所謂的資料湖 (data lake) 指的是一企業裡頭所有形式的資料的集合。這些資料包含原始資料 (raw data),以及經過轉換的衍生資料 (derived data)。
資料湖的核心概念是將所有可用的資料全部整合在一個邏輯上相近的地方以供企業自由結合並做各式各樣的運用。資料湖可以用很多方式建立,這裏我們主要介紹如何利用 Amazon Kinesis 將串流資料 (streaming data) 載入資料湖。
概觀¶
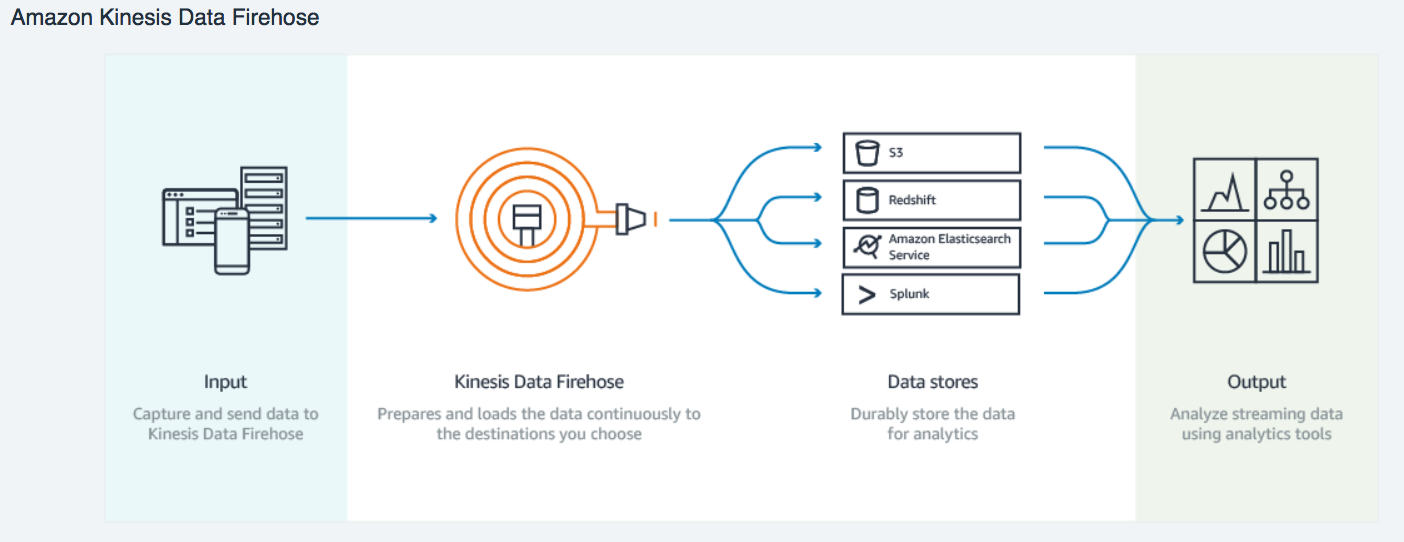
資料湖概念上可以說是企業的所有資料的最終目的地。現在假設我們打算以 Amazon S3 中作為我們的資料湖,問題就變成:要如何將串流資料穩定地傳到 S3。這部分我們將透過 Amazon Kinesis 來達成。 Kinesis 本質上是跟 Apache Kafka 類似的 message broker,將訊息依照 message producers 產生的順序傳遞給 message consumers。實際上資料的流動會如下圖所示:
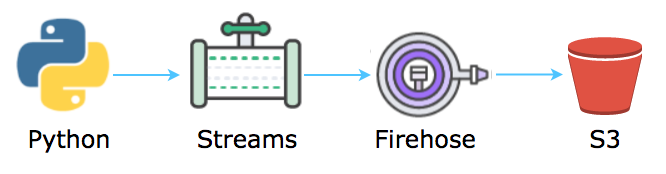
上圖有幾點值得說明:
- 作為一個簡易的 demo,這邊我們的串流資料產生者 (streaming data producer) 是一個簡易 python script
- Streams 指的是 Amazon Kinesis Data Streams。在 Kinesis 架構裡頭,一個 data stream 通常代表一個主題 (topic), 跟這個主題相關的 producers 會把資料傳入該 stream 以讓該主題的 consumers 之後能接受訊息。
- Firehose 指的是 Amazon Kinesis Data Firehose,是專門把接受到的串流資料寫入 AWS 上的資料存放區(如 S3、Redshift、ElasticSearch)以供後續分析的服務。
建構流程¶
要完成上述的資料傳輸 pipeline,我們會 follow 以下步驟:
在每個步驟裡頭會稍微澄清一些概念。
建立一個 Kinesis data stream¶
現在假設有一個名為 naive-app 的應用程式,我們想要把使用者在上面做的操作紀錄下來。這時候我們可以建立一個新的 Kinesis Data Stream 來接受 app 的 streaming data。這邊指的 streaming data 是使用者存取應用程式時產生的 access log。
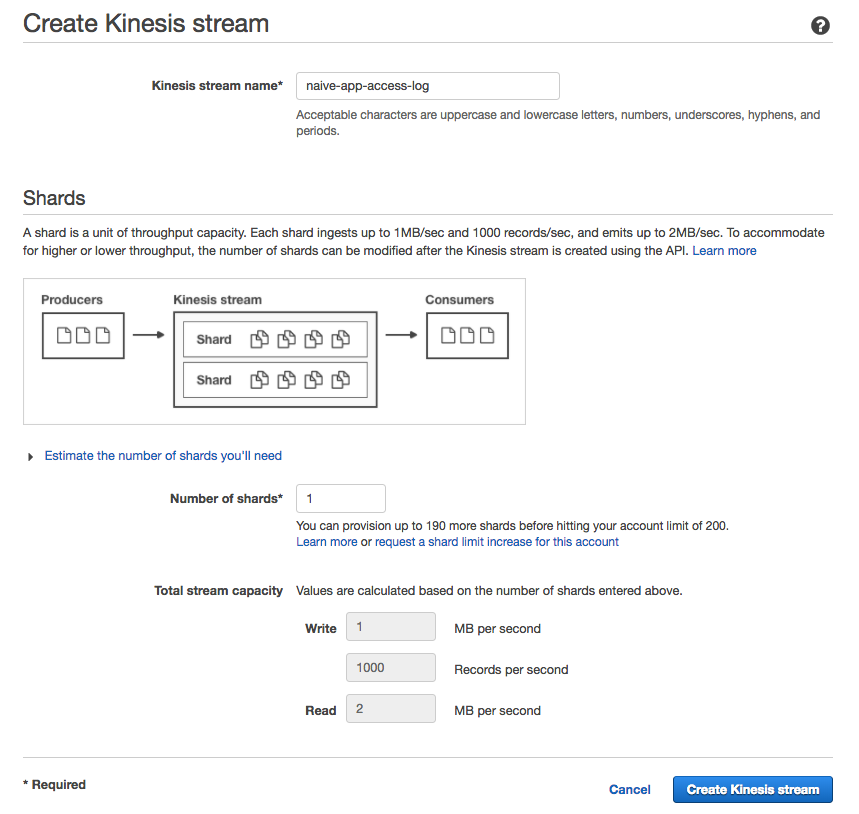
Scalability¶
