說到近年最熱門的機器學習(Machine Learning)或者人工智慧(Artificial Intelligence),因為知識背景以及觀點的不同,幾乎每個人都有不一樣的見解。雖然我們有千百種定義、無數的專業術語,這篇文章希望用直觀的方式以及具體的例子,讓讀者能夠在跳入一大堆 ML 的教學文章以及線上課程之前,能以一個更高層次且人性化的角度理解機器學習,並進而思考要如何開啟自己的機器學習旅程。
不僅如此,你將發現機器學習並不是冷冰冰的科學,隨處可見人類的巧思;就算不是資料科學家,你也能從『機器學習』獲得啟發,將一些概念用在改善『自己的學習』。
讓我們開始吧!
何謂機器學習¶
多虧了媒體的大量宣傳,我們現在都知道機器學習被應用在各個領域。一些常見的例子包含:
- 自然語言處理,如 Google 翻譯、iPhone 的 Siri 語音辨識
- 推薦系統,如 Amazon 的『買了這個商品的人同時也購買了 ...』功能
- 垃圾郵件自動判定,如同我們在《直觀理解貝氏定理及其應用》一文中談到的
- 電腦視覺,如 Facebook 的人臉辨識、Youtube 的影片推薦,影像分類〈這張照片是貓還是狗?〉等
例子不勝枚舉。有那麼多應用機器學習的例子,不禁讓人思考,究竟什麼是『機器學習』?
依照目前機器學習的應用,一個大致上的定義是:
讓機器學習如何將輸入的資料 X 透過一系列的運算,轉換成指定的輸出 y。並提供一個衡量成功的方式,讓機器知道怎麼修正學習方向。
有了這個定義,讓我們再看一下上面提到的幾個例子:
- 自然語言處理:將得到的英文字串〈輸入〉,轉成中文文字〈輸出〉
- 推薦系統:將使用者過去的購買記錄〈輸入〉,轉成使用者可能想要購買的商品列表〈輸出〉
- 垃圾郵件判斷:將郵件內文〈輸入〉,轉成該郵件為垃圾信的機率〈輸出〉
- 電腦視覺:將一個 400 x 400 像素的圖片,轉成多個標籤的機率〈輸出〉

嗯嗯,我想這定義還算合理。
眼尖的讀者會發現,這邊的例子說明了上述定義的一半:將輸入 X 轉換成輸出 y。為了進一步解釋後半段『衡量成功的方式』,下面讓我們以一個虛構的咖啡機舉例。
機器學習實例:智慧咖啡機¶
假設你是個咖啡愛好者,家裡有好幾台高檔的咖啡機,但每次泡出來的咖啡都不合你胃口。
經過無數的失敗,忍無可忍,你最後決定向月巴克公司買台『智慧』咖啡機。該咖啡機宣稱可以了解你的個人需求,泡出世界上最符合你胃口的咖啡。
拆開咖啡機包裝,你興奮地把咖啡豆、砂糖以及牛奶加到該咖啡機裡頭。幾分鐘過後,號稱世界上最好喝的咖啡完成了!

外觀看起來不錯,你滿懷期待地啜了一口。
『太甜了吧!砂糖太多了,什麼鳥機器!』
你怒吼著,幾乎馬上萌生退貨的想法。這時候咖啡機感應到你的抱怨,用很委屈的聲調說:
『目前調配咖啡的方式為原廠設定。經過統計分析,要得到一個正常台灣人的最佳評分,平均一杯咖啡裡頭的咖啡豆顆數、砂糖匙數以及牛奶的小杯數的比例應該要是 10 比 2 比 3。』
你只覺得莫名其妙,心想這什麼神奇的比例。而且咖啡機剛剛是在拐彎抹角地說我不正常嗎?
這時候咖啡機又說話了:
『為了做出最符合您口味的咖啡,滿分 100 的情況下,請按鈕輸入你認為此杯咖啡值幾分。另外請告訴我是哪邊出了問題,如糖份比例太高還是牛奶太多,以讓我能記住您的喜好。』
你翻了個白眼,喝杯咖啡還要教機器怎麼調配?哪裡智慧了?
