透過描述資料科學家的一天日常,本文將簡單介紹資料工程(Data Engineering)的概念、其如何跟資料科學相關。以及最重要的,作為一個資料科學家(Data Scientist)應該如何學習並善用這些知識來創造最大價值。
身為一個資料科學家,擁有資料工程的知識可以提升工作效率,點亮你的方向並加速專案前進。
資料科學家的一天¶
一說到資料科學,在你腦海中浮現的幾個關鍵字可能是:
- 資料分析
- 資料視覺化
- A.I. / 機器學習
等為人津津樂道的面向。
的確,這些都在資料科學的範疇裡頭,但實際上佔用多數資料科學家大部分時間,卻常被忽略的部分是資料準備:
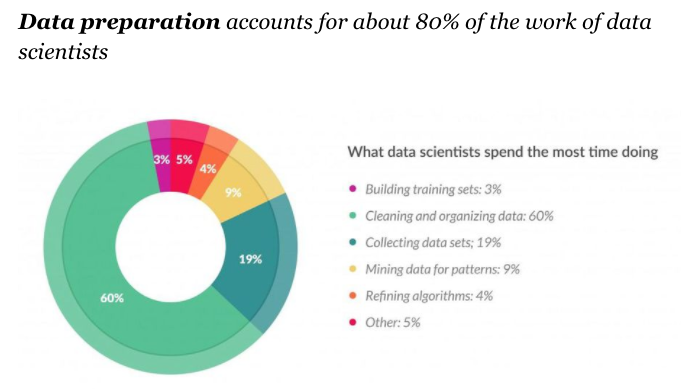
資料準備¶
說到資料準備,你可能會聯想到我們在前一篇淺談資料視覺化以及 ggplot2 實踐裡頭,使用 R 語言做的簡單資料清理:
# 將 CSV 檔案載入成資料框架(dataframe)
ramen_all <- read.csv("datasets//ramen-ratings.csv")
# 將「星星數」轉成定量資料
ramen_all$Stars <- as.numeric(ramen_all$Stars)
# Subset 資料
ramen <- ramen_all %>%
filter(Country %in% count(ramen_all, Country, sort = TRUE)[1:6, 1, drop=TRUE]) %>%
filter(Style %in% count(ramen_all, Style, sort = TRUE)[1:4, 1 , drop=TRUE])
在做分析之前,我們做了以下的步驟來準備資料:
- 讀進
ramen-ratings.csv - 轉變某些欄位的資料型態
- 依照一些條件取出想要分析的資料
雖然資料量不大,你仍然可以試著想像我們實際上建立了一個 ETL 工作:
- 將資料從來源(硬碟)擷取出來(Extract)
- 做了一些轉換(Transform)
- 載入(Load)目的地(記憶體)
假設我們把一般的資料分析專案分為以下兩階段:
- 資料準備:將資料轉換成適合分析的格式
- 資料分析:探索資料、建構預測模型
上面的 ETL 就屬於第一個步驟。又因為此資料集大概只包含 5,000 筆資料,步驟 1 所花的時間跟步驟 2 的所需時間相比,可以說微乎其微,它不會是你做資料科學的一個 bottleneck。
但如果你要處理的資料量是這個的 1,000 倍大呢?你還能馬上進入分析階段嗎?
第一挑戰:資料量大增¶
實際上一個資料科學家每天需要分析的資料量可能要乘上幾個級數。現在假設你從銷售部門拿到一個包含數百萬筆銷售紀錄,大小為 60G 的 CSV 檔案,我想你應該不會想要直接打開它,即使它在某些人眼裡還不夠資格稱為大數據 (´;ω;`)
你殫精竭慮,最後決定去問公司內一位資深的資料工程師(Data Engineer)該怎麼解決這問題。
該仁兄施了點你不曉得的魔法,過了幾分鐘從 Slack 丟來個神秘的 URL。連到上面,你發現熟悉的 Jupyter Nook 介面,而且 CSV 還幫你載好了 Σ(゚д゚;
你開心地在資料工程師幫你搞定的機器上做出分析,最後在大家面前做口頭報告。大家針對報告的反應不錯,但坐在底下的廣告部門的人這時候提問了:
「可以把這些銷售紀錄跟廣告點擊的串流日誌(log)合在一起分析嗎?這樣我們會有更多有趣的結果!」
你的頭又痛了起來。
第二挑戰:非結構化資料¶
除了資料量級的差異,一個資料科學家在企業裡頭會遇到的另外一個挑戰是非結構化資料(Unstructured Data)的快速增加。你如何將各種不同格式(JSON、存取日誌、CSV 等)的資料以有效率的方式跟平常熟悉的關聯式資料庫如 PostgreSQL 裡頭的資料結合以供分析?
