今天我們來聊聊如何將 Docker 應用在資料科學領域裡頭吧!
全文共分上下 2 篇。在這篇裡頭,我們將透過一些簡單的比喻來直觀地理解何謂 Docker,並讓你能在閱讀本文後馬上利用 Docker 來加速你的開發效率;在下篇的內容當中,我則會分享一個資料科學家(Data Scientist:DS)為了解決一些數據問題而時常碰到的 3 種 Docker 使用方式。
不管是哪一篇,我們都不會深入探討 Docker 本身是以什麼技術被實現的。反之,我們將會以 DS 的角度,專注在「應用」層面:如何把 Docker 實際應用在資料科學以及資料工程領域裡頭。
這系列文章適合 2 種讀者:
- 對 Docker 完全沒有概念,但想讓自己的 Workflow 更有效率的資料科學家
- 熟悉 Docker,但好奇其在資料科學領域如何被應用的工程師
讓我們開始吧!
雲端運算 & Docker¶
在解釋何謂 Docker 之前,讓我把你已經非常熟悉的雲端運算(Cloud Computing)老朋友叫出來。
Amazon Web Service(AWS)、Google 雲端平台(GCP) 以及 Microsoft Azure 大概是大家最耳熟能詳的幾家雲端計算 / 服務平台了。隨著時代的演進,這些平台提供越來越多樣的機器學習 API,讓開發人員不需做複雜的開發,透過一個 HTTP 要求就能直接使用各種酷炫的服務,比方說:
- Amazon Lex 讓你使用 Amazon Alexa 的深度學習技術建立聊天機器人
- Google Cloud Vision API 讓你快速建立一個圖像辨識服務
- Azure Content Moderate API 讓你自動審核網路上的圖片以及文字
儘管如此,很多時候只使用這些現成的 API 並不能滿足我們這些 DS 以及企業的野心。

雖然我們現在不會細談,但如果你再看一次上面的 3 個工作的話,會發現裡頭可不只包含資料科學(Data Science)。除了建置儀表板以及設計 ML 演算法以外,這裡頭還包含了不少軟體工程、資料工程甚至 DevOps 成分。當然資料工程師(Data Engineer)很樂意幫助你,但如果你想要快速地自己兜出一些方法呢?你該用什麼工具?

