不同於上週的文摘 Vol.2 產品理解以及 DS / DE 之路,這週的選文比較技術以及實作導向。本週將導讀 3 篇使用 Python 以及 Pandas 的文章,並鼓勵讀者實際動手學習。我們也會看到如何使用 Docker 來讓資料科學變得更簡單,並提供一個有趣的貓咪圖片辨識 App 給有興趣的讀者參考。最後,讓我們分別看看哈佛商業評論以及美國前首席資料科學家 DJ Patil 談談如何讓資料科學在企業內普及,以及數據時代我們面臨的各種道德議題。
本週閱讀清單¶
- Pandas、Python
- Docker
- 數據時代的反思


提供常見的 SQL 查詢以及其對應的 Pandas 寫法。一個有效率的資料科學家通常需要 SQL 及 pandas 兼具。雖然這篇一開始的目標讀者是那些已經熟悉 SQL 並打算使用 Pandas 的讀者,我認為熟悉 Pandas 但還不了解 SQL 的同學們也能從這篇學到點東西。
這篇適合至少懂 Python 或是 SQL 並想學習另外一個語言的讀者。如果你想要深入了解 SQL 或是其與 Python 之間的差異,你可以看看我之前寫的為何資料科學家需要學習 SQL。
這篇 Hackernon 文章則簡單介紹 Functional Programming 在 Python 可以如何被實作,函式(function)是怎麼被視為 Python 的第一公民以及我們能如何活用函式如 Map、Filter 函式。
如果你剛起步,想要有效率地學習 Python 的話,我建議可以從 List comprehension 開始學起。
一個簡單的例子是假設我們想從一個 List 中取得大於 50 的數字:
l = [5, -3, 100, 70, 2]
larger_than_50 = [e for e in l if e > 50]
print(larger_than_50)
文章的後半段則透過 The Zen of Python (Python 的禪學)來說明為何使用 List comprehension 會比使用傳統 Functional Programming 中的 Map、Filter 函式來得簡單。
Python 有一個著名的彩蛋,你可以利用 import this 來顯示 The Zen of Python,它提供使用 Python 的人一個簡單的開發準則,具體如下:
import this

很簡單地說明常見的 Docker 術語以及使用 Docker 可以為資料科學家帶來的好處:
- 節省建置開發 / 分析環境所需的時間
- 增加可重現性(Reproducibility)
- 抽象化作業系統(OS)的概念,再也沒有只能在 Mac 跑而不能在 Windows 跑的問題
這篇提供非常初級的指令來開始在本機環境使用 Docker,可以嘗試看看。
在 Smartnews 我則是使用 Amazon Elastic Container Service 來快速部署一些資料科學家們常會用到的分析工具,如大家的好朋友 Jupyter Hub、Airbnb 開發的 BI 工具 Superset。之後有機會會另外撰文分享經驗。
Try It Yourself¶
Docker 讓我們可以快速重現其他人的分析環境或者是有趣的 application。如果你想馬上感受 Docker 的威力,可以看看我之前利用 Tensorflow 以及 Flask 實作的一個貓咪圖片辨識的 Github repo(feat. CNC):
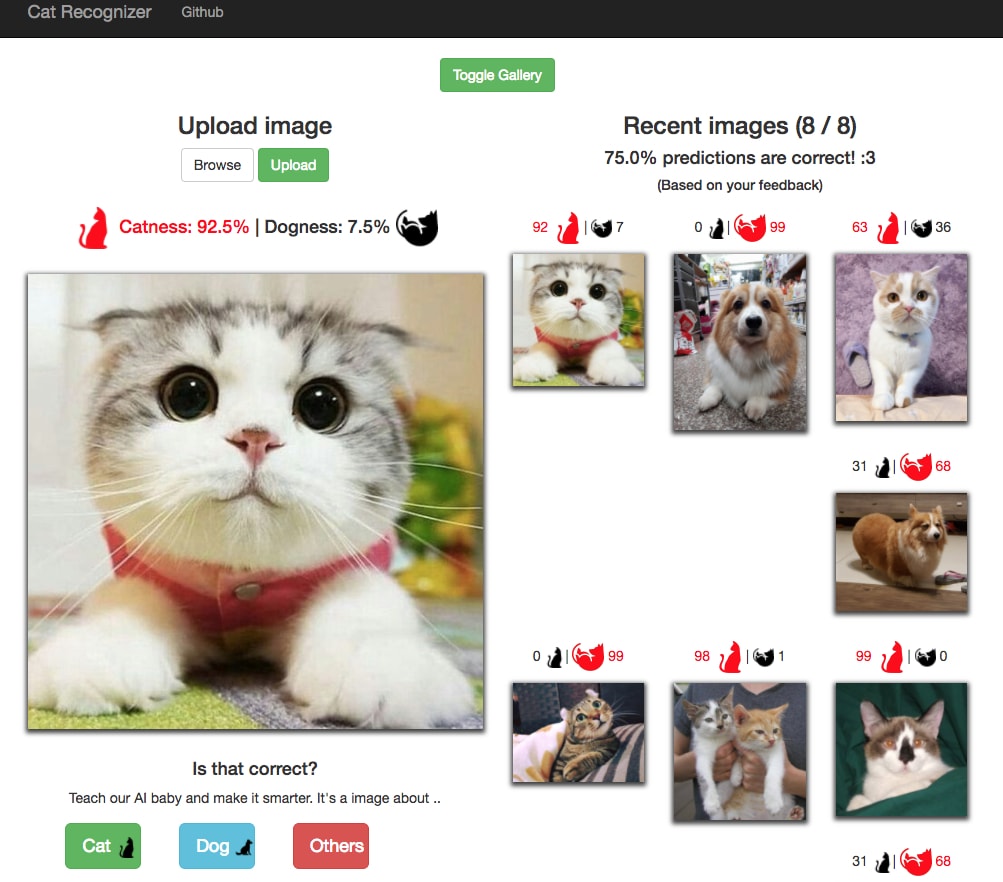
雖然 Github repo 上也有教學指南,想要最快速地在你的電腦上使用這個 App 的話,下載 Docker 並開啟 Daemon 後,使用命令列輸入以下指令:
docker pull leemeng/cat
docker run -it -p 2468:5000 leemeng/cat
接著在瀏覽器輸入 localhost:2468 應該就能開始使用了。如果你想多了解點 Docker,可以參考我寫的給資料科學家的 Docker 指南:3 種活用 Docker 的方式(上)。
不過現在讓我們繼續看剩下的 2 篇好文章:)