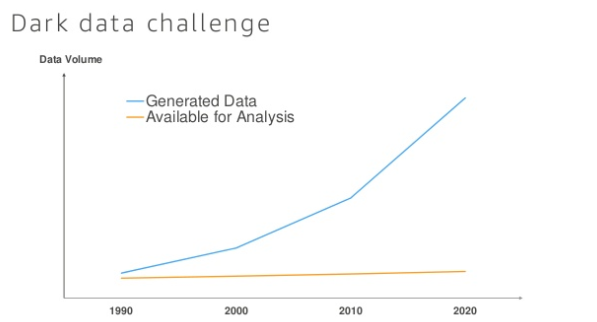
如果我們能寫一個簡單的 SQL 查詢,把銷售資料(sales)跟廣告點擊(clicks)資料依照共有的鍵值 sale_id 合起來該有多好:
SELECT *
FROM sales AS s
INNER JOIN clicks AS c
ON s.sale_id = c.sale_id你想著想著就到下班時間了。
「算了,還是先回家睡個覺,明天再厚著臉皮問資料工程師吧!反正之前他也幫我在資料倉儲(Data Warehouse)加了新的表格。」
資料為本¶
從上面這個資料科學家的一天,我們得到什麼啟示?
資料(的基礎設施)為資料科學之基礎 - 巧婦難為無米之炊
老實說這個例子裡頭的資料科學家已經非常幸運:公司裡有資料工程師能幫他把大量、複雜格式的資料做 ETL 並以資料倉儲中的一個新表格(Table)的方式呈現轉換過後的資料以供他使用。硬要說稍微不方便的地方,頂多就是該資料科學家得等資料工程師搞定好資料就是了。
然而因為資料工程師是一個很新的職位,多數的企業現在並沒有這樣的人存在。大多數的資料科學家只能自己下海,想辦法生出可以用的資料。實際上,Monica Rogati 在 The AI Hierarchy of Needs 提到,一些常見的資料科學專案像是
- 建置 AI
- 建置簡單的機器學習模型
- 資料分析
都得建立在「有完善且可靠的資料」這個基礎之下:

以金字塔最下三層為例,要讓資料科學的專案順利進行,你最少要(由下而上):
- 持續搜集(COLLECT)原始資料
- 將該資料轉移(MOVE / STORE)到適合分析的地方如資料倉儲、資料湖
- 轉換(TRANSFORM)被轉移的資料,進行前處理以方便分析
我認爲資料工程的重頭戲在上面的 2, 3 點:將資料以「轉換好」的形式「送」到可供分析的地方。(當然也可以先送再轉換,或者不轉換,詳見下面章節的資料湖)
身為資料科學家,如果你夠幸運,公司內部有專業的資料工程師幫你把上面這件事情做好,恭喜!你可以多專注在分析以及建置預測模型上面; 但假設公司裡頭只有資料科學家,而企業又想要處理大數據的話,抱歉,你得擔起這個攤子,想辦法把資料的基本設施搞定:
每個成功的資料科學家背後都有個偉大的資料工程師。或者該資料科學家就是那個資料工程師。
身為資料科學家,如果我們也能了解資料工程相關的知識的話,不就能更快地、更有效率地進行資料分析了嗎?