你可能覺得一個 DS 要在各種 deadlines 內完成以上所有的事情是不可能的。不過後面我們會慢慢發現,活用 Docker 能讓這些工作變得簡單許多。
接著就讓我們以 DS 的角度了解 Docker 到底是什麼技術。我相信閱讀接下來的文章,對你之後開發效率的提升是一個非常好的投資。
Docker:可愛的大鯨魚¶
首先看看以下這張 Docker 示意圖:
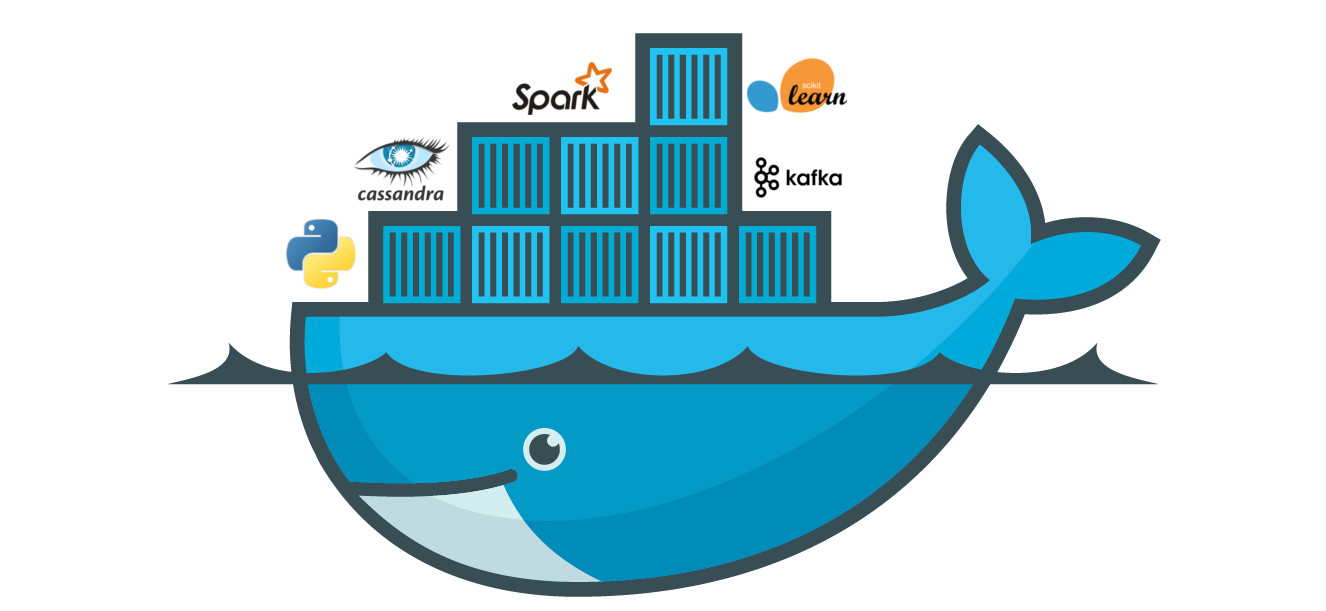
有什麼感覺嗎?注意到上圖包含了 3 個要素:
- 海洋
- 鯨魚
- 貨櫃
現在讓我們發揮點想像力。
如果你把雲端運算的平台想像成一個充滿運算資源的大海的話,Docker 就是如圖中在裡頭悠遊的大鯨魚。這隻鯨魚將上述所有 DS 想要做的數據處理工作、執行的 App,一個個封裝成彼此獨立的貨櫃,並載著它們在這大海上運行。
Docker 提供的抽象化讓我們能輕鬆地運行任何想使用的資料科學工具、軟體而不需花費過多時間在建置底層環境。
我知道你可能還是沒什麼感覺,讓我們看下去。
鯨魚背上的貨櫃:Docker 容器¶
實際上這一個個假想的貨櫃就代表著 Docker 術語裡頭的容器(Container)。
「容器」顧名思義,是一個「容納」了某些東西的「器具」。
一般而言,一個容器裡通常會包含了一個完整的 App。這邊的 App 不是手機上的 App,而是指廣義的應用程式(Application)。
DS 常用的 App 可以是:
- 一個包含 TensorFlow 函式庫的 Jupyter Notebook 伺服器
- 一個 ML 產品,如透過已訓練的模型來判斷圖片裡頭有沒有貓咪的 Flask App
- 一個 SQL 查詢以及資料視覺化的工具,如 Superset
- 一個簡單的 Python Script,針對輸入的大量數據做處理
要從頭建構這些 App 的環境不是不可能,但除了基本的 pip install 以外你還需要花不少工夫;更令人困擾的是,很多時候你在 Mac、Windows 上安裝環境的步驟,到了雲端上的 Linux 機器上就完全行不通了。
如果這時候有人先幫我們把一個在哪邊都能跑的 App 環境建好,我們不是就能馬上開始使用各種分析工具,進行各種有趣的分析,而不用煩惱底層如不同 OS 的差異了嗎?
