這個議題根本打錯方向。一流的科技公司最珍視的就是自己的影子文本,谷歌跟臉書的發言人會跟你說:「我們怎麼可能出賣用戶個資!」而他們沒有說謊。使用者的數據隱私權不是沒了,而只是被科技公司「重新分配」了:雖然這些日誌都是關於你的行為,但我們不會讓你看到,而是自己用來預測你的未來行為。
2016 年劍橋分析醜聞的劍橋分析公司被英國追蹤記者卡洛爾・卡瓦拉德爾(Carole Cadwalladr)揭露其非法取得 5,000 萬筆臉書用戶數據並透過臉書的廣告推薦系統操控易被左右的英國選民,在選民沒意識到的情況下影響他們的脫歐抉擇。
該醜聞的其中一個引爆點正是因帕森設計學院的副教授大衛凱洛(David Carroll)問了該公司一個很簡單的問題:
我能看看你握有的我的個人數據嗎?
─ 大衛凱洛
而一直要到 2020 年,該公司宣告破產的 2 年多以後,大衛凱洛才終於透過媒體拿到了屬於他自己的那一份「影子文本」。大多數美國臉書用戶仍然沒親眼見過劍橋分析公司從臉書蒐集到的、那些屬於他們自己的私密數據。
個人化的極致:以個人為單位的平行世界與社會極化¶
在你想要去暴打你那位被祖博夫稱作「數據神父」的工程師或是資料科學家的朋友之前,讓我幫他/她辯解一下:他們自己可能也沒有意識到背後的商業邏輯。沒有貶低的意味,但在這年代利用最新生產手段(人工智慧、類神經網路)打造出能夠精準預測用戶行為的工程師們,其實就跟當年工廠生產線上的作業員沒差多少。我們都只是經濟體系裡服從資本的勞動力。

只不過當年工廠中的作業員信奉的神諭是「大量生產」,現在的工程師們信奉的是「個人化」的信條。
幾乎所有你能看到的推薦系統論文都會在其研究動機以及背景提到個人化的重要以及必要性。工程師與研究員也早已習慣將「用戶點擊」、「用戶按讚」、「用戶轉發分享」或是「用戶接受通知進入 App」視為數位世界的真理:「這對使用者好」。這些使用者行為要不是直接增加企業收益,就是透過提升使用者與系統的互動程度間接為企業賺錢。
這就是為何臉書 / IG 有時會貼心地提醒你:「有人在照片上標注你了喔!」卻沒有直接把該照片附在通知裡的原因。在通知裡頭附上照片對用戶很有實質幫助,卻可能讓用戶不需點進 App,進而造成企業的利益損失。

