同樣一份資料因應不同的使用案例,可能需要使用不同的存取方式。而針對這些不同的存取方式,我們通常需要選擇最適合的資料庫來最佳化使用者體驗。
這篇文章將簡單介紹如何使用 AWS Database Migration Service (以下簡稱 AWS DMS )來快速地達到我們的目標:將 MongoDB 資料遷移到 Redshift 上。
常見的方式是對 MongoDB 裡頭的資料定期做 ETL 以後將轉換過後的資料載入 Redshift 供分析需求。理論上在做 ETL 時要依照資料倉儲的 Data Model 重新設計 Tables (例: Star Schema),但為了能在最短的時間將 MongoDB 上的資料轉到 Redshift 進行一些 Query,這篇文章將簡單介紹 AWS DMS 的運作方式,以及如何運用它來實際進行資料遷移所需要的步驟。

AWS DMS 基本介紹¶
DMS 基本上運作方式就是幫我們啟動一台 EC2 機器 (稱之為 replication instance) ,然後在上面跑 replication task(s) 。 一個 instance 上可以有多個 tasks 進行資料遷移。 instance 則分別透過 Source Endpoint / Target Endpoint 連結來源 / 目標資料庫。在後面我們會看到, endpoints 實際上就只是告訴 AWS DMS 的 replication instance 如何連結到實際的資料庫的設定罷了。在我們的例子裡頭,來源 / 目標資料庫分別對應到 MongoDB / Redshift 。