這個想法即是所謂的從鄰近專業(Adjacent Disciplines)學習:透過學習跟本業息息相關的資料工程,資料科學家可以加速資料科學的專案進行,並為個人以及團隊創造更大價值。想閱讀更多,可以看看在 Airbnb 工作的資料科學家怎麼說。
接著讓我們稍微聊聊到底什麼是資料工程以及一些相關例子。
資料管道¶
依照前面的論述,資料工程最主要的目的就是建構資料科學的基本設施(Infrastructure)。而這些基礎設施裡頭一個很重要的部分是資料管道(Data Pipeline)的建置:將資料從來源 Source 導向目的地 Target 以供之後的利用。有必要的話,對資料進行一些轉換。
一些簡單的例子像是我們之前部落格提到的:
從上面的例子也可以看到,實際上資料管道是一個涵蓋範圍很廣的詞彙,包含
- 即時的串流資料處理
- Batch 處理(如:每 12 小時作一次)
ETL 做的事情跟資料管道類似,但偏重在 Batch 處理,這篇文章將 ETL 視為資料管道裡頭的一個子集。
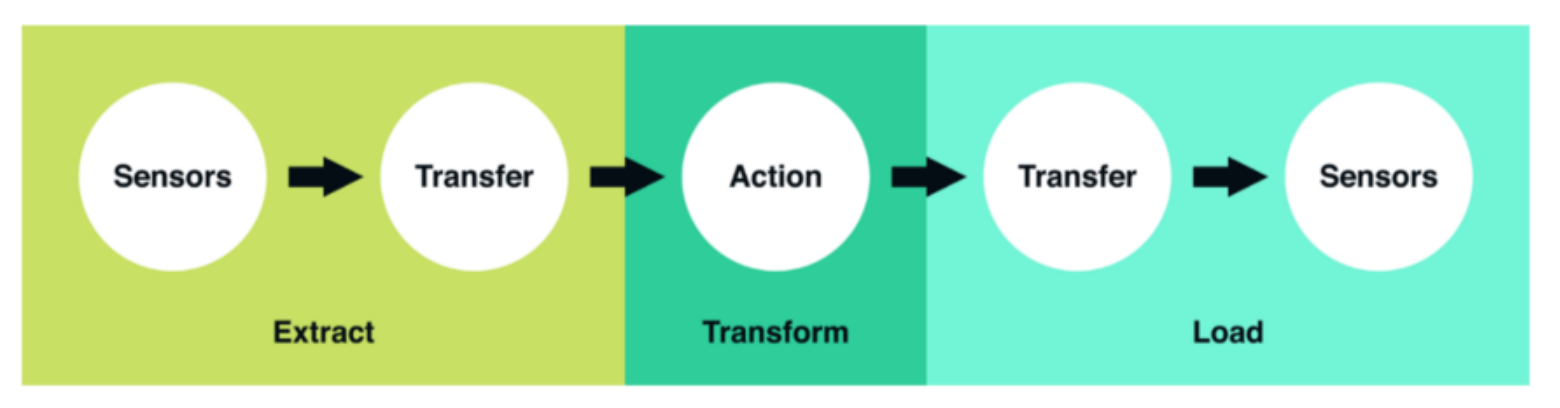
資料的來源或目的地可以是:
- 分散式檔案儲存系統(如 HDFS、AWS S3)
- 一般的資料庫 / 資料倉儲(如 AWS Redshift)
- ...