這邊最重要的是 Number of shards 的設定。Kinesis 將接收到的資料以 log 的方式儲存在硬碟上,而為了提高 scalability,Kinesis 利用 Partitioning 的概念將 log 切割成多個部分並分配到不同的 shards 上,再將這些 shards 分別存在不同機器上面以提高 read/write capacity。因此我們可以理解一個 Kinesis Stream (Topic) 的資料吞吐量 (throughput) 直接受到 shard 的數目影響: shard 數目越多,同時能處理 read/write 的機器越多,資料吞吐量越高。
How to scale¶
理想上是一開始就掌握該 Stream/Topic 需要的資料吞吐量,進而決定最佳的 Number of shards ,但有時候事與願違。事後想要改變 shard 數目時需要透過 AWS Streams API 做 Resharding。Resharding 實際上就是在改變 shard 數目:增加 shard 會讓已存在的 shard 再度被切割;減少 shard 則會合併已存在的 shard。
在這邊我們就只直接使用一個 shard for demo。
Availability¶
另外值得一提的是 Kinesis 為了避免資料損失,會在三個不同的 availability zones 進行資料的 replication。因為這個額外的 overhead 可能使得在同樣設定下, Kinesis 比 Kafka 慢 的情況。因為是 log-based message broker,資料會被暫時存在硬碟上,預設保留 24 小時,而最多可以付費提升到維持 7 天以用來 replay data。
建立一個 Firehose delivery stream¶
有了接受 naive-app 串流資料的 Kinesis stream 以後,我們要建立一個 Firehose delivery stream 來接收 Kinesis stream 的資料。
Firehouse delivery stream 簡單來說是一個將串流資料存到 AWS 資料存放區的服務(如 S3、Redshift、ElasticSearch)。因此除了 Kinesis stream 的串流資料以外,當然也可以接其他的串流資料:
- CloudWatch 的 log
- AWS IoT
- 使用者自定義的串流資料
在這篇裡頭我們的串流資料是 Kinesis stream,因此 Source 選擇 Kinesis stream 並填入我們剛剛建立的 stream 名稱: naive-app-access-log。

值得一提的是 Firehose delivery stream 會 auto-scale,並不像 Kinesis stream 要手動調整 shard 數目。不過當然傳越多花越多。