Docker 的容器就是這樣的一個概念,幫你事先將一個 App 所需要的所有環境,包含作業系統都「容納」在一起。
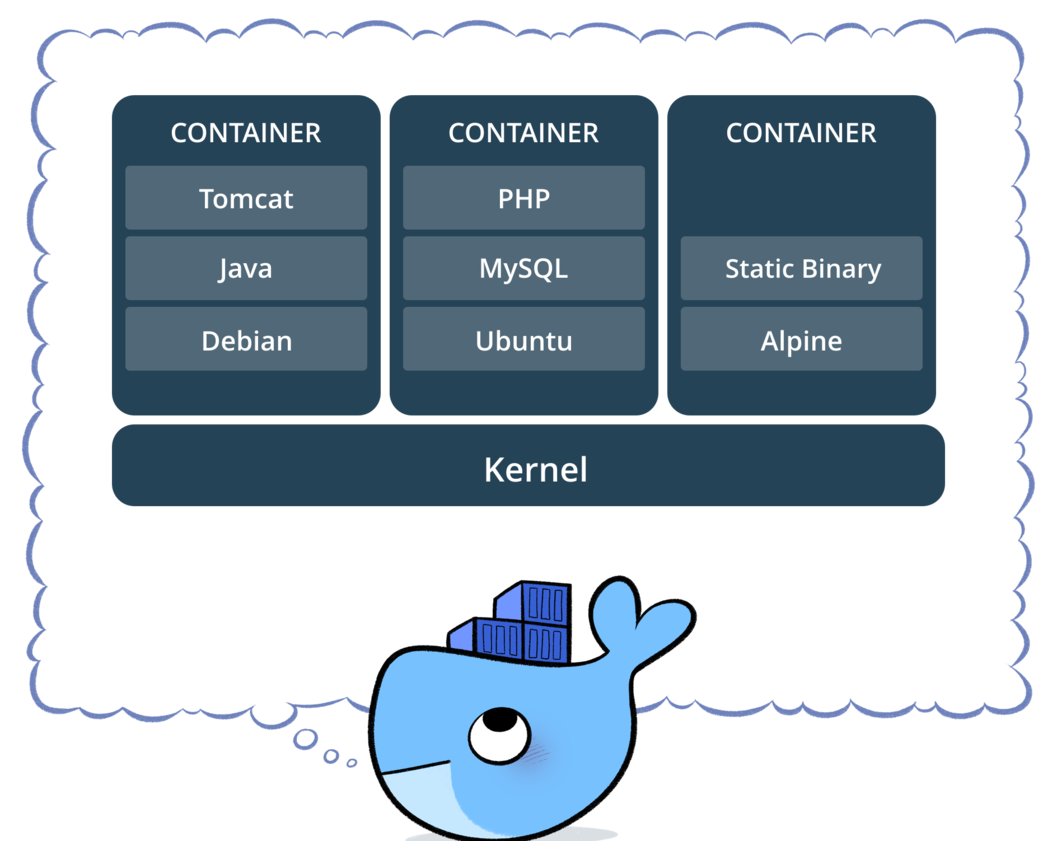
容器裡頭不只包含 App 自己本身的程式碼,也涵蓋了所有能讓這個 App 順利執行的必要環境:
- App 需要的各種 Python 函式庫,如特定版本的 TensorFlow、Pandas 及 Jupyter Notebook
- MySQL、MongoDB 等 App 會用到的資料庫
- App 會用到的各種 metadata、資料集
- 各種 OS 限定的驅動程式(drivers)、依賴函式庫
- (把所有你想得到的東西填進來)
包羅萬象。
因此只要我們能利用 Docker 把一個 App 需要執行的環境全部包在一個容器裡頭,我們就能在任何有 Docker 的地方啟動並運行該容器。不再需要每次重新建置環境,也不用考慮不同機器上的安裝問題。
而這正是 Docker 最強大的地方:
Docker - Build, Ship, and Run Any App, Anywhere
因為連 OS 都被包起來了,實際上每個容器(container)的執行環境都是自給自足的(self-contained)。
你可以把它想像成非常輕量的虛擬機器,其執行結果不會因為啟動該容器的「計算環境」不同而受到影響,在任何地方(Anywhere)都能順利被執行,且執行的結果都是一樣的。
以我們前面的比喻來說的話,每個貨櫃(容器 / App)都是我們想要 Docker 幫我們運送(執行)的東西,而不管 Docker 這隻鯨魚(或大船)現在在哪個海洋(計算環境)裡頭,它都能使命必達。

Docker 幫我們抽象化在任何 OS 上建置環境的工作。只要給 Docker 一個容器,它就能在任何地方啟動該容器以供你使用。
現在你對 Docker 以及容器概念有個高層次的理解了,讓我們來看看這些 Docker 容器實際上是怎麼來的吧!
貨櫃(Docker 容器)從哪來¶
在了解 Docker 這隻大鯨魚能幫我們運行任意的容器 / App 以後,你腦中浮現的第一個問題應該是:
- 這些容器(貨櫃)最初是怎麼被產生的?