但為了喝到最符合自己喜好的咖啡,你決定給咖啡機一個機會,好好地調教它。針對眼前這杯咖啡,你把自己的回饋〈評分、調配比例的建議:砂糖太多〉老老實實地輸入進去。
於是乎就這樣,不知不覺中你已經與月巴克咖啡機一起踏上了調配世界上最好喝咖啡的學習之旅。

為了實際了解咖啡機怎麼學習,你翻開咖啡機使用手冊,看到以下內容:
《月巴克智慧咖啡機說明指南》
- 基本假設;使用者評分 = 使用者滿意程度
- 預測使用者給咖啡的評分
y'=w1* 咖啡豆顆數 +w2* 砂糖匙數 +w3* 牛奶小杯數 + 基本分b - 目標:找出一組調配比重
w1, w2, w3, b,使得咖啡機預測的評分y'越接近實際的使用者評分y越好 - 咖啡製作:使用上述比重調配咖啡,使得預測評分
y'接近 100 - 各原料調配比重〈原廠設定〉:
w1 = 10, w2 = 2, w3 = 3, b = 60
...
你恍然大悟,原來月巴克公司為了讓咖啡機最大化你給咖啡的評分,在咖啡機裡頭建構了一個簡單的線性回歸〈Linear Regression〉模型。
在這模型裡頭,使用者針對一杯咖啡的評分 y 會受到多個原料的量的影響。每個原料量的影響程度則透過個別的 w 來描述。理想上,如果咖啡機可以找出一組比重〈weights〉 w ,使得咖啡機『預測』出來的評分 y' 跟『實際』使用者給的評分 y 非常相近的話,咖啡機就可以利用該模型來合理地選擇咖啡豆、砂糖以及牛奶的量,調配出一杯預期能獲得你最高評分的咖啡。
那咖啡機要如何實際『學習』呢? 或者換句話說,咖啡機要怎麼樣知道它現在用的參數〈w1、b等〉夠不夠好呢?如果不夠好的話,要怎麼修正呢?
在一開始完全沒有任何使用者回饋的時候,咖啡機可以很合理地使用原廠設定來計算使用者評分 y'。等到你輸入了一些評分 y 以後,將所有從你得到的評分 y 跟咖啡機自己預測的 y' 做比較,看咖啡機做的預測評分跟你的給分差了多少,據此修正原料的比重 w 以及 b。y'跟y的差異讓我們暫時稱作 diff_y。
修正以後,一般來說我們會得到新的比重 w' 以及 b'。當咖啡機使用 w' 以及 b'產生新的預測評分 y'',其跟你的實際給分 y 也會有一個差距,我們則將其稱作為 diff_y'
當使用新的參數〈w1、b等〉產生的 diff_y' 比原來的 diff_y 來小的時候,我們就能很開心地表示:『這咖啡機幹得真不錯!學到了點東西,能更準確地找出我的喜好!』。
而在每次獲得你回饋的時候重複上述步驟,咖啡機不斷地修正它用來預估你給咖啡分數的參數,讓預測出來的值 y' 跟你過去所有評分 y 之間的差異都更小。雖然我們這邊不會細講,但在線性回歸裡頭,一個常被用來計算預測值 y' 跟實際值 y 差異的方式是最小平方法〈Least Squares〉:
diff_y = 針對每次使用者的評分 y,機器利用當下的參數產生相對應的 y' 以後,用兩者計算 (y' - y) 的平方並加總它們
你可以看到,當 diff_y 越小,代表咖啡機越能準確地依據目前的原料量,來預測你會給咖啡的評分。

咖啡機學得很快。經過幾個怒吼以及失望的夜晚,透過你給的回饋,它現在做出的咖啡已經能很穩定地讓你給出 90 分以上的評價。
透過詢問咖啡機,你現在知道,為了獲得你的高評價,咖啡機學到了以下的模型:
- 你給咖啡的評分 = 咖啡豆顆數 * 13 + 砂糖匙數 * 1.2 + 牛奶小杯數 * 1.5 + 基本分 40 分