如上張圖所示,實際上 Firehose 還允許我們在 delivery stream 接受到串流資料以後把原始資料傳到指定的 Lambda function 做進一步的轉換。 但因為我們想要資料湖儲存原始的串流資料,這邊我們省略這步驟。
Configuration¶
實際上 Firehose 不會一接收到資料就進行資料轉移。我們可以設定 Buffer size 以及 Buffer interval 讓 Firehose 在達到其中一個條件的時候把接收到的訊息統整起來一次做資料的轉移 (batch processing)。這邊為了能讓 Firehose 盡快把收到的資料轉移到 S3,設定 Buffer interval 為 60 秒。

選擇 delivery stream 目的地¶
在設定好 Firehose delivery stream 的串流資料來源(e.g., Kinesis stream)以及基本設定以後,我們要決定串流資料的目的地。這邊基本上很直覺, Destination 選擇 Amazon S3 以及想要放資料的 bucket 即可。
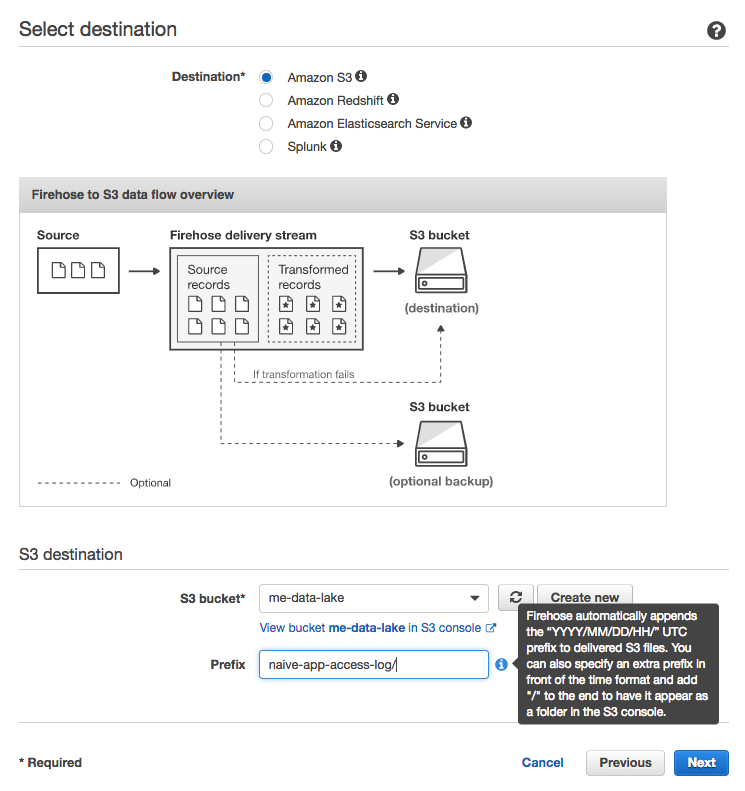
比較需要注意的是我們可以指定此 Firehose delivery stream 在放資料進入 bucket 時要為檔案加什麼前綴。
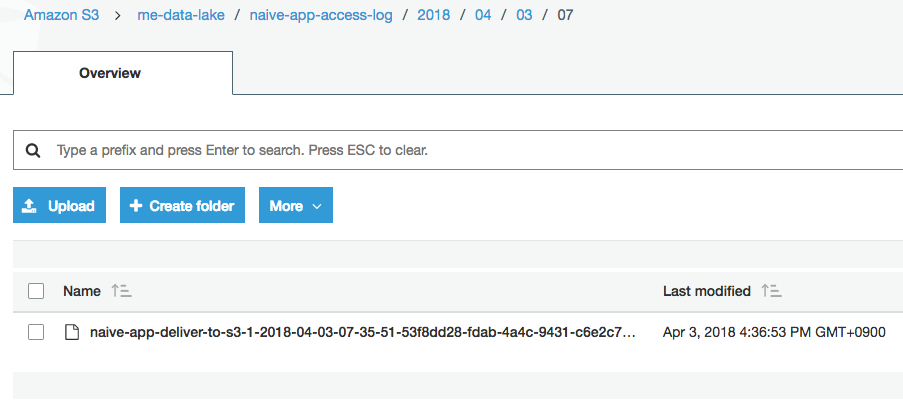
假設未來其他的串流資料我們也想要統一放在 me-data-lake 這個 bucket 裡頭。為了方便管理,我們可以為每個 delivery stream 設定一個識別用的 Prefix。以 naive-app 來說,我們指定 Prefix 為 naive-app-access-log/ 。加上 Firehose 預設的 YYYY/MM/DD/HH/ ,該 stream 的每個檔案的路徑就會變成如下圖的 naive-app-access-log/YYYY/MM/DD/HH/file_name。
用 Python 傳串流資料¶
確保 Kinesis stream -> Firehose delivery stream -> S3 的資料流設定以後,我們可以寫一個簡單的 Python script 實際傳資料進 Kinesis stream 做測試。但首先先讓我們使用 AWS SDK for Python 實作一個寄訊息給 Kinesis stream 的 function write_to_stream :
import boto3
import json
def write_to_stream(event_id, event, region_name, stream_name):
"""Write streaming event to specified Kinesis Stream within specified region.
