文摘來到第 6 篇,不知道這是你看的第幾篇呢?
這週我們一樣保持閱讀的「營養均衡」,從全球平均壽命變化的資料視覺化、深度學習最夯的「對抗生成網路」話題、產品分析框架到理解何謂「數據工廠」,我希望能讓閱讀本文摘的你,廣泛地了解各領域跟「資料」相關的議題,並進一步找出自己的興趣,加以深度探索。
本週閱讀清單:
- Twice as long – life expectancy around the world
- Interview with Deep Learning Researcher and The GANfather: Dr. Ian Goodfellow
- Data Factories
- Engagement Drives Stickiness Drives Retention Drives Growth
讓我們開始閱讀吧!
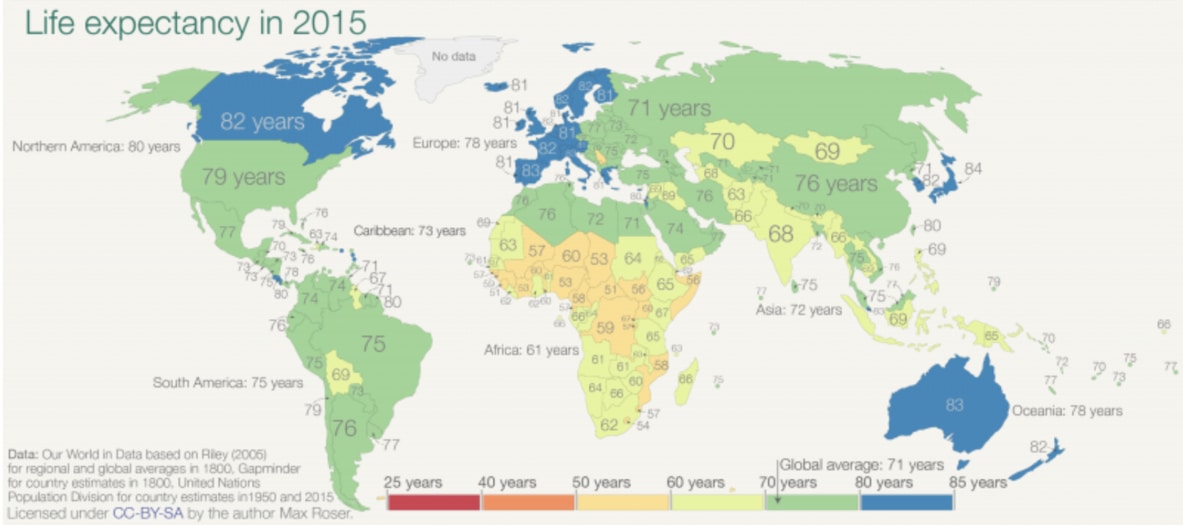
現在全球健康以及公衛還是存在很多不平等,但別忘了我們已經取得巨大進展。
如同我們上週在如何用 30 秒了解台灣發展與全球趨勢:用 GapMinder 培養正確世界觀一文中聊到,好的資料視覺化可以幫助我們快速地了解世界。這週牛津大學的經濟學家 Max Roser 用 3 張橫跨 2 世紀的世界地圖,來告訴我們全球平均壽命(Life Expectancy)的變化:
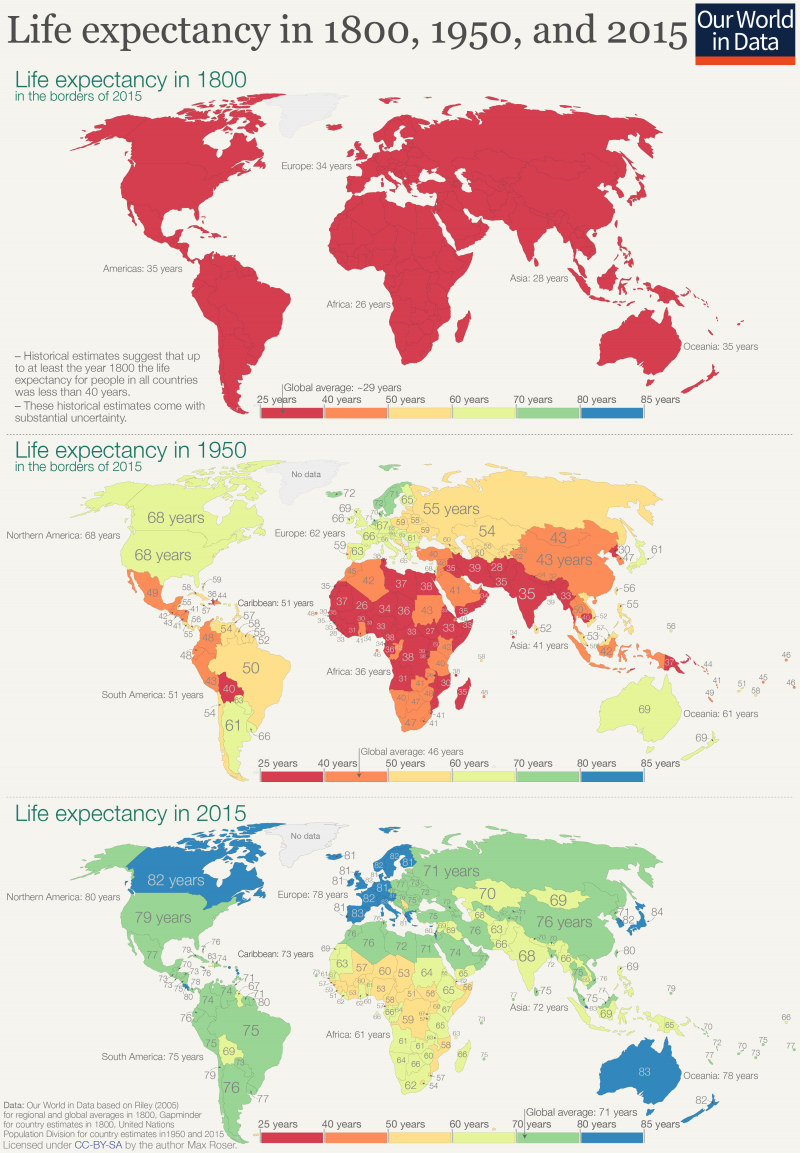
我們可以看到這 200 年來,生活在世界上的人們經歷了 3 個階段:
- 在 1800 年以前所有人的平均壽命 < 40 歲,大部分兒童早夭
- 在 1950 年,部分地區健康大幅改善,歐美及日本的平均壽命為 60 歲,為非洲整體平均的 2 倍,鴻溝顯而易見
- 在 2015 年,幾乎全球所有地區都能活到 60 歲以上,鴻溝逐漸縮小
我們都希望自己親人及朋友活得長久。就是因為這樣,你更應該感激這 200 年人類取得的進步。
近 2 世紀人類在健康狀況改善的卓越成就,套句 Max Roser 的說法就是:
在人類歷史上,這是我們第一次改善了整個人群的健康狀況。在人類健康狀況停滯千年後,封印終於解除。