這跟一開始為了滿足所有人的原廠設定相比,還差真不少:
- 一般使用者評分 = 咖啡豆顆數 * 10 + 砂糖匙數 * 2 + 牛奶小杯數 * 3 + 基本分 60 分
依照你過去的回〈ㄊㄧㄠˊ〉饋〈ㄐㄧㄠˋ〉,咖啡機發現跟一般人相比,咖啡豆量對你來說,是一杯咖啡好不好喝的重要指標〈13 vs 10〉,砂糖跟牛奶量則反而顯得沒那麼重要。而從基本分來看,咖啡機甚至學到你對咖啡的要求程度比一般人要來得嚴格〈40 vs 60〉,實實在在地說明機器了解你是個專業的咖啡愛好者。
現在再讓我們看一次前面定義的機器學習:
讓機器學習如何將輸入的資料 X 透過一系列的運算,轉換成指定的輸出 y。並提供一個衡量成功的方式,讓機器知道怎麼修正學習方向。
經過上面的咖啡機例子,我們能清楚地歸納出以下幾點:
- 咖啡機是在進行機器學習,學習如何用一連串運算,將原物料的量〈咖啡豆顆數等〉
X轉換成使用者評分y - 機器學習裡所謂的一系列運算,在咖啡機的例子裡是進行線性回歸,即
y = w * x + b - 咖啡機衡量成功的方式是計算『預測評分
y'跟實際評分y之間的差異大小』,此差異越小,代表學得越好 - 衡量成功的方法很重要,因為咖啡機可以知道『努力/學習的方向』
- 咖啡機透過反覆地修正參數,進而最小化上述差異,成功地『學習』
- 機器學習是學習一組最符合目標的『參數』〈如基本分的
40、咖啡豆顆數的13〉
我們可以總結說,咖啡機在你給的回饋以及監督之下,想辦法從三種原料〈咖啡豆、砂糖、牛奶〉中,『學習』出一個最棒的調配比例,以做出一杯能得到你最高評價的咖啡。在機器學習領域裡頭,這實際上被稱作監督式學習〈Supervised Learning〉。
太棒了,你跟月巴克咖啡機從此過著幸福美滿的日子‧
如何讓機器學得更好¶
如果你閱讀完上面例子,開始思考以下問題:
- 『除了原物料的量以外,或許還可以搜集其他類型的資料,像是咖啡機主人的性別、年齡甚至泡咖啡的時間,然後把它們加到模型裡頭以提高預測評分的準度?』
- 『除了簡單的線性回歸,我們應該也可以用其他更複雜的模型或演算法來預測使用者的評分?』
- 『與其預測使用者評分,能不能建立新的模型,直接預測使用者喜好?』
- 『如果咖啡機得到更多我的回饋資料,是不是會更準?』
- 『我的喜好會隨很多因素如時間做改變,要怎麼讓咖啡機模擬這情況?』
- 『這咖啡機學到最後,是不是只能產生適合我口味的咖啡,而不能產生大家都喜歡的咖啡?』
我得說聲恭喜,你已經擁有機器學習的思維且準備好進入機器學習的殿堂了。
但在你摩拳擦掌,準備進入殿堂時,有些人可能會跟你說,近年因為機器學習在各領域發展神速,且機器能使用的訓練資料〈Training Data〉也越來越多,強人工智慧〈Strong AI〉很快就會出現。不久的未來,我們甚至也不用自己設計演算法以及模型,A.I.會自動幫我們全部做好。也就是:機器會自己讓機器學得更好。

真的嗎?沒有人能真正的預測未來,所以我們無從知曉。
但至少在接下來幾年,要讓機器學習或者人工智慧再繼續進步,『人類的思考』是不可或缺的重要因素。主要體現在兩個地方:
- 機器並沒有意識判斷『為什麼』以及何謂『對的方向』
- 機器的世界觀是人類教的
機器並沒有意識判斷『為什麼』以及何謂『正確』¶
電腦因為有著強大的記憶以及運算能力,在很多任務上面都已經可以超越人類的表現。