非常好的一個問題。
事實上,要產生一個新的 Docker 容器,Docker 需要一份「環境安裝步驟書」來讓它幫我們自動地建置容器內的環境,比方說使用什麼 OS,用什麼版本的 TensorFlow 等等。這份步驟書在 Docker 的世界裡被稱作 Dockerfile。
舉個例子,以下是 Tensorflow 官方釋出的一個 Dockerfile(截錄重要部分):
FROM ubuntu:16.04
...
RUN pip --no-cache-dir install \
ipykernel \
jupyter \
numpy \
pandas \
sklearn \
&& \
python -m ipykernel.kernelspec
...
# Install TensorFlow CPU version from central repo
RUN pip --no-cache-dir install \
http://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.0.0-cp27-none-linux_x86_64.whl
...
CMD ["/run_jupyter.sh", "--allow-root"]
除了 RUN、CMD 等 Docker 專屬的關鍵字以後,你會發現這份 Dockfile 裡頭的指令其實跟你平常在本地開發時也會使用的指令如 pip install 沒有相差太多。差別在於透過第一行的 FROM ubuntu:16.04 指令,我們要求 Docker 在這個容器裡頭建置一個 Ubuntu OS 後,在其之上安裝這些函式庫。
追求規模性:Docker 映像檔的誕生¶
聽完以上的解釋,你可能會覺得在我們每次要啟動一個新的容器的時候,Docker 就得拿出 Dockerfile,一步步建置該容器的環境。
這樣的實作也不是不行,但很沒有效率。為什麼?

其中一個考量是可擴展性(Scalability)。
有時你會想要用同一份 Dockerfile 在短時間內迅速地產生好幾個一模一樣的容器(s):
- 用多個相同的機器學習模型,同時對大量的新數據做批次預測
- 使用多個相同的 Python Script 來處理大量數據
這時候與其在每次要啟動新的容器時才拿出 Dockerfile 建置環境,Docker 可以事先用這個 Dockerfile 把建置環境所需的步驟先做好一遍,然後把該環境「拍張照」,存成一個 Docker 映像檔(image)後等待之後的使用。
等你決定要開始使用容器的時候,因為我們已經有一個環境的快照(Snapshot),Docker 就能利用該映像檔,快速地啟動 1 個(或 100 個)相同的容器給你。
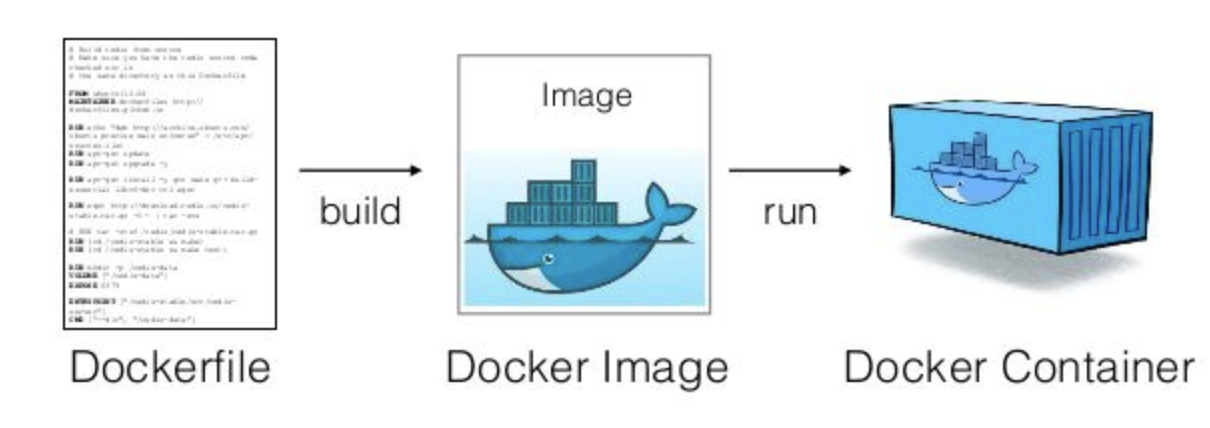
到了這邊,我們已經了解 Docker 最基本也是最重要的概念:
Docker 利用 Dockerfile 預先建置好一個 Docker 映像檔。在使用者想要使用容器的時候,以該映像檔為基礎,運行一個對應的 Docker 容器
坐而言不如起而行。
在掌握了這些概念以後,我相信你也迫不及待地想要開始使用 Docker 了,接下來就讓我們實際操作 Docker 來體會一下它的威力。
Docker 映像檔:法式千層酥¶
不管是 Windows 或是 Mac 用戶,你都可以很輕鬆地在官方網站下載 Docker 並安裝。

下載完以後啟動 Docker,大鯨魚就會在你的筆電上開始閒晃,等待你的指示。一般而言,我們會在 terminal 使用各種 docker 指令來跟大鯨魚溝通。
當 Docker 就緒以後,依照我們前面的所學,你會需要一個 Dockerfile 或是 Docker 映像檔來產生一個 Docker 容器。就像 Github 是一個被大家拿來分享程式碼的地方,Dockerhub 則被用來分享 Dockerfile 以及 Docker 映像檔。