─ Max Roser
值得一提的是,在 1950 年,台灣的平均壽命為 55.5 歲,經過了 65 年,來到了 80 歲。平均每 3 年,台灣人的平均壽命增加 1 歲,成長速度不可小覷。
你也可以用 Our World in Data 提供的圖表來看看全球變化:

伊恩.古德費洛(Ian Goodfellow)是 Google Brain 的研究科學家,最知名的成就是在 2014 年推出生成對抗網路(Generative Adversarial Network, 簡稱 GAN)。GAN 最基本的概念是讓兩個神經網路互相對抗,讓模型可以依靠較少的人類介入以及訓練資料,自己學會高度複雜的工作。自從那之後,GAN 領域的研究一日千里,現在 arXiv 上該論文有超過 5,000 次引用。

GAN 有非常多「用途」,像是自動產生圖片、創作音樂、寫詩或是製造假新聞。但在這篇文摘裡頭,讓我們先專注於這篇訪問伊恩的內容。
在這篇訪談裡頭,伊恩給想開始研究 ML 的人一些建議:
- 徹底學好基礎。像是寫程式、除錯、並學習機率及線性代數。很多時候在研究 ML 的時候,幫助你最多的是扎實的基礎,而不是非常前衛的想法(這是他從 Google Brain 創立者吳恩達得到的建議)
- 沒有什麼運算資源時,要選對研究主題。(沒有像是 Google 那樣等級的運算資源的話,就不要想去實現全世界最準的 ImageNet 分類器)
- 一開始找個人家已經做過的題目來磨練你的 ML 能力。
最後一點需要額外解釋一下。
如果你在練習 ML 的時候,選擇跟隨前人「已經成功」的東西來實作的話,這樣就算自己實作出來的模型表現不好,你也知道只是你的實作、基本功出了問題,而不是這個點子錯了。接著只要回去複習基本概念、加強實作功力即可。
但如果你的 ML 的實作能力沒到一個水平,然後又馬上想要嘗試一個天馬行空的點子/演算法,最後實作出來失敗,你很難知道,到底是點子本身有瑕痴,還是因為你實作能力差而出問題。
另外如果你現在就想開始了解 GAN 的話,可以試試 GAN lab,在網頁上玩玩生成對抗網路。
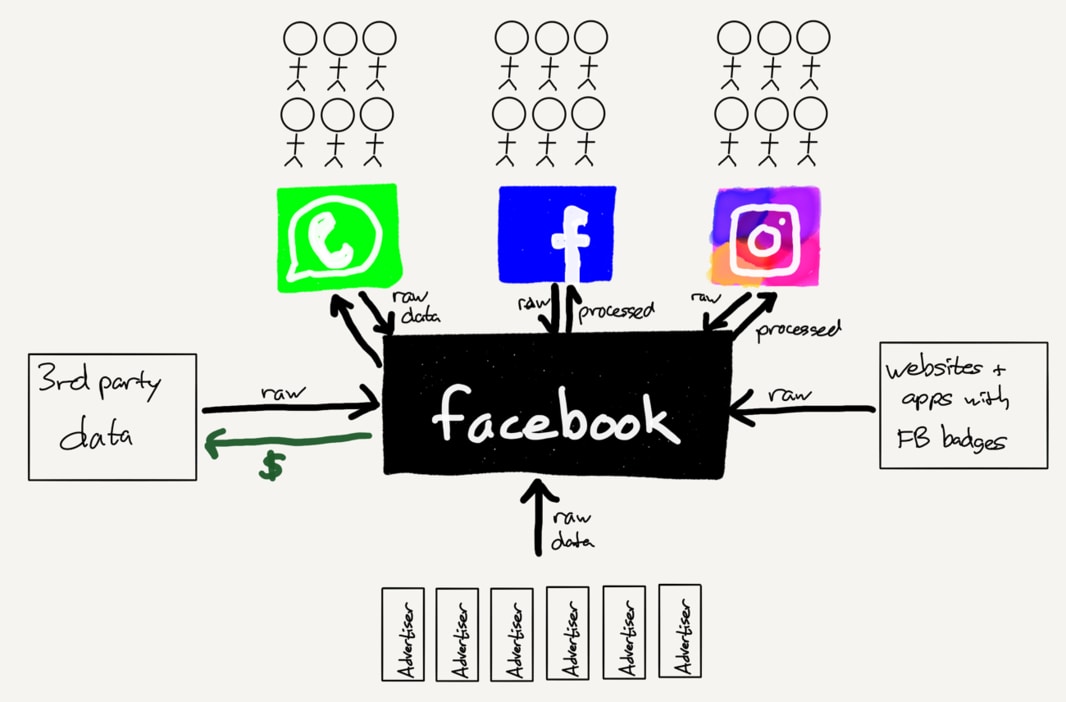
