身為一個資料科學家,我平常會寫些相關領域的文章,像是
它們都獲得不錯的迴響,我也得到不少很棒的回饋。
不過如果只是介紹特定跟資料科學(Data Science,以下簡稱 DS)相關的工具或概念的話,我們可能會陷入「見樹不見林」的窘境:知道很多 DS 的知識,但卻不曉得這些知識是如何實際被運用在解決人們或是企業的問題。實際上我相信大多數企業的資料科學家在做的事情,並不像很多線上課程那麼單純;有時候你需要結合多種領域的知識,如資料工程、分析手法以及領域知識(Domain Knowledge)來解決一個商業問題。
為了讓有志成為資料科學家,或是單純想要了解的讀者們能理解 DS 是如何實際被(企業)應用,以及讓自己多一點反思的機會,趁著最近開始在 SmartNews 的新工作,我打算開始(不定期地)紀錄自己平常的工作內容以及一些經驗分享(當然,在不洩漏隱私資訊的前提下)。

這系列文章將以類似說故事(奇幻旅程,喔耶!)的手法,闡述我在 SmartNews 遇到的一些挑戰,以及作為一名資料科學家(Data Scientist),我如何利用手邊各式各樣的工具以及手法來解決這些問題。透過問題導向(Problem-oriented)的方式,我希望能讓更多人理解 DS 是如何實際被應用在企業之中,進而思考自己該如何預先準備,減少進入這個領域的障礙。(歡迎分享你的想法!)
在後面幾篇文章,我們將有機會深入探討一些分析手法、如何建置預測模型,以及建置可靠的資料流(Dataflow)。但在那之前可別忘了:「巧婦難為無米之炊」。我們才剛剛開始資料科學家的工作,就連筆電裡頭也是什麼軟體都還沒被安裝呢!
因此在大展身手之前,在這篇文章我們將討論作為一個資料科學家,如何在開始第一個分析專案的同時,「有效率」地熟悉新環境。後面你將會發現,這個初始步驟看似瑣碎,卻能讓之後的工作進行地更為順利。
熟悉環境 = 安裝軟體?¶
讓我們想像一下剛從 IT 管理部門手上拿到新筆電的情境。
通常拿到公司配的新電腦以後,一個資料科學家會思考的幾個問題是:
- 「我要在新電腦上面裝什麼軟體?」
- 「公司的資料科學家們用什麼軟體?」
- 「我要怎麼存取公司的資料?」

這些問體的確很重要也很實際(practical),也是我當初能馬上想到的問題。但後面我們會看到,該安裝什麼軟體、該怎麼存取資料庫都是「熟悉環境」裏頭最簡單的部分。為什麼?
因為通常 manager 會準備好一個清單告訴你該裝什麼,只要照著做就好了。這個清單當然會依照公司內部使用的技術而有所差異,但在大 Google 搜尋時代之下,要在自己的筆電安裝任何東西(應該)都不是太困難的事情。
就算公司沒有給你清單,沒問題!事實上,我也不過就安裝了以下軟體:
當然隨著專案的增加,你可能還會需要其他工具,但基本上沒有想像中的那麼多。有了開發/分析工具以後, IT 管理部門也會跟你說明該如何透過加密的方式,存取一些重要的資料庫以及伺服器。等到這些都搞定以後,理論上我們已經可以準備寫落落長的 SQL 查詢來結合多個資料庫的表格,並使用各種酷炫的 Python packages 進行分析了!
不過在進行分析的同時,有一些問題值得我們花幾天慢慢地思考。這篇我想特別強調 2 個:
- 公司內有什麼關鍵績效指標(KPI)?
- 這些 KPI 是怎麼被產生並顯示在儀表板(Dashboard)上的?
你可能覺得這些事情看起來並不直接跟資料分析相關,但接下來你會看到,為何在進入公司早期就理解它們,對一個資料科學家來說很重要。首先讓我們看看第一個問題。
公司內有什麼關鍵績效指標?¶
為什麼了解公司內有什麼關鍵績效指標(Key Performance Indicator, 後簡稱 KPI)很重要?