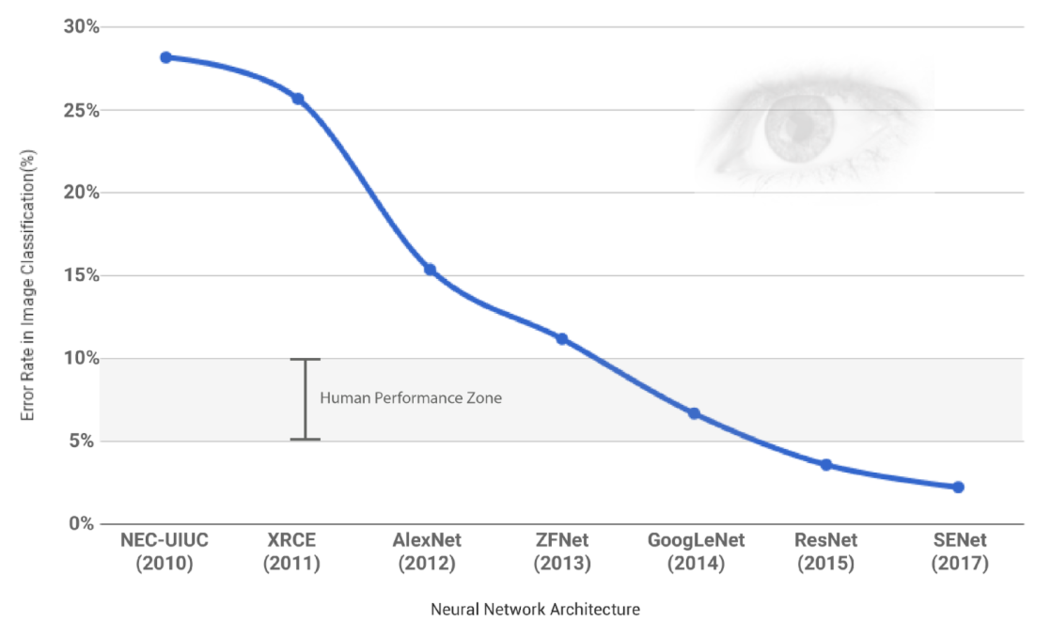
但能達到這樣的成果的前提,都是因為有人類在設計模型、監督機器學習。
目前機器學習或是 A.I. 的應用其背後的模型,當你去看裡頭一行行的程式碼的時候,裡頭並不會定義『為什麼』要做這些任務。實際上,在機器學習的過程中,機器並沒有意識到為什麼要做這些任務;而如果沒有人類的介入的話,機器也不會自己定義什麼樣的結果叫做『成功』或『正確』,而也就不知道該往什麼方向學習。
- 該讓機器學習什麼
- 怎麼定義『正確/成功』,讓機器遵從並往該方向改善
這兩件事情只有依靠人類來做決定。而其決定將大大地影響機器學習的成果以及品質。機器不會跟你說:
『我覺得把影片裡面的貓咪識別出來,比識別出交通號誌燈來得重要。』
『喔... 我覺得我們學的方向怪怪的,讓我們往這個方向學習如何?』
一個定義出錯的目標函式〈Objective Function〉將永遠無法讓機器學出我們想要的結果。
針對這點,我們應該:
找出值得解決的問題,下定我們的目標並明確定義何謂『正確』,以讓機器往該方向學習。
機器的世界觀是人類教的¶
第二點應該也不難理解。一個機器的世界觀基本上取決於兩點:
- 人類指定使用的模型〈Model〉
- 餵給它的資料〈Data〉
如同前面咖啡機的線性回歸,我們透過一個簡單的線性模型,教會咖啡機看世界。在咖啡機所認知的世界裡頭,使用者的評分就只會受到三種原物料量的影響:咖啡豆、砂糖及牛奶。這是一個非常簡單的世界,方便我們理解機器學習,但在真實世界上基本上不會成功運作,你需要考慮更多因素。
如同我們前面有提到,你可能會思考以下問題:
- 『我的喜好會隨很多因素如時間做改變,要怎麼讓咖啡機模擬這情況?』
- 『除了原物料的量以外,或許還可以搜集其他類型的資料,然後把它們加到模型裡頭以提高預測評分的準度?』
- 『除了簡單的線性回歸,我們應該也可以用其他更複雜的模型或演算法來預測使用者的評分?』
- 『這咖啡機學到最後,是不是只能產生適合我口味的咖啡,而不能產生大家都喜歡的咖啡?』

事實上你已經在思考如何擴充機器的世界觀了。你可以使用各式各樣的模型、更多的資料以讓機器能用更全面的方式來理解這個世界。而這個新的世界觀只能由你來定義。
〈現在的〉機器不會突然跟你說:
『嗯... 我覺得我們應該考慮泡咖啡時有沒有下雨,因為這可能會嚴重地影響使用者心情,進而影響評分。』
『我只依照你的評分做最佳化,可能會有過適問題喔!』
這些問題都是我們必須自己發現並解決,不能只期待機器自動解決〈至少這幾年〉。在機器學習領域裡頭,最怕的不是模型完全不行,而是上述的過適〈Overfitting〉問題:機器所看到的資料本身太過侷限,導致其雖然只看到真實世界的一小部分,就誤以為那是全世界。換句話說,機器裡存在著強烈的偏見〈bias〉。前陣子常聽到的案例是白人設計出來的臉部辨識模型對黑人有偏見。
以我們咖啡機的例子來說,如果你家裡只有你一人,咖啡機只需要服務你一人即好;但如果你們是一個家庭,家裡的人都希望咖啡機能為它們弄出好喝的咖啡,則每個人都需要給予咖啡機回饋,以讓咖啡機了解每個人喜好。如果仍然只有你一個人給予咖啡機回饋,其他人不給分,則咖啡機會以為得到的評分來自所有人,誤以為只要最佳化這些評分,就能滿足所有人,其實不然。
為了讓機器看得更遠更全面,我們應該:
想辦法在機器學習的模型內融入更多我們的直觀想法〈intuition〉,並讓機器看到更全面的資料,以拓展機器的『世界觀』。