身處數據時代,我們應該更關心自己的資料被怎麼利用。
這篇文章想說的是,其實 Facebook、Google 以及其他廣告業者都是所謂的「數據工廠」,而如果政府要立法規範這些工廠,最有效的方法就是請它們允許使用者看到工廠裡頭的情況。
我認為「數據工廠」是對 Google 及 Facebook 這種利用數據來創造價值的公司的一個貼切比喻。因為他們除了使用者的行為數據,也從廣告代理商以及第三方數據收集業者取得大量資料。透過將這些原始資料「加工」並產生衍生價值,據此創造巨大收益。
然而這些「數據工廠」跟一般傳統的「工廠」有一個非常大的差異:誰都無法窺探該「工廠」的內部情況。

記者可以去 Nike 製造足球的工廠裡頭拍拍照,讓世人知道這些工廠內部的運作情況,但在這年代,你無法去 Facebook 裡頭拍拍照,了解他們是怎麼利用各式各樣的演算法,來「活用」所有跟你相關的資料(你按過讚的內容、瀏覽過的網頁,甚至是你為了雙重認證而輸入的電話號碼)。
因此立法者以及那些關心自己數據可能被濫用的使用者要了解的是,要規範 Facebook 這種公司,不能只要求 Facebook 公布他們從使用者手上拿到的原始資料(Raw Data),而是應該公布那些他們利用演算法以及結合多種數據來源所產生出的 user profile,讓使用者自行判斷要不要繼續讓該公司使用自己的 profile。
雖然多數人其實只在乎 Facebook 能不能秀給他們更多的動物影片以及朋友動態,不太在意自己的數據被怎麼拿來獲利。
在以提供 App 作為服務的公司裡頭,資料科學家大都會需要進行產品分析(Product Analysis)進而改善自家產品。
這篇文章介紹了 App 產業以及我常在使用的一個分析框架,讓你可以感受一下,實際上 DS 在做產品分析的時候,要看些什麼東西。
有做過產品分析的你,應該能很快地理解這個流程圖:
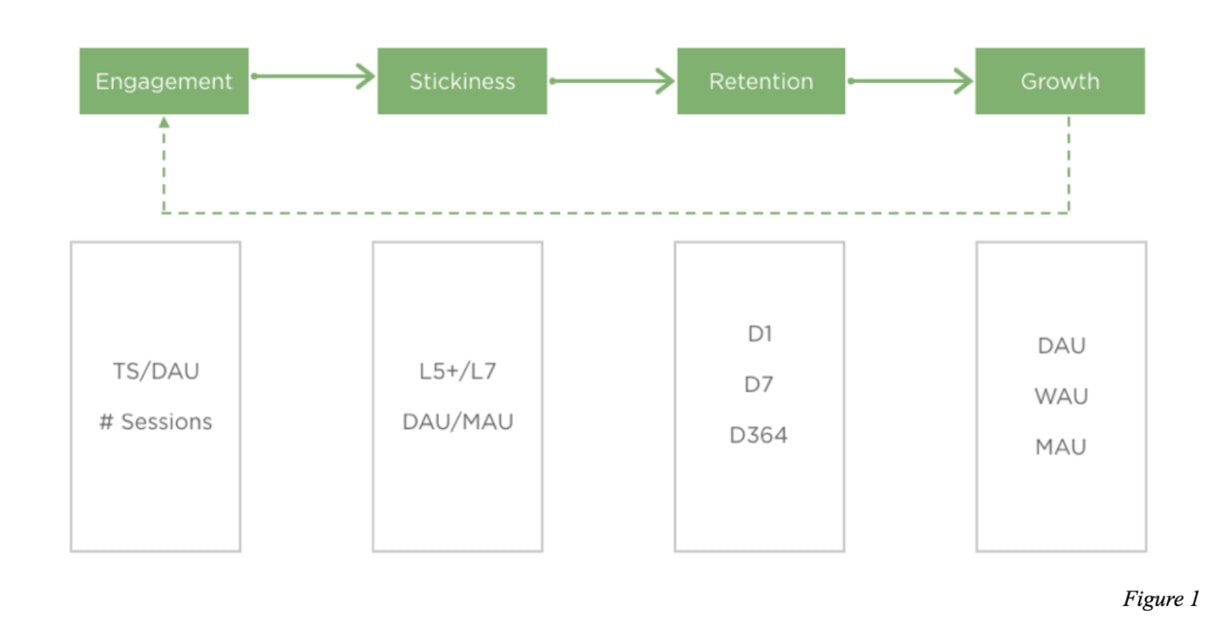
這張圖最重要的核心概念是:
當使用者發現你產品的價值以後,他們會主動回來。