假設我們現在要開始一個新的 TensorFlow 專案,並且想透過 Jupyter Notebook 進行開發,最省力的方式就是從 Dockerhub 下載一個 TensorFlow 官方幫我們弄好的 Docker 映像檔。
讓我們打開一個 terminal 並輸入 docker pull 指令:
docker pull tensorflow/tensorflow
第 1 個 tensorflow 代表 Tensorflow 的官方 Dockerhub repository,就跟 Github repository 的概念相同;第 2 個則是容器名稱。
你會看到當 Docker 在下載映像檔的時候,同時也在建置環境,而其環境會分成一層一層(Layer)的:
$ docker pull tensorflow/tensorflow
Using default tag: latest
latest: Pulling from tensorflow/tensorflow
3b37166ec614: Already exists
ba077e1ddb3a: Already exists
34c83d2bc656: Already exists
84b69b6e4743: Already exists
0f72e97e1f61: Already exists
6086c6484ab2: Pull complete
25817b9e5842: Pull complete
5252e5633f1c: Pull complete
8de57ae4ad7d: Pull complete
4b7717108c3b: Pull complete
b65e9e47e80a: Pull complete
006d31e013ea: Pull complete
700521cc53f3: Pull complete
Digest: sha256:f45d87bd473bf999241afe444748a2d3a9be24f8d736a808277b4f3e32159566
Status: Downloaded newer image for tensorflow/tensorflow:latest
我們不會細談 Docker 實作細節,但你可以想像 Docker 映像檔是一個法式千層酥(Mille Feuille)。
這時候的 Docker 是一名蛋糕師傅,利用 Dockerfile 作為食譜,逐行執行裡頭的指令以建立一層層的環境。每做出一層新的環境,就把它加在目前所有環境的上面,最後成為一個 Docker 映像檔。
這樣做有 2 個好處:
- 當你對 Dockerfile 做變動的時候,Docker 可以只針對被改變的那一層環境做修改,而不用重建每一層,減少建置環境所需要的時間
- 有利用到一樣環境的不同映像檔可以分享部分結果(如上面的
Already exists)

依照你的網路速度,下載映像檔所需的時間可能有所不同。
在下載完成以後,輸入 docker images 指令可以顯示所有目前本地端擁有的 Docker 映像檔:
$ docker images tensorflow/tensorflow
REPOSITORY TAG IMAGE ID CREATED SIZE
tensorflow/tensorflow latest 76fb62c3cb89 2 weeks ago 1.23GB
這邊因為我的環境裡已經有一大堆的映像檔,我在 docker images 後面加入額外的篩選器來告訴 Docker 只顯示 tensorflow repository 裡頭的 tensorflow 容器。
有了映像檔以後,最令人期待的時刻終於來臨了!