因為這些 KPI 代表著一企業或團隊衡量成功的方式,同時也決定了資料科學家們將要努力的方向。沒有這些 KPI,我們將不能評估我們是不是走在對的路上,也不知道前進的速度。講得浮誇點,一個資料科學家能提供的最大價值就是:
分析數據、從中找出洞見讓企業做出更好的決策,以在最短的時間內最大化 KPI
以這樣的角度來看,KPI 的概念就跟機器學習中的目標函數(Objective Function)的概念相同,差別只在於我們是用電腦去最佳化目標函數;用人腦去最佳化企業的 KPI。
因為 SmartNews 是一個新聞 APP,讓我們舉些手機 APP 產業中常被使用的 KPI 為例:
- 安裝次數(#Installs)
- 每人平均使用時間(Session Time)
- 瀏覽頁面數(#Page Views)
- 每天活躍人數(#Daily Active Users)
- 每月活躍人數(#Monthly Active Users)
- 重度使用者人數(#Heavy Users)
- 每日廣告營收(Ad Revenue Per Day)
儘管相同產業可能用類似的 KPI,每家公司給的實際定義(Definition)可能有所出入。不同公司之間的定義有差異是正常的,但該定義合不合理就是另外一回事了。
就跟我們訓練一個機器學習模型的時候會注意目標函數的定義是否合理一樣,在了解有什麼 KPI 以後,我們也應該積極地去詢問相關人員,了解這些 KPI 的定義是否合理。像是:
- 怎樣的行為可以算是完成安裝?是使用者第一次打開 APP 的瞬間算安裝,還是完成新手教學的時候呢?
- 何謂活躍?使用者要做什麼操作才算活躍?打開 APP,更改設定就關掉也算活躍嗎?
- 何謂重度使用者?過去一個月使用超過 7 天的人算嗎?

如果 KPI 的定義不合理,糟一點的結果就是你的努力方向對了, KPI 卻沒有上升;更糟的結果則是你往錯的方向最佳化:錯誤的 KPI 提升了,你則沾沾自喜。儘管定義合適的 KPI 需要大量的領域知識,在剛開工的時候,你仍應該對現有的 KPI 做出適當的質疑,嘗試理解它們的合理性。
現在假設 KPI 的定義沒有明顯問題,不管什麼公司都會希望能將這些 KPI 即時地顯示在儀表板上以方便監控自己的營運狀況。但如果一個 APP 的下載次數超過 2500 萬,每天產生上億筆使用者存取紀錄的話,幾個衍生出來的問題就是:KPI 該怎麼從這些原始資料產生出來的?如何保證中間沒有出錯?我們能信賴這些計算出來的值嗎?
讓我們在下小節討論這個問題。
儀表板上的 KPI 是怎麼產生的?¶
實作方式會依照公司有所不同,但讓我們以 SmartNews 為例。
我們的儀表板是使用 CHARTIO,但基本上 CHARTIO 這種儀表板服務也只是一個 Web UI,它並不會自動幫我們把使用者的存取紀錄轉成 KPI。為了理解每天人們使用 APP 的情況,我們必須自己將所有網路伺服器(Web Servers)上的使用者存取紀錄(Log Data)做一系列的處理以後,轉變成儀表板上的 KPI。
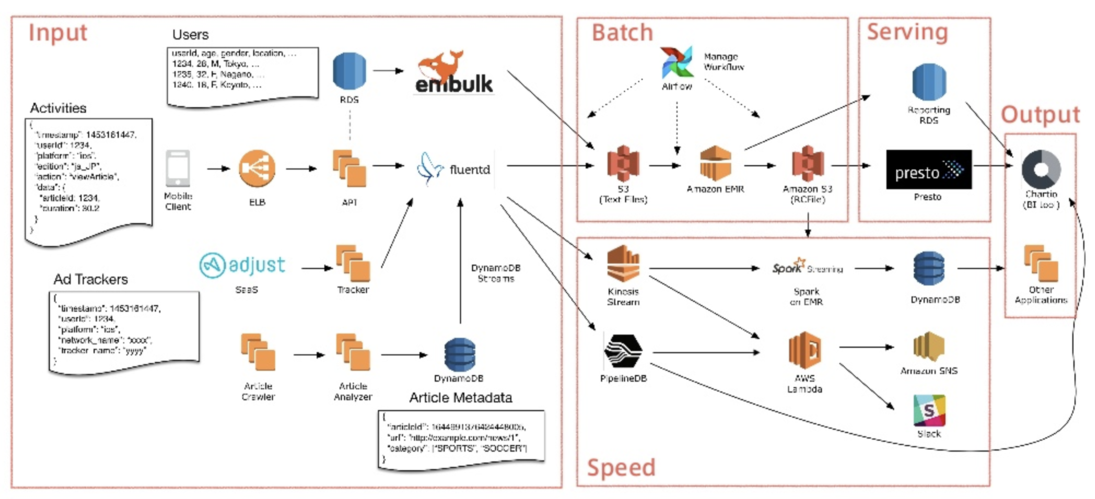
而一個使用者的使用行為大致上會經過以下幾個步驟轉變成 KPI:
- 使用者打開 SmartNews App,手機客戶端向網路伺服器做出請求(Request)
- 網路伺服器回傳結果,並將該請求紀錄存在自己的硬碟上