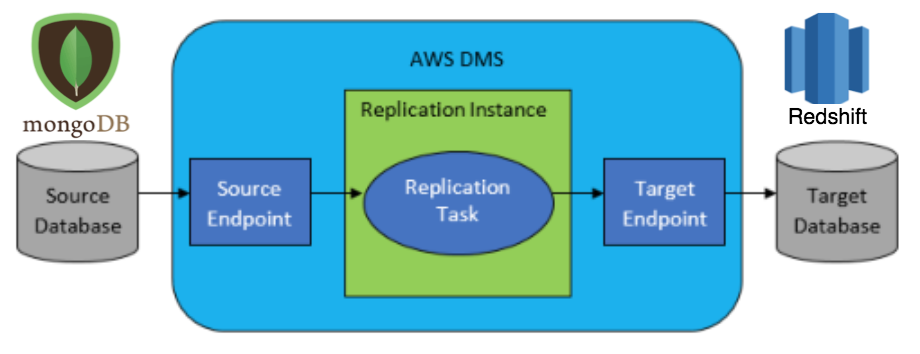
基本遷移步驟¶
在假設來源 / 目標資料庫已經在運作的情況下,如同 AWS DMS 的 Get started, 一般會進行以下步驟來遷移資料:
- 建立 replication instance
- 確保 replication instance 能連結到來源 / 目標資料庫
- 定義 replication task
- Debugging:確保一切運作正常
以下針對每個步驟,我會紀錄一些需要注意的地方。
建立 replication instance¶
點擊 AWS DMS 介面的 Get started 選項會請我們建立新的 instance:
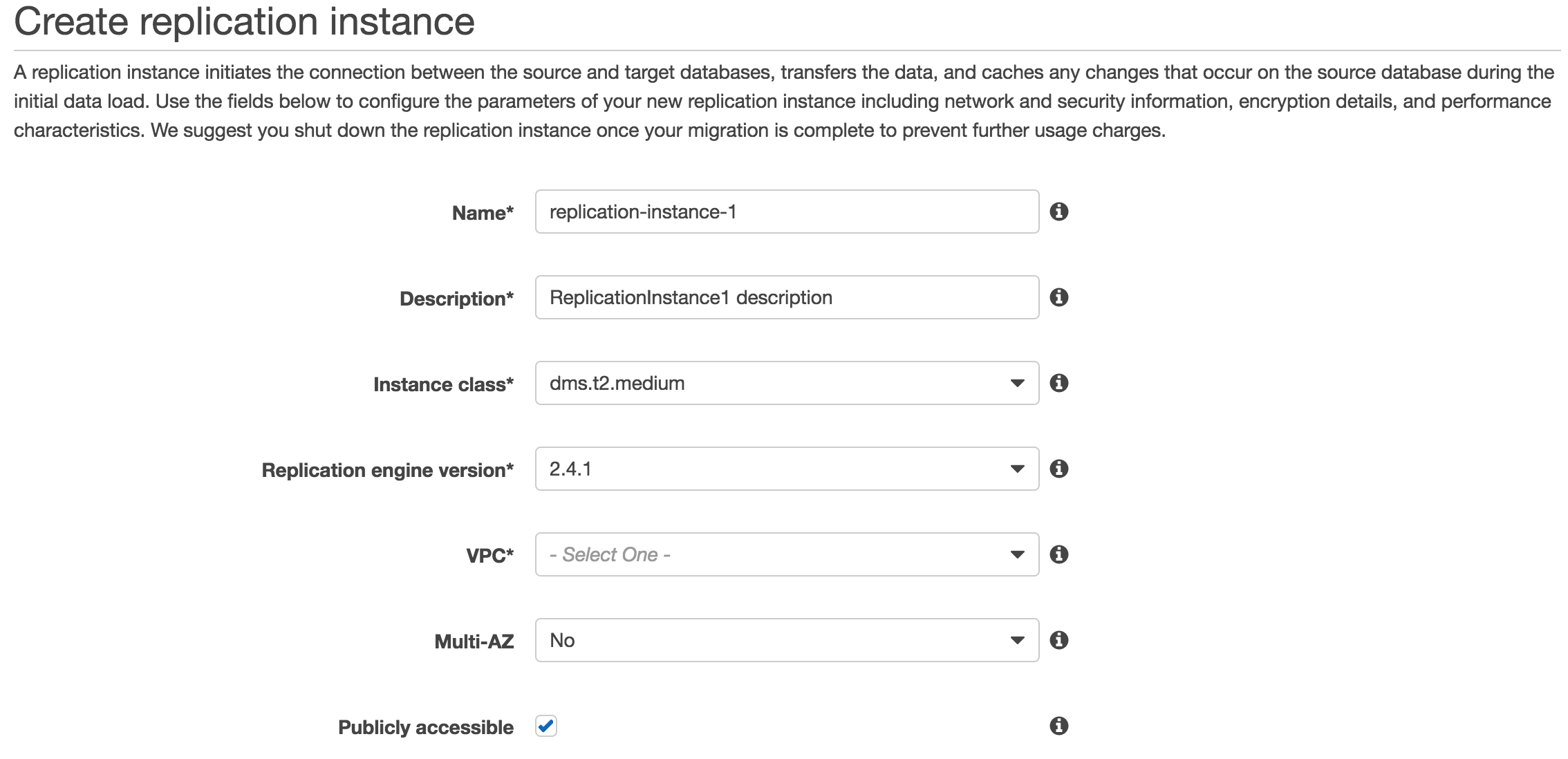
這步驟基本上沒什麼問題, replication task 會佔用大量的 CPU 以及記憶體資源,理想上是依據需求選擇 Instance class ,不過第一次測試功能的話用預設的 t2.medium 即可。這邊值得注意的是 VPC 以及下面進階選項的 VPC Security Group(s) 設定。
