今天讓我跟你分享 4 篇與數據以及人工智慧相關的文章。
在第一篇文章,我們將看到如何用一個簡單、有效的方式來決定應該學習什麼「數據技能」;在第二篇文章,我們則會看到如何透過數據,了解網際網路是如何快速地發展成為人們每天不可或缺的一部分。
接著我們會聽聽在計算神經科學領域的先驅之一,泰倫教授解釋何謂「深度學習」以及 AI 與人類智慧如何擦出火花;最後,我們將一窺 AI 的倫理道德議題以及著名的電車難題。
本週閱讀清單:
- Which Data Skills Do You Actually Need? This 2×2 Matrix Will Tell You.
- The internet's history has just begun
- A pioneering scientist explains "deep learning"
- Establishing an AI code of ethics will be harder than people think
廢話不多說,讓我們開始閱讀吧!

如同我們在揭開資料科學的神秘面紗一文提到,在一個數據時代,提升「資料科學力」這件事情不管是對你自己,或者是對公司的資料科學團隊來說都非常重要。畢竟未來將需要更多跟數據處理相關的人才,數據導向的企業也越來越多。
但是要學的東西太多,你可能不知從何下手,或者什麼都想學。
這篇文章提供了一個簡單矩陣,將那些商業分析師、資料科學家以及機器學習工程師等數據相關職業的常見技能,依照
- 學習、精通該技能所需時間(Time, X 軸)
- 學習後能為自己及企業帶來的效用(Utility, Y 軸)
兩個要素,劃分出一個有 4 個象限的矩陣:
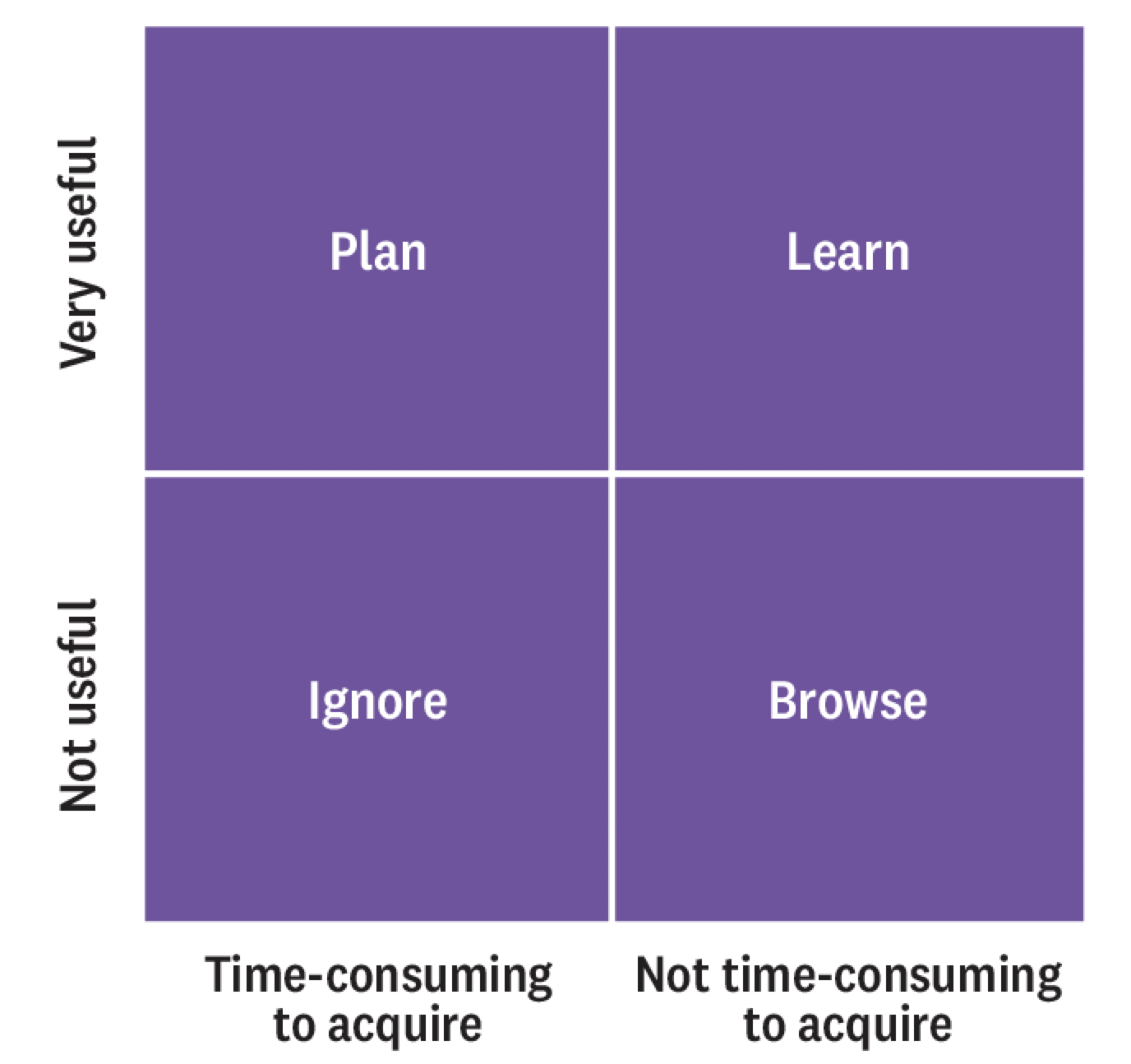
從圖中你可以看到每個象限有不同的特色:
- 左上 Plan:這邊的技能如人工智慧、機器學習,雖然需要花更多時間來精通,但是未來很有用,因此你應該開始規劃長期的學習計畫
- 左下 Ignore:這裡頭的數據技能要花不少時間學習,但在未來能產生的價值卻不高,你應該盡可能忽略它們
- 右上 Learn:這邊的技能不需花太多成本精通,但能為你自己及企業帶來不少價值,應該馬上找時間學習
- 右下 Browse:這邊的技能用處普普,但學習成本也不高,可以瀏覽、儲存相關文章,等有需要的時候拿出來用
事實上,上面的技能擺放位置僅供參考,因為它只是某家公司的資料團隊自己判斷的結果。
你要思考的是,那些你想學的「數據技能」,在你現有的實力下,分別需要花多少時間精通?而它們又能在未來為你帶來多少幫助?
在你心中或是企業策略裡頭,每個數據技能有了自己的位置以後,你就能非常清楚地知道該開始規劃什麼長期學習目標、該著手學習什麼,而哪些技能可以慢點再點。
以我自己為例,就有一些長期學習「機器學習」的規劃,而在日常工作時就頻繁地學習「資料科學」以及「資料工程」。