個人化當然有對用戶的好處及其必要性。不過我們也絕不能忽略極端的個人化會導致《智能社會》裡頭看到的科技上癮。無上限的個人化也會導致我們在 2016 年劍橋醜聞已經看過的社會極化:每個人都只看到自己想看到的。現在的監控資本家們就像是發給全世界每一位用戶一個免費的意若思鏡,其大小就是你手中那只有幾寸的螢幕畫面,投射出所有你內心最渴望卻也最虛幻的慾望,而此單面鏡後不斷有人想著怎麼讓你的大腦再分泌一點多巴胺。
到頭來疑惑的人們會在社群媒體上丟出疑問,質疑跟自己想法不一樣的「他們」到底在想什麼:
為什麼那些人這麼地蠢?你看看我每天看到的臉書與推特動態、谷歌搜尋結果以及微軟新聞內容,難道這些資訊他們都沒看到嗎?
─ 身處數位時代的你我會有的日常疑問
然後這些疑問還只有願意跟我們互動的同溫層會收得到,多虧了個人化演算法。
人們都會趨吉避凶,本能地排斥不同觀點並喜歡與符合自己觀點的想法/群體互動。這種人類天性被「最大化用戶互動程度以獲利」的社群媒體利用,直接導致了震驚全球的 2021 年 1 月美國國會示威騷亂:美國總統川普支持者強行闖入象徵該國民主的國會大廈,試圖推翻 2020 美國總統大選結果。
用監控資本主義的框架思考,就能理解正是因為社群媒體的商業本質使得「川普將會帶領軍隊推翻選舉結果!」等陰謀論以及極右思想能夠以低廉的成本廣泛散播給數以百萬計的用戶,塑造他們的平行宇宙,最終導致這場悲劇。BBC 指出早在騷動的前 65 天就已經能看到陰謀論在臉書上流傳的跡象。以下則是 BBC 新聞攝影師在前線的紀錄:
監控資本主義給出的答案很殘酷。沒錯,那些跟你持不同想法的人們每天會看到並互動的個人化內容都跟你看到的不一樣。
而在美國國會大廈遭到衝擊之後,推特宣佈已經關閉了超過 7 萬個與陰謀論有關的賬戶,最後則是美國前總統川普本人的帳號。有些人將其視為左派的勝利,但如果你超越政治光譜,把思考問題的高度放到跟德國總理梅克爾一樣的位置,就知道真正需要被大眾討論跟解決的問題應該是:
為何社群媒體可以為了營利在一開始放縱這些陰謀論流竄?為何這些科技巨頭後來可以自己選擇下架美國總統?社群媒體自我審查的基準在哪裡?為何他們有那麼大的權力?民主與人權在哪裡?
根據美國現行法律《通信規範法案》第 230 條,包括推特和臉書在內的社交媒體公司不會因用戶發帖內容而被追責,同時也可以刪除合法但會引起反感的內容。這是俗稱的「避風港條款」。
但我們需要承認新型態的資本主義發展速度太快,現行的法律已經跟不上腳步了。避風港條款是在 21 世紀初期通過,而監控資本主義那時也才剛剛萌芽。時至今日,如果今天推特 CEO 可以凌駕全世界所有法律,關閉有 8,800 萬追蹤者的美國總統帳號,同時宣稱該企業會「自主控管」以及擁有「言論自由」,還有什麼能限制他們呢?
這些問題值得我們認真思考。

要改善我們的數位社會需要每個人的合作,近年工程師們也正努力地想辦法改善推薦系統的社會面向。幫助用戶脫離個人化資訊的舒適層(comfort zone)、增加推薦內容的多樣性(diversity)以提升用戶滿意度。「誰說我們只想著 CTR!」
雖然老實說是因為不少企業發現要保證用戶能持續地使用自家 App(另個企業指標:長期留存率!)得考慮 CTR 以外的事情,頂尖的推薦系統會議如 RecSys 在 2020 年都出現了更多試圖解決推薦系統對社會帶來的負面影響的研究。RecSys 2020 Keynotes 的主題就分別為 「4 個社群媒體使我們容易被操控的理由」以及「搜尋以及推薦系統的偏差」。
其他我印象比較深刻的近期研究(以下為我自己的翻譯)有:
以後或許會撰文深入討論相關研究,但現在先讓我們就此打住,總結一下一路上聊了些什麼。
最終章 21 世紀第 3 個十年的認知革命¶
呼!一路走來,我相信你對自己身處的數位世界已經有更深一層的理解了。你已經知曉了監控資本主義扭曲的過去以及瘋狂的現在,是時候回顧一下我們在開始這趟驚悚旅程之前那段關於未來的訊息了:
監控資本主義在 21 世紀主導資料科學以及 AI 的發展方向,並持續往大多數人不樂見的方向邁進。只有在大眾能夠認知到並理解其商業邏輯,我們才能透過集體意識去改善每個人的數位未來。
─ 本文主旨
你現在能夠理解這段訊息了。
監控資本主義的火車能這樣不受控制地在我們的數位世界裡橫衝直撞,要歸功於你我長期對監控科技發展的「無知」以及我們對「免費」的錯誤理解。但現在你已經「知曉」了監控科技的實際存在,也能明白一直以來的「免費使用」交易的是你在數位時代越來越寶貴的「注意力」。
認知到這些事實是任何偉大改變的開始。