我們現在要呼叫 Docker 幫我們從這個映像檔產生並執行(run)一個新的 Docker 容器:
docker run -it -p 1234:8888 tensorflow/tensorflow
短短一行指令,包含了 3 個你不可不知的重要概念:
- 利用
docker run來告訴 Docker 我們要利用tensorflow/tensorflow映像檔來運行一個容器。實際上 Docker 容器就是在 Docker 映像檔的環境之上再加 1 層可執行的環境供你使用(貫徹千層酥的理念) - 利用
-it參數來告訴 Docker 我們同時要建立一個互動式的 TTY 連線,讓容器內的結果直接顯示在我們的 terminal 裡頭,彷彿我們在本地環境下執行該 App 一樣。我們之後還可以直接在 terminal 使用 Ctrl + C 或 Command + C 來終止容器 - 利用
-p 1234:8888告訴 Docker 我們將會透過本地端的1234port 來連到容器裡頭的8888port
你可以透過
docker run --help
來查看所有 docker run 可以使用的參數。
另外,一個 DS 應該都知道,8888 是 Jupyter Notebook 預設的 port。因此我們的企圖就跟司馬昭之心一樣,打算透過本地端的 1234 port 連到在容器裡頭跑的 Jupyter Notebook。
現在打開你的瀏覽器並輸入 localhost:1234,應該就能連到容器內部的 Jupyter Notebook 伺服器:
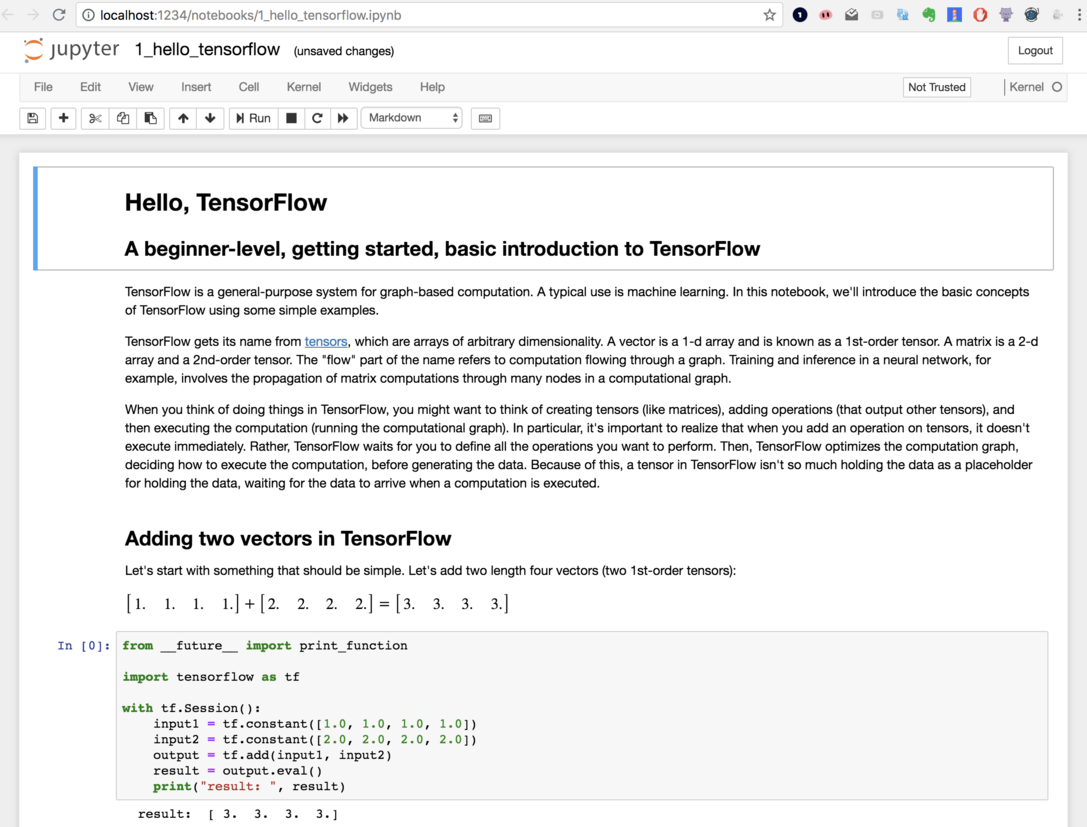
對你沒看錯,你已經用 Docker 建置了一個完整的資料科學環境,裡頭有 TensorFlow 以及 Jupyter Notebook。
而你只需要 2 個指令:
docker pull tensorflow/tensorflow
docker run -it -p 1234:8888 tensorflow/tensorflow
建置環境什麼的交給 Docker 吧,你已經能馬上開始實作機器學習模型了。
有些 DS 可能會覺得他的 Anaconda 或者是 pip 功能爐火純青,不需要用到 Docker 也能自己在本地建出這樣的環境。其實沒錯,如果你只是開發個人專案,說真的不學 Docker 也沒關係(喂!)