如果來源 / 目標資料庫都可供公開存取的話,基本上不需要 VPC 。但一般來說我們都會有安全考量,也就是要求所有在 AWS 上的資源都要套用安全設定,則最簡單的架構是將來源資料庫、目標資料庫以及 Replication Instance 都放入同一個 VPC ,並利用 security group 設定來允許該 Instance 存取兩個資料庫。概念上此 VPC 的架構會如下 ( sg 為 Security Group 之縮寫 ):
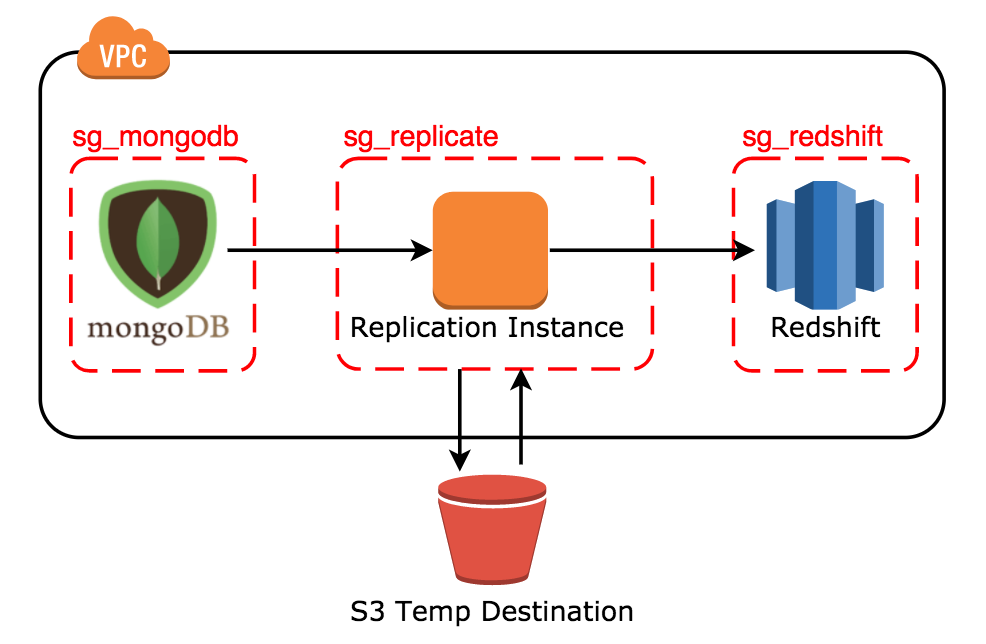
以上圖為例, Security Group sg_mongodb 以及 sg_redshift 的 Inbound Rule 要允許 sg_replicate 存取。而允許存取的 Port 則依照資料庫實際使用的 Port 設定即可 (例: MongoDB 慣用 27017; Redshift 則是 5439)。最後別忘了在建立 replication instance 的進階設定的 VPC Security Group(s) 選擇 sg_replicate。
確保 replication instance 能連結到來源 / 目標資料庫¶
上一步驟設定好以後, AWS DMS 會馬上幫我們建立一個新的 replication instance。在等待的同時我們可以開始設定資料庫的 endpoints。
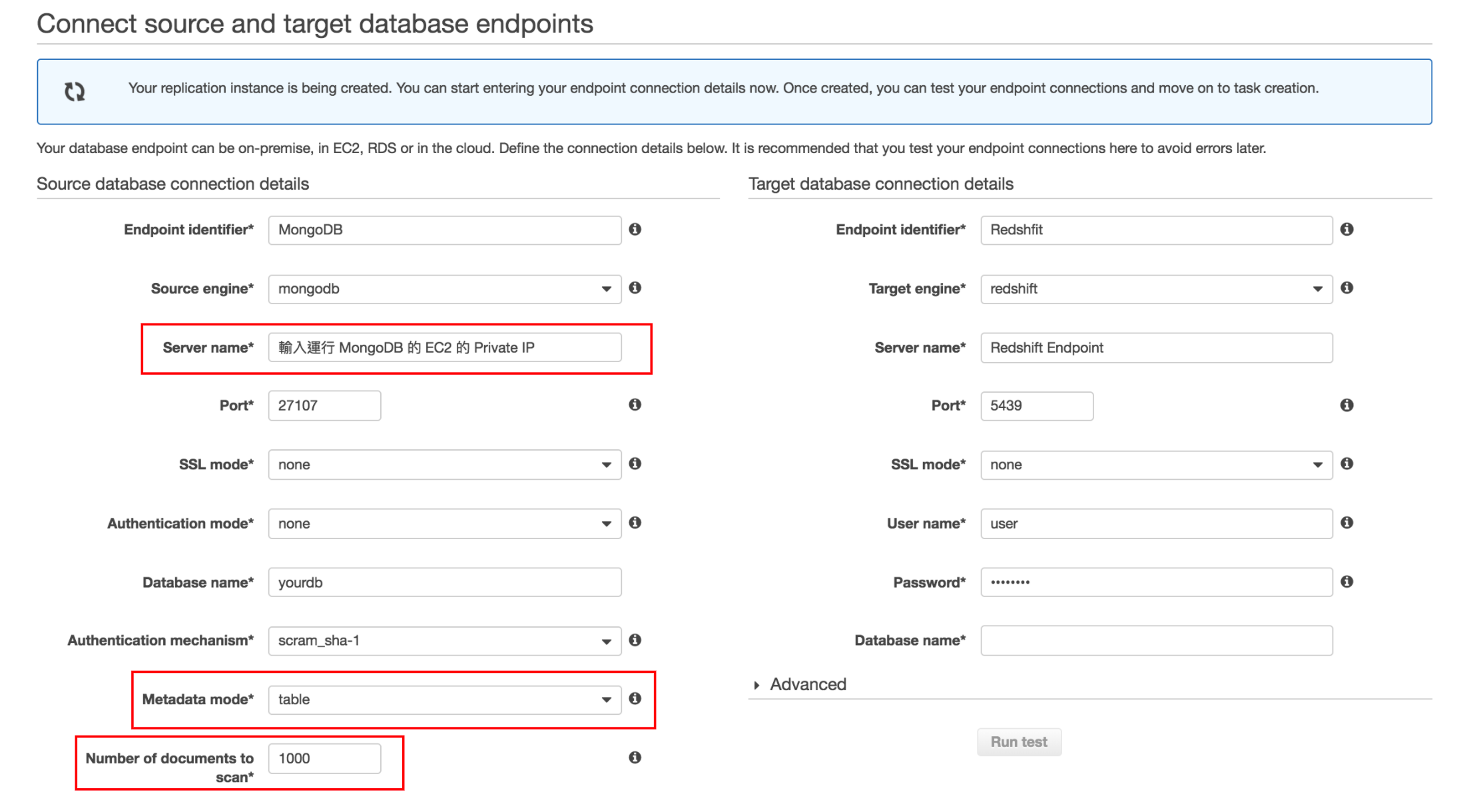
這步驟基本上依照資料庫的不同,需要的輸入的項目可能不一樣。不過值得一提的是,在建立 replication instance 的時候我們已經讓來源 / 目標資料庫以及 replication instance 都待在同個 VPC 裡頭。假設我們的 MongoDB 是運行在該 VPC 裡頭的某個 EC2 instance 之上,要允許在同個 VPC 的 replication instance 存取該 EC2 instance,我們要在 Server name 選項輸入運行 MongoDB 的 EC2 的 Private IP (上圖第一個紅框)。
MongoDB as Source Database¶
當 MongoDB 為來源資料庫時有一些值得注意的事情可以參考官方文件。以下會說明一些值得特別注意的地方。
Metadata mode¶
Metadata mode 預設為 document(上圖第二個紅框),也就是把 MongoDB 裡頭的 json-formated 文件放到 Redshift 裡頭對應 Table 的一個 _doc 欄位。假設 MongoDB 裡有一個 users collection ,裡頭存了以下文件:
{
"user": "leemeng",
"favorite": "chocolate",
"a": {
"b": "For fun!"
},
"unnecessary_field": "Don't include me!"