在這篇文章裡,我近乎囉唆地以各種視角與實例為你重現由(1)監控資本主義的商業邏輯以及(2)強大的資訊科技共同打造的數位世界,幫你從頭構築出一個能夠合理解釋這瘋狂年代的世界觀。事到如今我們已經無法成為拒絕使用數位服務的盧德主義者,但我們能做的是重新找回自我。
資訊的豐富意味著它消耗著資訊接受人的注意力導致其變得稀缺。因此資訊之豐富創造了注意力之貧窮。資訊接受人需要在過剩的資訊來源中有效地分配其注意力。
─ 赫伯特・亞歷山大・西蒙, 人工智慧之父
認知到注意力的珍貴以及數位服務對其之無限的渴望後,你就能開始做些改變。
你應該時時刻刻問自己:
- 「真的有需要一直往下滑臉書、推特或是 IG 嗎?沒有其他更重要的任務嗎?」
- 「App 通知來了,真的有需要現在、立刻、馬上打開查看嗎?」
- 「能不能改掉一看到手機螢幕亮就反射性去看是什麼通知的壞習慣?」
- 「當下這個時間點除了消耗數位內容,對我來說最重要的事情是什麼?」
- 「這篇貼文讓我情緒激動想分享轉貼留言,但它的內容可信嗎?」
- 「App 推薦的內容讓我很想點進去看,但那是我人生最高順位的事情嗎?」
- 「我真的需要邊吃飯邊聽 Podcast ,不給大腦自主思考的時間嗎?」
- 「我一天有幾分鐘是真的能夠靜下心思考重要問題而不是無腦觀看影片?」
沒人會在意你往自己腦中塞了什麼,你的思想與行動才是證明自己最大價值的事物。你可以試試數位內容的間歇性斷食,拿掉你的數位奶嘴,不要再讓那些無時無刻吵著「你的朋友標注了你!」「你的訂閱者出了新影片!」這種為了爭奪你寶貴注意力的「便利通知」而疏忽了你人生中最重要的事情了。
如果你也想要為世界創造些價值,就盡可能地專注吧!我們不該整天都把寶貴的注意力以及大腦資源拿來消耗「他們」要我們馬上查看的數位內容。從今天開始為自己決定優先順序吧。
我也希望你能幫忙把這些知識傳達給對你來說重要的人知道。當越來越多人意識到真正重要的事情並改變行為,就能創造一股集體意識讓企業們做真正對我們有幫助的事情。監控資本主義的商業邏輯讓我們每個人有不同的現實(reality)進而各個擊破。透過這篇文章我希望能跟所有人一起建立一致的現實,並透過這股力量改善我們以及下一世代的數位未來。

除了重視自己的注意力並將其視為最重要的資產,所有人都應該開始向數位霸權宣示在這個數位時代裡,我們的新人權也包含了自己的數據權。行政院數位政委唐鳳也建議我們應該要把自己的數據權當作基本人權。
如果你是其中一名數據神父,別忘了能力越強,責任越大。我們得開始理解用戶的意圖(intention)並幫助他們解決真正的問題,而不是整天抓著他們的注意力(attention)。《個資風暴》裡頭我們看到數據分析人員如何因為看到廣告投放的實際 KPI 成長而忘了背後都是一名名真實活在世上的人類。就像在《真確》裡瑞典公衛教授漢斯・羅斯林跟我們說的:
我要你看到統計數據背後的個別故事,也要你看到個別故事背後的統計數據。不靠數據無法了解世界,但光靠數據也無法了解世界。
─ 漢斯・羅斯林,《真確》
機器學習工程師以及資料科學家並不只是人型的「最佳化機器」。數據神父們得要承認人類的注意力、時間都是有限的,認識到人類本身的認知極限,並把這些因素考量進去決定演算法應該要最佳化什麼,而不只是去最佳化 CTR。
如果你是企業家或是正打算創業,多花點心思打造更符合「人性」的數位服務吧!這雖然不是一件容易的事情,但只要你成功了,我想全人類都會支持你的產品。
雖然在這篇我延續《監控資本主義時代》的思路抨擊谷歌、臉書以及推特等科技公司,但他們的服務也實際為社會做了不少貢獻。只是這樣還不夠,我希望能喚起大眾的集體認知,讓這些我們熱愛的數位服務往真正對人類未來發展有助益的方向邁進。如果他們宣稱拋棄自我是科技進步與數位化的必要代價,我想就是我們該為自己發聲的時候了。
讓我們修正監控資本主義創造的數位現實,建立以人為本並符合人體工學的數位未來。
跟資料科學相關的最新文章直接送到家。 只要加入訂閱名單,當新文章出爐時, 你將能馬上收到通知