但就如我們在下篇會看到的,當你在開發企業等級的數據處理工作、機器學習模型的時候,你可不能永遠躲在你的本地環境裡頭。當你習慣於在不透過 Docker 的情況下在本機建置環境,等到要在各種雲端平台上的機器重現你的結果的時候,你就會發現不妙了。
利用 Docker 分享你的成果¶
為了加強你使用 Docker 的動機,讓我再給個例子。
有持續關注我文章的讀者會發現,我在資料科學文摘 Vol.3 Pandas、Docker 以及數據時代的反思裡頭有提到,Docker 除了讓我們免除建置環境的痛苦以外,也能讓我們與他人簡單地分享開發結果。
Cat Recognizer 是我用 TensorFlow 以及 Flask 實作的一個非常 naive 的貓咪辨識 App。
如同我們前面所說的,我事先將所有此 App 需要的環境用一個 Dockerfile 定義、全部包在一個 Docker 映像檔後分享在 Docker Hub 上面。
任何想要使用此 App 的人,只需要利用 Docker 輸入兩行指令:
docker pull leemeng/cat
docker run -it -p 2468:5000 leemeng/cat
接著他們就能在瀏覽器輸入 localhost:2468 來看到我的 App:
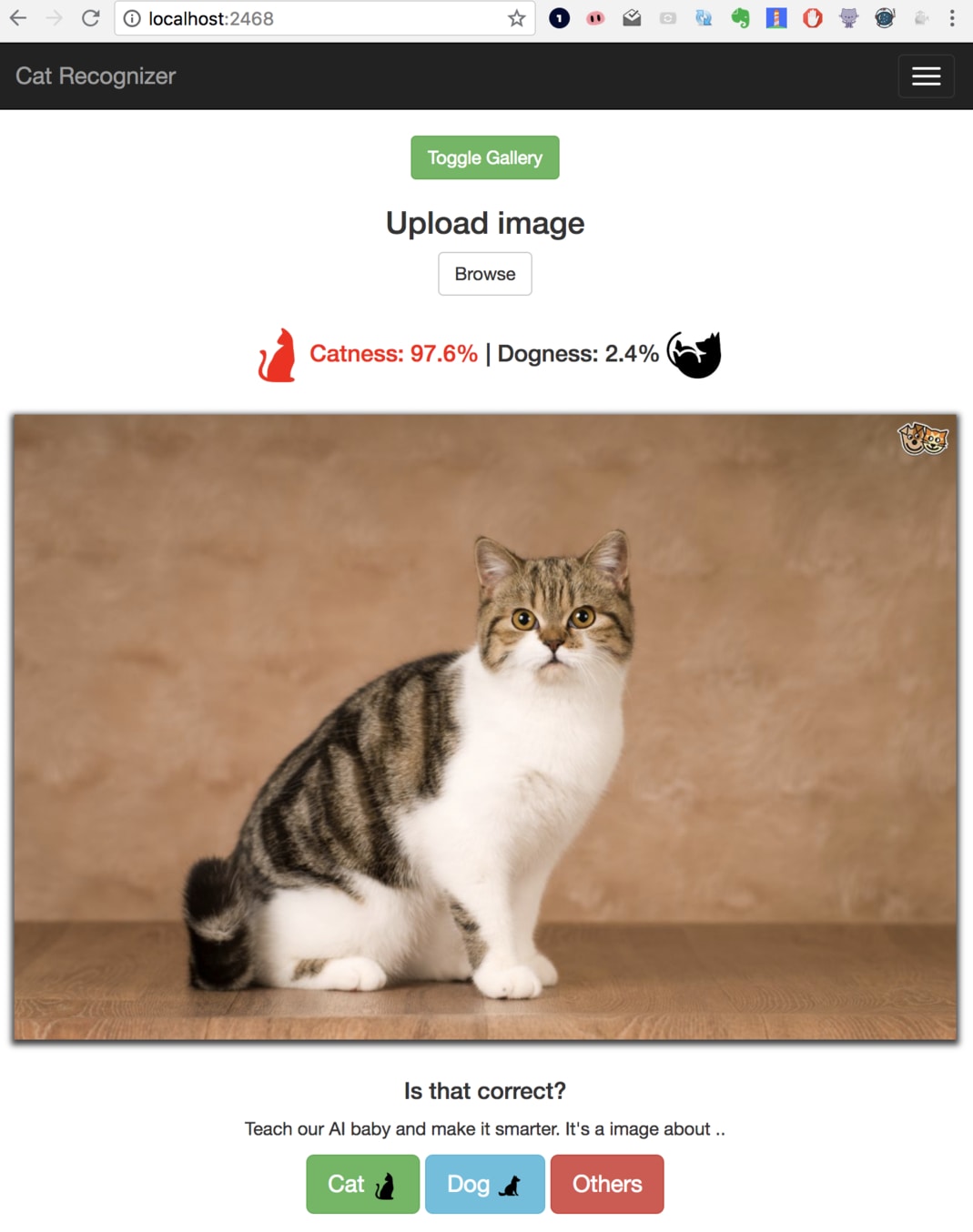
當然這個 ML App 在預測能力以及 UI 上都不完美,但這邊重點是你能利用 Docker 與他人快速地分享成果。如果你有想到其他利用 Docker 封裝好的 ML App 例子(或者是你接下來打算做一個自己的),非常歡迎留言讓我知道它們的存在:)
總結¶
呼!看完本文以後,相信你現在應該對 Docker 有個非常清楚的認識了:
- Docker 是一個能幫我們在各種不同 OS 上建置開發環境的工具
- Docker 三元素包含 Dockerfile、Docker 映像檔(Image)以及 Docker 容器(Container)