- fluentd 搜集所有伺服器上的請求資料,將它們存到 Amazon S3 上
- 工作流管理系統 Airflow 進行 Batch 處理,定期將被存到 S3 上的使用者存取紀錄轉成 Apache Hive SQL 表格(Tables)
- CHARTIO 透過分散式 SQL 查詢引擎 Presto 對該表格作查詢,顯示 KPI
從左到右來表示這個流程的話會如下圖:
乍看之下,你可能會想:
- 「這看起來跟資料科學完全沒相關啊!」
- 「我只要能存取關聯式資料庫(Relational Database)裡頭的表格不就好了?」
沒錯,嚴格來說這是一個資料工程(Data Engineering)的問題。但正如我們在資料科學家為何需要了解資料工程一文裡頭提到的,身為一個資料科學家,擁有資料工程的知識可以提升工作效率,點亮你的方向並加速專案前進。
事實上,了解儀表板上的 KPI 是怎麼產生的,有以下幾個優點:
- 理解工程師的痛點。能事先以他們的角度思考建立新表格所需的成本的話,他們會更願意幫你建立
- 通常新的分析會需要新的 ETL,而你可以利用跟產生 KPI 一樣的 ETL 來產生自己的資料管道(Data Pipeline)
- 確保資料品質。一旦使用的資料有瑕痴,做出來的分析也不會有意義。

最後一點尤其重要。在 SmartNews 的例子裡頭,資料科學家實際上想要分析的是「APP 使用者的存取行為」,而跟使用者行為最直接相關的其實是那些被存在網路伺服器上的 log。只是因為該資料量太大,我們必須建立資料管道做前處理,從大量原始資料中萃取、匯總出我們「可能」有興趣的資料存入關聯式資料庫供之後分析。
以這種角度來看的話,資料彷彿是從網路伺服器(上游)經過一連串的河道(資料管道)流向資料庫(下游)。這也就暗示著兩個可能的風險:
- 資料在經過河道的時候被污染,資料品質下降
- 資料在經過河道的時候被限縮,有些有價值的資料沒辦法抵達下游
一個資料科學家如果只專注在下游的資料,就可能冒著以上的風險而不自知。這就是為什麼我們需要了解企業內的資料是如何流動的。
資料的流動當然不限於 KPI 的產生,但我認為用這個問題:
- 「儀表板上的 KPI 是怎麼產生的?」
來理解一個企業的資料流是一個很好的起始點。畢竟 KPI 是公司最重視的資訊,用來建構其的資料管道也會是最完善且重要的。
結語¶
在這篇文章裏頭,我們討論了一個資料科學家在進入新公司熟悉環境的時候,除了問該裝什麼工具以外,可以問的兩個問題:
- 公司內有什麼 KPI?
- 儀表板上的 KPI 是怎麼產生的?
表面上看來是兩個再簡單不過的問題,實際上第一個問題跟業界的專業知識(Domain Knowledge)息息相關;第二個問題則牽涉到大量的資料工程專業。而透過深刻地思考這兩個問題並詢問相關人員,一個資料科學家可以更全面的理解企業並掌握大局觀,做出最有影響力的分析。
當然,除了這兩個問題以外,你還需要問很多其他重要的問題如:
- 公司的資料文化如何?
- 我在 Data Science 團隊裡頭的定位為何?
- many more ..
但作為「資料科學家 L 的奇幻旅程」系列文的第一篇文章,為了避免累贅,我把這些問題留給你們(可以留言跟我說你覺得還有什麼問題重要!)
最後的 Bonus 問題:為何是資料科學家「L」?
跟資料科學相關的最新文章直接送到家。 只要加入訂閱名單,當新文章出爐時, 你將能馬上收到通知