這個決定學習優先順序的概念,跟我們在資料科學文摘 Vol.5 數據科學家面臨的挑戰、儀表板設計以及未來的被駭人生一文中出現過的艾森豪矩陣有異曲同工之妙。
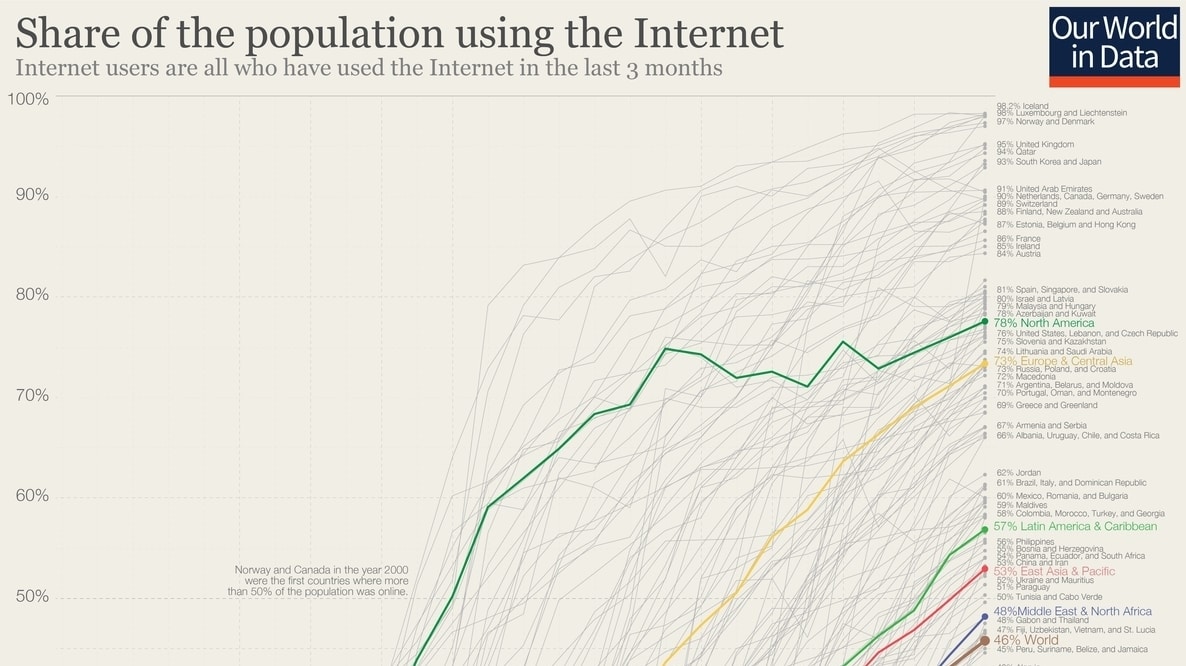
雖然多數的我們早已習慣網際網路(Internet)的存在,但事實上以人類幾百萬年的歷史來看,網際網路的出現也不過短短 20 年,是一個非常年輕的發明(儘管它已經展現巨大影響力)
現在很多人已經無法脫離 Facebook、Google Maps、維基百科甚至是 Github。不過很難想像在我出生的時候(西元 1990 年)這些服務以及網際網路本身都還不存在。
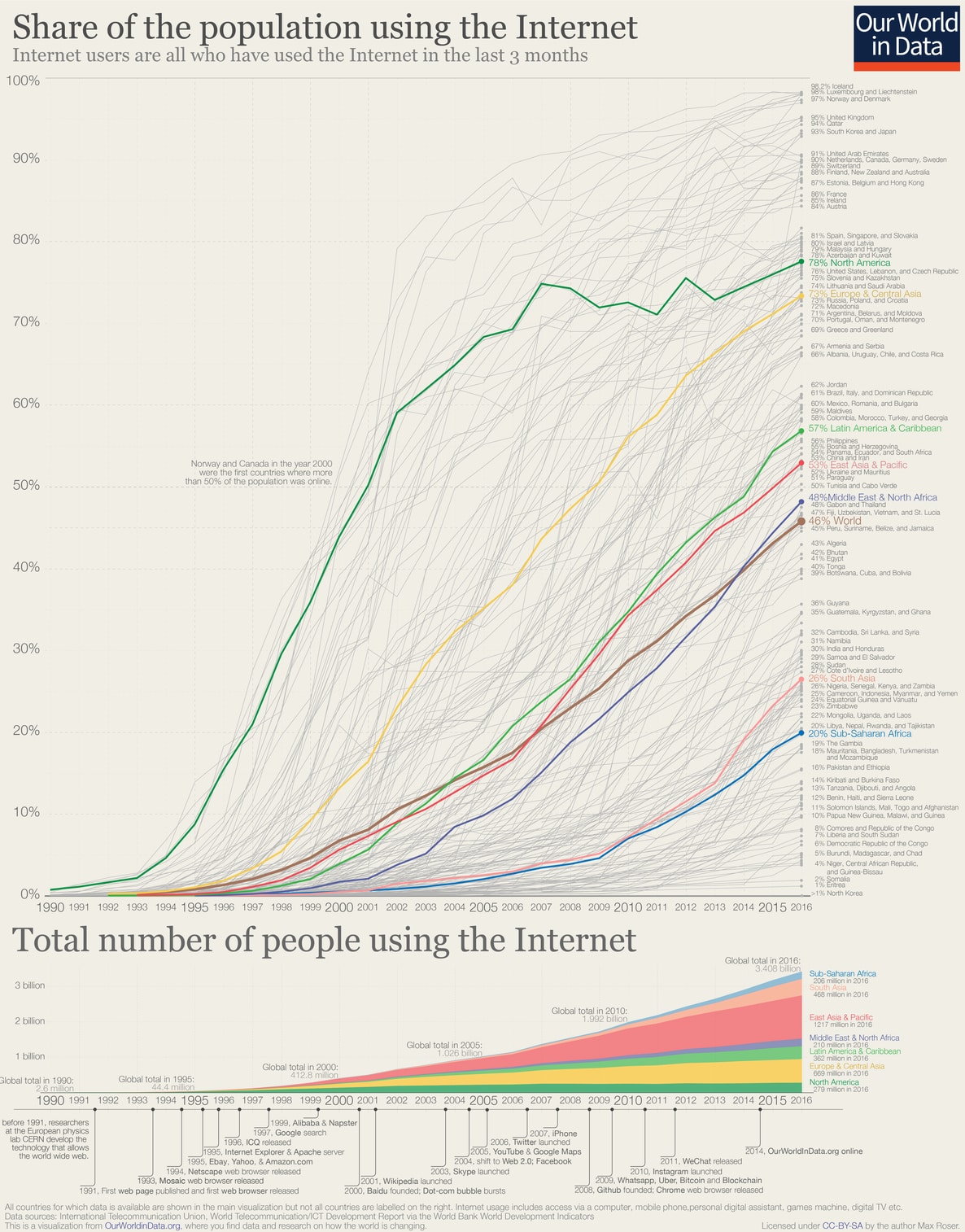
儘管從上圖我們已經可以了解 20 年來網際網路的蓬勃發展,你會發現在 2016 年,上網人口也只佔全球人口的 46 %。
也就是說,世界上還有一半以上的人類沒有像你閱讀這篇文章般地使用網際網路。南亞以及撒哈拉以南也只有 20 ~ 30 % 的人在上網、東亞平均則為 53 %。

隨著網際網路在這些人口成長迅速的地區快速普及,可以合理相信,網際網路在接下來數年還會持續大幅度地改變人們的生活模式。
或許 Internet 的歷史現在才正式拉開序幕。
對我來說,閱讀 Max Roser 這篇文章給我的最大的啟示是:
人類生活模式的轉變只會越來越快,我們需要加速運轉自己的大腦,以跟上未來的變化。
The Deep Learning Revolution 的作者 Terrence Sejnowski(後簡稱泰瑞)教授專注在研究神經科學(Neuroscience)以及計算機科學。
在這篇採訪裡頭,他簡單解釋了人工智慧、機器學習及近年備受注目的深度學習之間的關係。一言以蔽之,就如下圖所示:
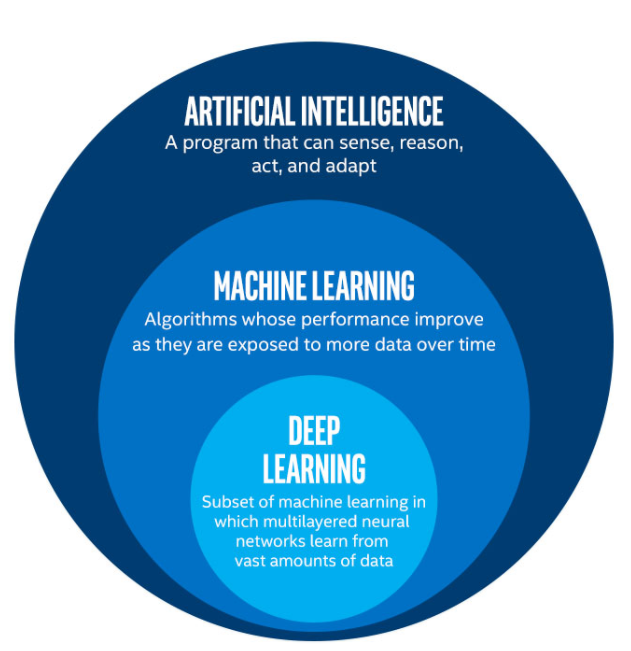
我想平常有在閱讀本部落格的讀者應該都十分熟悉這個關係,不須贅述。不過了解深度學習為何變得如此熱門的人就不多了。
一切要從 2012 年,全世界最大的 AI 學術會議 NIPS 說起。當年深度學習裡頭最關鍵的技術 Backpropagation 的發明者 Geoffrey Hinton 教授與他的團隊展示了如何利用深度學習,一口氣將擁有 10,000 個圖片分類以及多達 1,000 萬張照片的 ImageNet 分類挑戰的錯誤率降低近 20 %。

在這之前,儘管已經有非常多的研究,這個挑戰的錯誤率每年下降不到 1 %。我們可以說,深度學習模型的出現,瞬間縮減了 20 年的研究時間。在那之後,人人爭相學習,開啟「大深度學習」時代。
現在人工智慧發展的背後推手主要即為深度學習,而深度學習的概念則來自於我們對人類大腦的理解。
泰瑞教授表示我們正處於人工智慧以及人類智慧相互匯合的時代:
AI 與人類智慧正在匯合。當我們越了解大腦運算的方式,就會越傾向將該知識反映到 AI 上面,讓 AI 變得更強大。但同時,更強大的 AI 也讓我們用全新的方式以及理論來了解人類大腦以及上千萬神經元的運作方式。因此你可以看到在「神經科學」以及「人工智慧」之間有一個不斷互相學習的循環。
─ Terrence
這個論點跟我們之前在從彼此學習 - 淺談機器學習以及人類學習一文中聊到的想法十分類似:到最後,我們及我們的下一代將不在只是從其他人類學習知識,而是向那些我們創造出來的 AI 學習。

舉個簡單例子,等到語音辨識的技術更為成熟,以後你的小孩可能不再需要一位昂貴的英文老師教他 / 她怎麼唸英文單字,而是透過一個 24 小時不休息的 AI,聆聽由深度學習自動產生的擬人發音來學習英文。
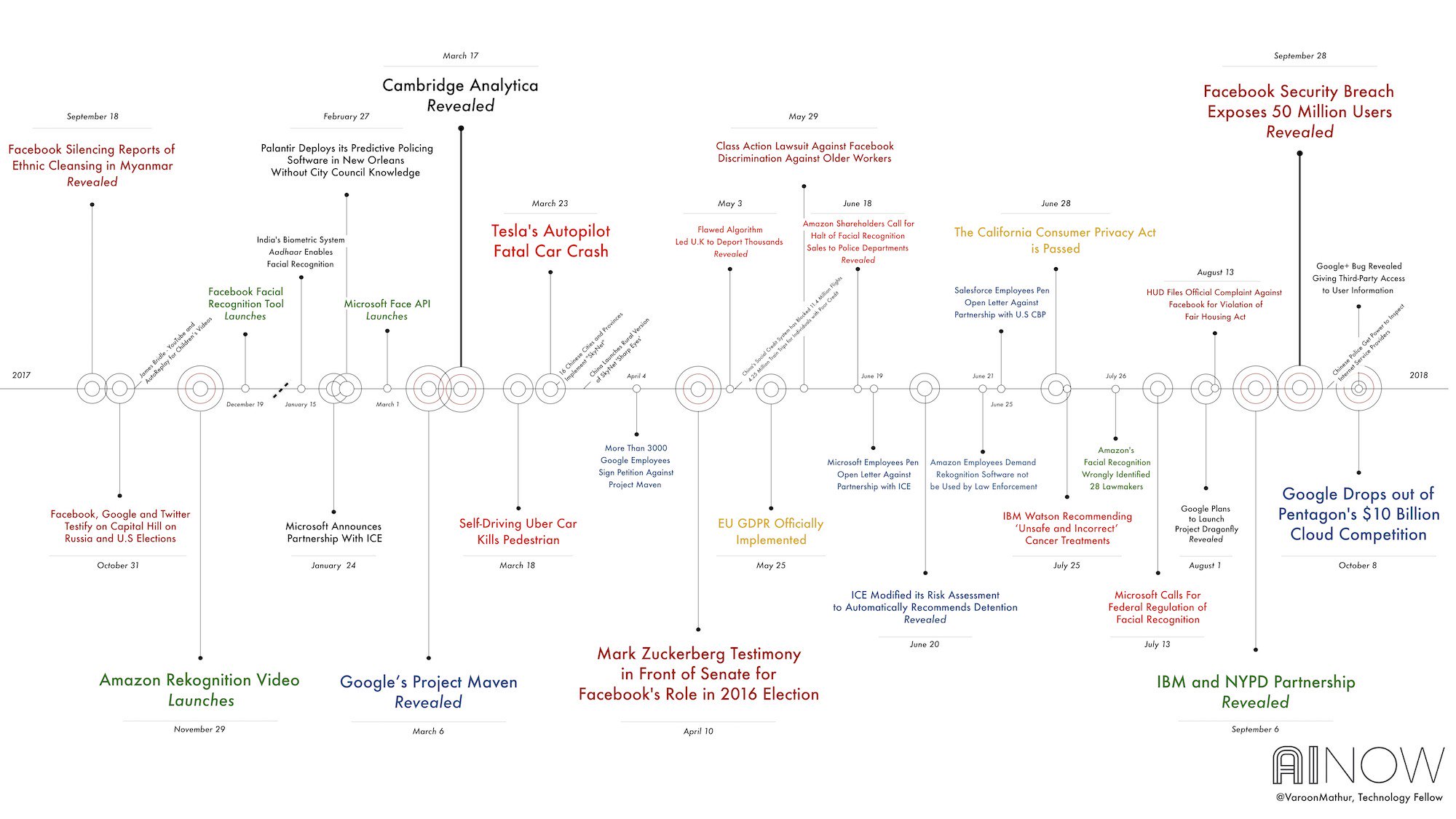
人工智慧的進步一日千里,快到我們還無法為其建立一套完善的道德準則。更甚者,完美的準則一開始就不存在。
AI 的快速發展讓我們已經(快要)可以把一些複雜任務如臉部辨識、自動駕駛等工作交給機器處理,從此過著輕鬆快樂的生活。
但你知道事情從來沒有那麼單純。
除了合乎程式邏輯以外,AI 在執行這些複雜任務時,很多時候會牽涉到道德問題。那麼又應該要由誰來決定這些 AI 在執行任務時應該要遵守什麼規定呢?