如何改善我們的學習¶
閱讀到此,相信你對機器學習已經有個高層次的理解了。
在對機器學習有個基本的了解以後,我們在前面章節提到為了讓機器學得更好,一個可行的方向是將我們的直觀想法、世界觀轉換成機器可以運算的模型或是目標函式,以讓機器能從聰明的我們身上學習。但換個角度思考,在我們教機器『學習』的時候,應該也能從機器『學習』到什麼才對。
事實上,很多我們應用在機器學習領域的想法,緊密地跟我們的個人生活息息相關。
舉個例子,在機器學習中,過適〈Overfitting〉是我們最想要避免的問題。我們不會希望機器只學到事物的表象,或者受到 outliers 的影響,而是希望機器學到更重要的模式〈Pattern〉、趨勢〈Trend〉。所以研究者們透過各種方式來讓機器不要過適:
- 輸入更多資料
- 用更簡單的模型
- 減輕 outliers 的比重
- 正規化〈Normalization〉
- ...
而當機器成功地學到了事物的本質,就能精準地預測未來並且概括所有情況〈Generalize〉:
- 預測股票漲幅
- 預測誰最後會當上總統
- 預測詐騙交易
- 預測一張照片裡頭有什麼物件
畢竟,一個只看過貓跟狗照片的機器,不管未來看到什麼,就算是汽車或是人類,也只會將視它們為一定程度的貓或者是狗。
如果你只有一個槌子,你可能就會把每個問題都視為釘子。

同樣道理可以應用在人類的學習上。
當我們只注重在參加各式各樣的線上深度學習〈Deep Learning〉課程,而不去了解機器學習背後的原理就是一種過適;當我們掙扎著要用 Python 還是 R 畫漂亮的圖,而不去理解為何要這樣畫,才能讓觀眾更容易理解時也是一種過適。更不用說一個只了解決策樹〈Decision Tree〉的同學,看到什麼問題都會想要用決策樹來解的案例了。
學習表象比較簡單沒錯,但不能帶你走很遠。了解趨勢或者模式則讓你看到未來:
- 卓越的歷史學家忽視單一歷史事件,透過了解世界整體的歷史脈絡來預測未來
- 愛因斯坦觀察到世界的運作原理而推出有名的質能轉換公式
E = mc²
好的學習方式是理解事物背後的運作的趨勢、模式。為何我們要機器學習?為什麼深度學習會崛起?注重在詢問更多的『為什麼』以理解事物本質。
從一些已經被應用在機器學習的概念獲得啟發,我們可以重新思考並改善我們人類自己的學習。
結語¶
我們在這篇文章前半段以一個虛構的智慧咖啡機為例,深入探討機器學習的一些基本但十分的重要概念以及運作方式。
在掌握機器學習的基本概念以後,我們討論了如何以『人』為本,融入我們人類的智慧以讓機器更聰明地學習、了解這個世界。接著,我們用了一點篇幅,討論了看似不相關的『人類學習』以及『機器學習』之間一個共同且最重要的核心目標:『學習如何去概括〈Generalize〉事物並避免過適〈Overfitting〉』。
現在機器學習〈尤其是深度學習〉跟其他學術領域如統計、電腦科學相比,是一個相對新的領域,大家都還在摸索階段。但正如當年新興的程式設計已經普遍被重視,甚至加入國高中教育一般,我想再過幾年,等機器學習更為成熟後,人們也會開始呼籲將『機器學習』領域的知識納入課綱,成為我們下一代的基本素養之一。

或許那就是本篇所提到的『從機器學習中學習』。
但在那時代到達之前,讓我們開心機器學習吧!
跟資料科學相關的最新文章直接送到家。 只要加入訂閱名單,當新文章出爐時, 你將能馬上收到通知