- Docker 利用 Dockerfile 預先建置好一個 Docker 映像檔。在使用者想要使用容器的時候,以該映像檔為基礎,運行一個對應的 Docker 容器
- Docker Hub 上有各式各樣可以直接供使用的映像檔
- 你只需要
docker pull及docker run就能開始一個分析專案
給自己鼓鼓掌!
正因為我們是資料科學家,利用 Docker能幫我們抽象化很多不必要的環境建置工作,加速我們的開發效率。
在本系列文章的下篇出爐之前,我鼓勵你先下載 Docker,並開始在 Docker Hub 或者 Google 搜尋一些你感興趣的映像檔,甚至自己寫一個 Dockerfile 將你目前的專案打包起來跟別人分享。
雖然我們這篇因為篇幅關係沒有細講,但只要有一個 Dockerfile,你就能使用 docker build 來輕鬆建立一個自給自足的 Docker 映像檔。一個 Dockerfile 也不難寫,像是上面貓咪的 App 的 Dockerfile 也不過就如此幾行:
FROM python:3.6.3
MAINTAINER Meng Lee "b98705001@gmail.com"
COPY ./requirements.txt /app/requirements.txt
WORKDIR /app
RUN pip install -r requirements.txt
COPY . /app
ENTRYPOINT [ "python3" ]
CMD ["app.py"]
在本篇裡頭我們都是在自己的機器上使用 Docker。在下篇,我們將利用本篇學到的 Docker 知識,將其運用在浩瀚無垠的雲端平台之上,去最大化我們的影響力。
在那之前你可以先熟悉熟悉 Docker,下次遇到你的 DS 同事時,可以問問他/她:
嘿!你的 Docker Image 呢?
跟資料科學相關的最新文章直接送到家。 只要加入訂閱名單,當新文章出爐時, 你將能馬上收到通知