哈佛商業評論(Harvard Business Review, HBR)在這篇文章裏頭敘述為何不只是針對資料科學家,提升所有人的「資料素養」對一個企業來說是一件非常重要的事情。
最明顯的優點是可以讓數據團隊專注在:
- 解決更高層次的企業問題
- 建立分析工具以加速所有部門的數據分析
而不是處理每個部門的「資料瑣事」。
這個議題並非只跟企業的管理階層相關。對一個資料科學家來說,想辦法利用資料工程(Data Engineering)等方式來自動化如「建立簡單儀表板」的工作,並教導各個部門實際的使用方式,可以讓你一勞永逸,避免永遠在處理非常瑣碎的「資料瑣事」,專著在更大的目標。
!quote -你不會因為自己不是會計師就不遵守專案預算;你也不會因為不是資料科學家就不提升資料素養。

生活在數據驅動時代的我們或許都能感受到世界變化的快速。
美國前首席資料科學家 DJ Patil 認為不管是資料科學、機器學習還是人工智慧領域,「道德倫理」以及「安全隱私」議題都應該越來越被重視。
電腦科學(Computer Science)時代最著名的安全議題非 SQL 注入(SQL Injection)莫屬了。如同這個議題,在數據驅動時代,我們也會面臨類似道德以及數據保護的議題,像是人工智慧模型產生具有偏見的預測、以及最近的 GDPR 等等。
在教育方面,DJ Patil 認為我們應該教育下一代在數據處理時,應該遵守的準則並將其被納入課綱;以數據驅動的公司則需要將這些想法都納入企業文化,在招聘資料科學家的時候,除了考慮他 / 她的分析能力以外,也要評估道德倫理的部分。
身為一個資料科學家,除了技術層面的提升,也應該稍微了解這些議題。
We can build a future we want to live in, or we can build a nightmare. The choice is up to us.
結語¶
Pandas、SQL、Docker、資料素養的培養以及數據時代的道德倫理問題等等,這週我們也看了不少資料科學相關的文章,希望你有從這篇文章裡頭學到點東西。
雖然因為篇幅關係沒辦法把所有實際的 Python 指令列在這邊,我希望透過摘要的方式能讓沒時間的你也能學習、初步地了解資料科學並進一步發現自己有興趣的地方鑽研。
有時間的話我推薦實際閱讀這些文章(當然也可以閱讀其他你自己收藏的文章,也歡迎分享),也可以試試看我寫的 Cat Recognizer 並留言跟我說說你的想法。
之後一樣會定期更新,希望收到第一手消息的話可以點擊下面的訂閱。另外如果你有其他會對這篇文章有興趣的朋友,也請幫忙分享給他 / 她:)
That's it for this week, stay tuned and happy data science!
跟資料科學相關的最新文章直接送到家。 只要加入訂閱名單,當新文章出爐時, 你將能馬上收到通知