}
將會被以下的格式載入 Redshift:
_doc |
---------------------------
{"user": "leemeng", "fav ..而這通常不是我們要的。將 metadate mode 設定為 table 模式能讓 AWS DMS 把文件裡頭的欄位扁平化後放入對應的欄位(column):
user | favorite | a.b | unnecessary_field
-------------------------------------------------
leemeng | chocolate | For fun!| Don't include me!
注意到這邊有一個我們不需要遷移到 Redshift 的 unnecessary_field 。在後面的 Transformation Rules 我們會了解怎麼辦該欄位去除。
Numbers of documents to scan¶
而 Numbers of documents to scan 選項則讓我們決定要讓 AWS DMS 拿多少文件來決定要建立哪些欄位。如果要遷移的 MongoDB collection 的文件 schema 很常被更動(常有新鍵值)的話,建議可以讓 AWS DMS 掃描多一點文件來建立足夠的欄位。
Redshift as Target Database¶
如果按照 AWS DMS 的 Get started 一步一步走的話基本上沒有問題。要注意的是 Redshift 要有允許 DMS 存取的 AMI Rule,否則會出錯。
定義 replication task¶
在確定 replication instance 可以連線到兩個資料庫後,可以開始建立我們的 replication task:
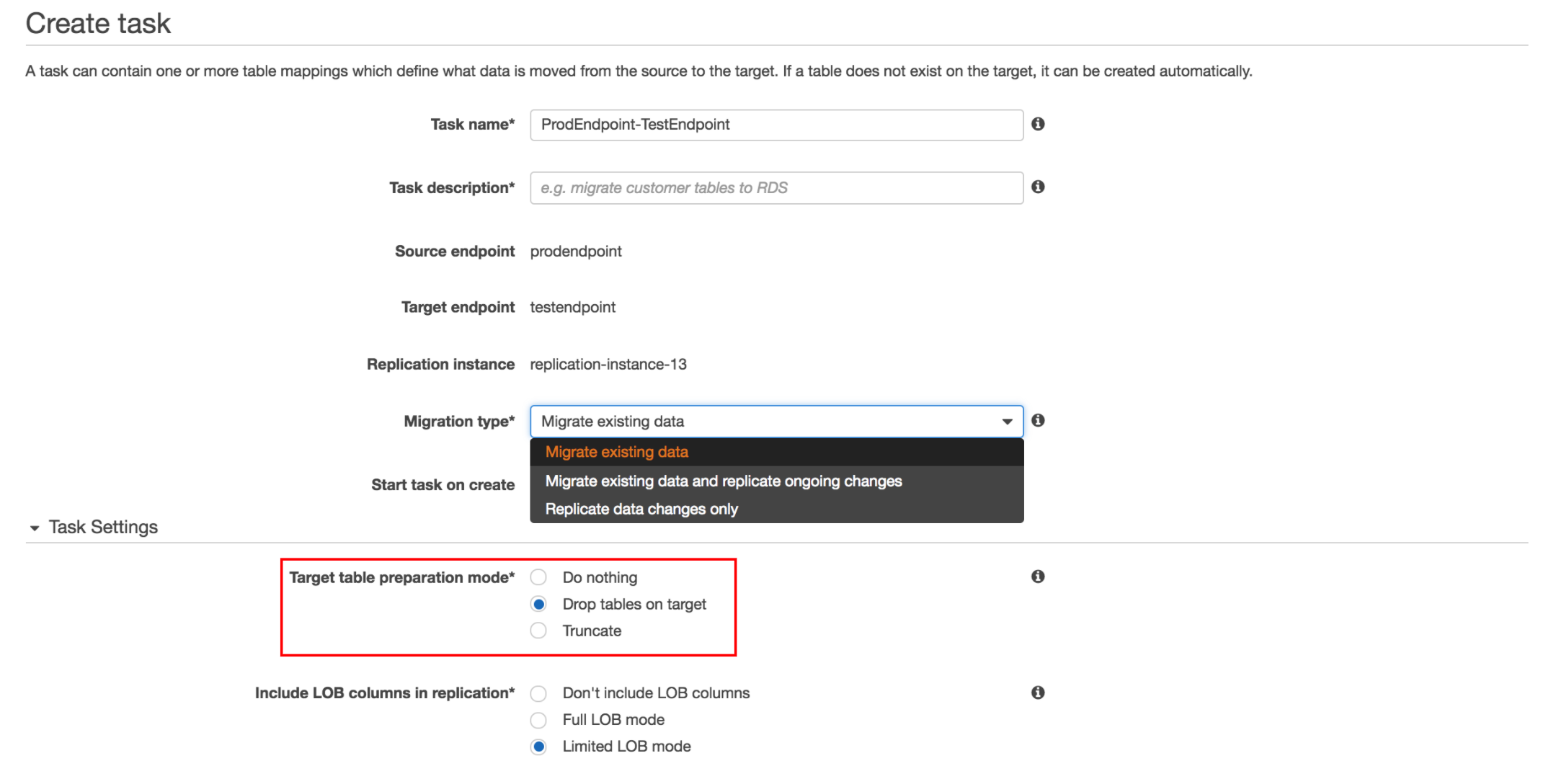
這邊我們可以看到有三種資料遷移方式 (圖中的 Migration type):
- 遷移目前 MongoDB 的資料
- 同上,但在遷移後之後繼續同步 MongoDB & Redshift (前提是 MongoDB 要以 Replica Set 模式執行)
- 只把 Task 啟動後 MongoDB 的資料變動遷移到 Redshift