ETL 最重要的是轉換步驟,一些常見的轉換包含:
- 改變欄位名稱
- 去除空值(Missing Value)
- 套用商業邏輯,事先做資料整合(Aggregate)
- 轉變資料格式(例:從 JSON 到適合資料倉儲的格式如 Parquet)

那經過資料管道處理後的資料要怎麼存取/分析?依照存取方式的不同,資料管道的架構方式也會有所不同。
而存取資料的方式大概可以分為兩種:
資料倉儲¶
資料倉儲的概念就跟實際的倉儲相同:你在這邊將原料(原始資料)轉化成可以消化的產品(資料庫裡頭的經過整理的一筆筆紀錄)並存起來方便之後分析。
這邊最重要的概念是:為了方便商業智慧的萃取,在將資料放入資料倉儲前,資料科學家 / 資料工程師需要花很多的心力決定資料庫綱目(Database Schema)要長什麼樣子。 也就是說資料庫的綱要(Schema)在建立資料管道的時候就已經被決定了:這種模式稱之為 Schema-on-Write。這是為了確保資料在被放進資料倉儲的時候就已經是可以分析的形式,方便資料科學家分析。
你可以想像資料工程師在建構資料管道 / ETL 的時候,得對原始資料做大量的轉換以讓資料在被寫入資料倉儲時就已經符合一開始定義的 Schema。而資料倉儲最常被拿來使用的一個資料模型(Data Model)是所謂的 Dimensional Modeling(Stars / Snowflaks Schema)。
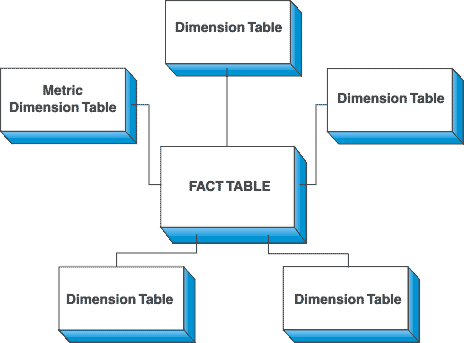
資料工程師將企業最重要的事件(如:使用者下了訂單、發了一個 Facebook 動態)放到最中間的 Fact Table,並且為了可以使用所有想像得到的維度來分析這些事件,會把事件本身的維度(Dimensions)再分別存在外圍的多個 Dimension Tables。常見的維度有:
- 時間(此事件什麼時候產生、年月份、星期幾等)
- 商品的製造商的資料、其他細節
- ...
因為看起來就像是一個星星,因此被命名為 Stars Schema。Snowflakes 則是其變形。
一些關鍵技術¶
在資料倉儲的部分,關鍵的技術與概念有:
- 了解正規化(Normalization)的好處
- 分散式 SQL 查詢引擎的原理(如 Presto)
- 分析專用的資料模型的設計原理(如 Stars / Snowflakes schema)
- 了解分散式系統背後各種 JOIN 的原理(Sort-Merge JOINs、Broadcast Hash JOINs、Paritioned Hash JOINs 等)
資料湖¶
「每天新增的資料量太多,要把所有想分析的資料都做詳細的 Schema 轉換再存入資料倉儲太花人力成本。總之先把這些資料原封不動地存到分散式檔案儲存系統上,之後利用如 AWS Glue 等服務將資料的 schema 爬出來並分析。」這就是以資料湖為核心的資料管道架構想法。一般這種存取資料的方式我們稱之為 Schema-on-Read,因為 Schema 是在實際載入原始資料的時候才被使用。
AWS Athena 就是一個 AWS 依照這樣的想法打造的服務。
舉個簡單的例子,假設我們現在想把資料科學家的一天提到的銷售資料以及廣告資料合併起來做分析,在 AWS 上我們可以實作一個這樣的資料管道:
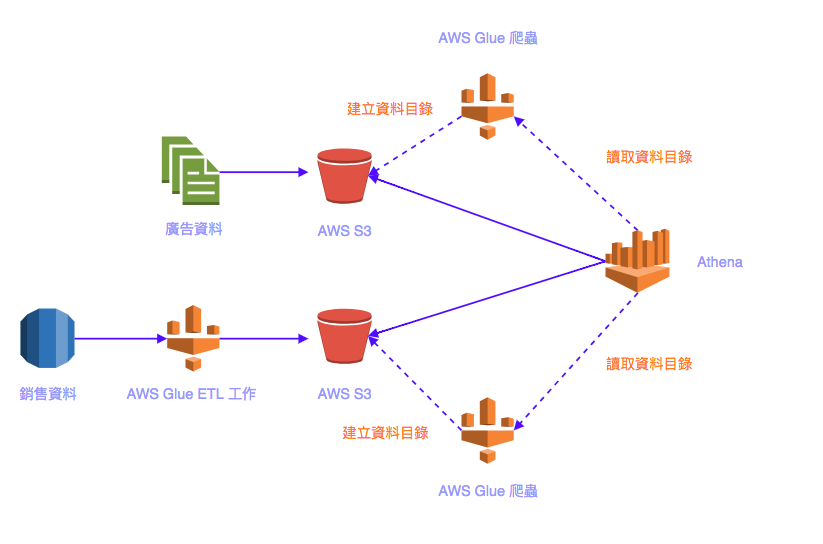