當使用者發現你的產品的價值後,就會進一步參與使用(Engage),而好的參與程度(Engagement Level)會增加他們對此產品的黏著度(Stickiness),進一步讓他們願意回來繼續使用你的產品(Retentaion)。而有了越來越多的忠實用戶,就能進一步帶給你的產品成長(Growth),不斷持續地這個好的循環。
在我們理解每個階段代表的意義以後,我們還需要一些指標(indicators)來實際幫助我們了解產品在每個階段的表現。
像是 Engagement 底下的 TS/DAU 即分別代表「使用時間(Time Spent)」以及「每天活躍使用者人數(Daily Active Users)」。這兩個都很常被拿來衡量使用者參與一個產品的程度。有了好的參與程度,一個使用者就更有可能在安裝 7 天後還回來繼續使用(Retention 階段的 D7)。
這邊沒有篇幅一個個介紹圖中的指標,但要注意的是,在看指標的時候,要去想它是早期指標(Early Indicators)還是延遲指標(Lagging Indicators)。
比方說你的最終目標是提升每月活躍使用者人數(Monthly Active Users,最右邊 Growth 階段的 MAU)這個延遲指標(延遲在於要過了 1 個月你才知道結果),那你除了看 MAU 以外,還需要去看 TS/DAU 等早期指標。因為 MAU 需要一個月的時間才能計算出來,有時候產品表現差,你從每天使用的人數下降就可以略知一二,可以馬上做調整而不需等到一個月後 MAU 數字難看才大傷腦筋。
及早發現,及早治療。
產品分析領域在網路上的資源不多,有機會再跟你分享我的心得。
結語¶
呼!這就是本週文摘的內容啦!希望你閱讀後有感覺自己腦中多了點東西,變得聰明了一點。
社會人口、機器學習、產品分析以及數據隱私的議題,你會發現這些文章儘管領域大相徑庭,他們都與「數據」脫離不了關係。
在這個時代,任何人的日常生活中都充斥著大量數據。我們需要重新思考、檢視並理解身邊的數據,甚至活用它們來創造更好的世界。
這也是我寫這系列文章的原因,希望讓更多人(包含我自己)能更輕鬆地用數據理解這個世界。歡迎你點擊下面的訂閱按鈕,未來跟著我一起繼續探索這個世界:)
跟資料科學相關的最新文章直接送到家。 只要加入訂閱名單,當新文章出爐時, 你將能馬上收到通知