Parameters
----------
event_id: str
The unique identifer for the event which will be needed in partitioning.
event: dict
The actual payload including all the details of the event.
region_name: str
AWS region identifier, e.g., "ap-northeast-1".
stream_name: str
Kinesis Stream name to write.
Returns
-------
res: Response returned by `put_record` func defined in boto3.client('kinesis')
"""
client = boto3.client('kinesis', region_name=region_name)
res = client.put_record(
StreamName=stream_name,
Data=json.dumps(event) + '\n',
PartitionKey=event_id
)
return res
write_to_stream 基本上是把一個 Python dict event 利用 json.dumps 轉成字串後傳到指定的 region 的 Kinesis stream 裡的函式。(完整的 Gist )
這邊值得注意的是 Data=json.dumps(event) + '\n' 裡頭的 '\n' 。如果之後想要利用 AWS Glue 或者 Athena 來進一步分析此串流資料的話,推薦在代表一個 event 的字串後面加上換行符號以維持「一行一事件」的資料形式,方便 schema 的自動產生。
範例日誌檔案內容會像是這樣:
{"event_id": "56262", "timestamp": 1522740951, "event_type": "write_post"}
{"event_id": "35672", "timestamp": 1522740956 ...
另外值得一提的是因為 Kinesis 背後是使用 Hash partitioning 來分配資料到 shard,基本上 PartitionKey=event_id 裡頭的 event_id 只要每個訊息都是獨一無二的,就能保證資料能「平均地」分配到各個 shard 上。
有了此函式以後,我們可以實際傳一些訊息進 Kinesis stream:
while True:
event = {
"event_id": str(random.randint(1, 100000)),
"event_type": random.choice(['read_post', 'write_post', 'make_comments']),
"timestamp": calendar.timegm(datetime.utcnow().timetuple())
}
# send to Kinesis Stream
event_id = event['event_id']
write_to_stream(event_id, event, REGION_NAME, KINESIS_STREAM_NAME)
time.sleep(5)
假設我們的 naive-app 可以讓使用者讀文章、寫文章以及寫評論,則上面的程式碼是模擬使用者使用 naive-app 時產生的事件,並將該事件的內容傳到 Kinesis stream naive-app-access-log。60 秒內幾筆產生的事件如下:
{'event_id': '56262', 'event_type': 'write_post', 'timestamp': 1522740951}
{'event_id': '35672', 'event_type': 'make_comments', 'timestamp': 1522740956}
{'event_id': '71613', 'event_type': 'read_post', 'timestamp': 1522740962}
{'event_id': '48160', 'event_type': 'make_comments', 'timestamp': 1522740967}
{'event_id': '96093', 'event_type': 'write_post', 'timestamp': 1522740972}
確認 S3 上的資料¶
注意因為上面的 5 個事件在 $5 * 5 = 25$ 秒內就產生了。且因為我們前面設定 Firehose delivery stream 的 Buffer interval 為 60 秒,Firehose 會把以上的事件的訊息全部串接起來,放到一個檔案裡頭,而不是分成五個檔案:
而實際檔案的內容如下:
{"event_id": "56262", "timestamp": 1522740951, "event_type": "write_post"}
{"event_id": "35672", "timestamp": 1522740956 ...
結語¶
到這邊為止成功把(偽)串流資料透過 Kinesis 存到 S3 了!為了方便之後的應用,輸出的檔案的內容格式或許還可以再改進,但資料湖的其中一個想法是 Command Query Responsibility Segregation (CQRS),也就是在存放資料的時候就只專心丟資料,不去在意之後資料會被以什麼方式、schema 使用,可以保證之後實際應用資料時有最大的彈性。
另外在確保資料好好地儲存在資料湖以後,我們通常會實際針對串流資料再進行一些處理 / 分析像是:
- 放到 Elasticsearch 並用 Kibana 做 Visualization
- 觸發 Lambda function 做進一步處理
- 使用 Athena 做 ad-hoc 分析
- ...
但這邊時間有限,之後有機會再來記錄資料湖之後的分析筆記。
References¶
跟資料科學相關的最新文章直接送到家。 只要加入訂閱名單,當新文章出爐時, 你將能馬上收到通知