這邊選擇自己的想要的遷移方式即可。接著我們要告訴 AWS DMS 想要進行遷移的 MongoDB Collections 以及在想要做的簡單轉換。兩者分別透過 Selection Rules 還有 Transformation Rules 定義。
Selection Rules¶
Selection Rules 的用途是告訴 AWS DMS 該遷移以及不要遷移的 (MongoDB) collections 。我們可以定義一個 general rule 讓一個 task 處理某個 db 的所有 collections ;也能讓一個 task 只負責一個 collection 的遷移。後者的設定比較花時間但是彈性比較高,可以依照不同 collection 特性決定遷移的方式。
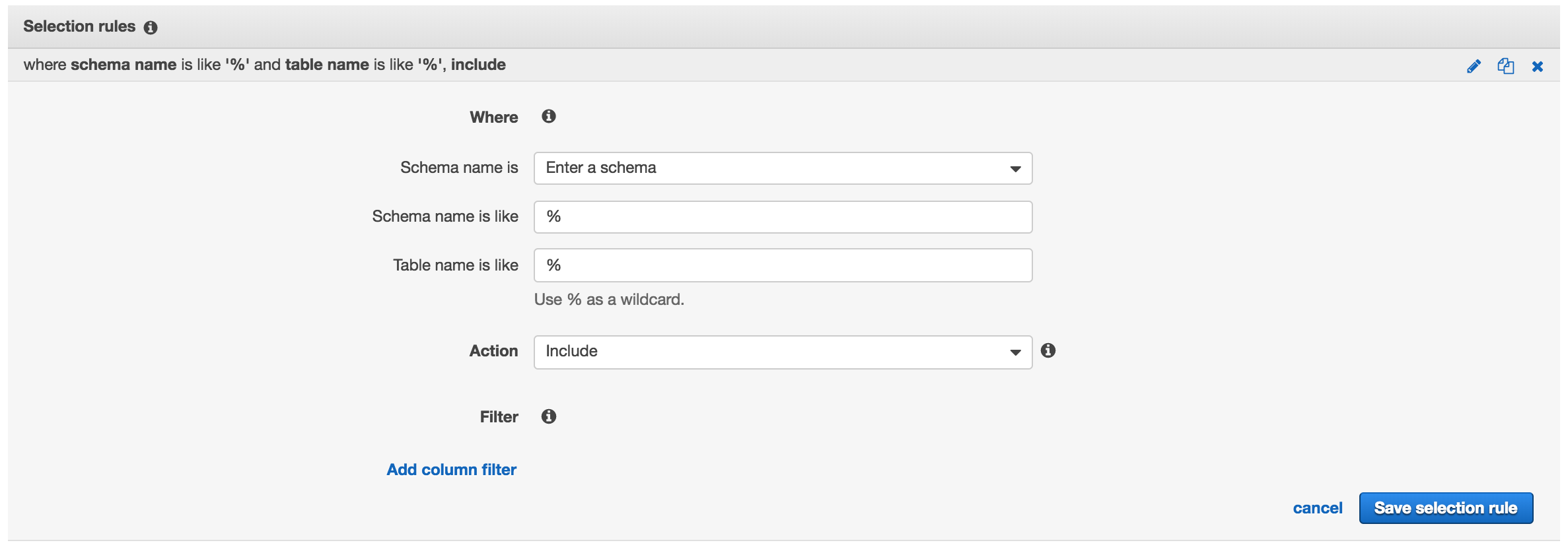
下圖是定義一個 rule 告訴 AWS DMS 遷移所有在 MongoDB 的 Collections。另外如果想要排除哪個 collection 的話就新增一個 rule 並在 Action 選擇 Exclude。基本上想要加幾個 Selection Rules 都可以。而 Exclude Rules 的效果是在所有 Include Rules 後套用。
Transformation Rules¶
這邊所謂的轉換並不是對欄位的實際值 (value) 進行轉換,而是針對 Table / Column 層級做
- 排除(不遷移該 Table / Column)
- 幫 Table / Column 更名、大小寫轉換或是名稱加上 prefix / postfix
這種操作。下圖是將 users collection 裡頭不需要遷移的鍵值 uncessary_field 從 Redshift 排除的 rules:
透過這個 Transformation rule,我們上面 users collection 的範例文件:
{
"user": "leemeng",
"favorite": "chocolate",
"a": {
"b": "For fun!"
},
"unnecessary_field": "Don't include me!"
}
就會被轉成:
user | favorite | a.b
------------------------------
leemeng | chocolate | For fun!