美國麻省理工大學 MIT 開發了一個名為「道德機器(Moral Machine)」的網站,裡頭重現了著名的電車難題,目的就是為了告訴大家,每個人都有不同的道德標準,要為 AI 建立一套所有人都能滿意的道德準則非常困難。

你點進去回答完 13 道難題了嗎?
如果還沒,我強烈建議你點進去該網站(站內可選中文),並利用自己的道德準則決定自動駕駛車的運行方向,再實際看看有多少人以及動物因此受到影響,並了解其他人下的決定。

如果你跟我一樣,花了不少時間掙扎猶豫,你就會了解「奠定 AI 所需要遵守的道德準則」這個課題有多麽困難。
就算你好不容易決定了,你也知道該判斷並不完美,你可能之後會後悔,且也不是所有人都同意你的決定。

紐約大學法學院的 Philip Alston 教授則認為我們應該以「維護人權」為最高判斷原則,建立不會傷害到人類的 AI。以上面的自動駕駛來說,一個以「人文主義」為原則的自動駕駛車會選擇避開人群,而往一整群貓咪撞下去。
人文主義或許不完美,但或許是一個不錯的基準點。
只是我擔心的是,在這數據主義以及資本主義橫行的年代,人文主義最後是否能站得住腳。
如果自動駕駛還搭配了臉部辨識系統,利用大數據分析以及搜尋犯罪記錄系統,自動車發現前方分別是一隻貓以及一個罪犯,它能否選擇撞人不撞貓呢?
畢竟以「數據主義」的立場,「人」不再是至高無上的存在,一切由數據說的算。
跟資料科學相關的最新文章直接送到家。 只要加入訂閱名單,當新文章出爐時, 你將能馬上收到通知