注意 uncessary_field 不會被存到 Redshift 裡頭。
Debugging¶
當建立並執行一個新的 replication task 後,我們可以從 Load State 看到每個 Table 載入的狀況。 Load State 有幾種可能的值:
- Before Loading
- Full Load
- Table completed
- Table error
當出現 Table error 時,我們可以先看 log 瞭解情況:
2018-03-28T01:23:30 [TARGET_LOAD ]E: RetCode: SQL_ERROR SqlState: XX000 NativeError: 30 Message: [Amazon][Amazon Redshift] (30) Error occurred while trying to execute a query: [SQLState XX000] ERROR: Load into table 'users' failed. Check 'stl_load_errors' system table for details. [1022502] (ar_odbc_stmt.c:4406)
依照不同的錯誤、不同的目標資料庫,實際的 log 內容會有所不同。以我們目標資料庫 = Redshift 的情況下,上面的 log 告訴我們 replication task 在載入 users Table 時出錯,詳情可以參考 Redshift 的 stl_load_error Table (官方文件):
SELECT *
FROM pg_catalog.stl_load_errors
ORDER BY starttime DESC
LIMIT 1;

就這個錯誤例子來看, err_reason 的內容告訴我們有個 memo 欄位 ( colname ) 的值太長導致沒辦法載入 Redshift。這時候可以把正在運行的 replication task 暫停,用前面提到的 Transformation Rules 來去除該欄位。而基本上其他錯誤也能用類似的方式解決。
到這邊為止大致上應該可以順利把 MongoDB 的資料載入 Redshift 了。之後想到什麼再補充。
跟資料科學相關的最新文章直接送到家。 只要加入訂閱名單,當新文章出爐時, 你將能馬上收到通知