我們將存在關聯式資料庫的銷售資料透過 ETL 存到資料湖(AWS S3)裡頭以後,利用 AWS Glue 將資料的中繼資料(Meta Data)存在資料目錄(Data Catalogue)底頭。常見的中繼資料有
- 表格定義(有哪些欄位,如:
sale_id) - 各個欄位的資料型態
- 各個欄位實際在原始資料(如 CSV )裡頭的排列順序
接著我們就可以利用提到的 SQL 查詢把銷售資料跟廣告資料合併:
SELECT *
FROM sales AS s
INNER JOIN clicks AS c
ON s.sale_id = c.sale_id收到以上的 SQL 查詢,Athena 會分別把銷售資料以及廣告資料依照對應的資料目錄解析資料後合併再回傳結果給我們。
我認為今後這種以資料湖為基礎的分析架構會越來越熱門,原因如下:
- 非結構化資料量越來越大,花費人力在事前為資料倉儲建立完整的 schema 越來越不實際
- 分散式 SQL 查詢服務像是 Athena 抽象化複雜的資料格式,允許資料科學家下 SQL 查詢做 ad-hoc 分析
- 透過 Parquet / ORC 等資料格式來自動減少資料湖沒有做正規化而導致的效能損失
一些關鍵技術¶
雖然再過幾年,等到資料工程的人才增加,資料科學家或許可以完全不用介意背後的資料基礎設施的建置,但近幾年這部分可能還是要靠資料科學家自己實作。
- 資料湖的概念
- AWS Glue + AWS Athena 的運用(Bonus: Serverless 分析架構,不需管理機器)
- Hive MetaData Store
在資料湖的例子我主要都用 AWS 的服務來舉例,但你可以自由使用其他雲端服務或者 Hadoop。
如何實際應用資料工程?¶
首先你得先了解目前環境的資料基礎設施。而為了釐清這點,你可以問自己或者相關人員以下問題:
- 資料科學的金字塔,我們建到哪一層了?
- 我們過去有哪些專案是在取得、準備資料階段就陷入瓶頸?
- 我們有專業的資料工程師或相關人員在做資料倉儲或者是資料湖的準備嗎?
- 我們的資料是儲存在什麼分散式檔案儲存系統上面? HDFS 還是 S3?
- 我們是怎麼管理/監管 ETL 工作的? 要考慮用 Airflow 嗎?
- 要建構一個新的資料管道的話,要自己架 Hadoop 群集還是使用雲端服務?
- ...
在你思考過以上幾個問題以後,你就會發現為何過往有些資料科學的專案進展緩慢了。這時候與其一直在等待資料的到來,你可以把你想到的幾個問題拿去跟相關的工程師討論。相信我,從你開口跟他們討論如何解決資料基礎設施的瓶頸這點開始,他們將不再視你為「那個只想要拿到資料」的敵人,而是同伴。
假如很不幸,你們公司沒有專業的工程師,而你得自己想辦法兜出一個可以處理這些大量資料的方法,我會建議先從現存的全受管(Full-Managed)雲端服務找能解決痛點的方案。
使用現成的雲端服務來建置資料基礎有幾個好處:
- Pay-as-you-go,通常是用多少花多少
- Proof-of-concept,你可以直接開始嘗試建立最重要的商業邏輯而非架機器
- Serverless 架構,不需管理機器(如 AWS Glue + Athena)
- 導入成本降低(相較於自己架 Hadoop Cluster)
結語¶
我嘗試在這篇文章說明資料工程對資料科學家的重要,以及你可以如何開始學習資料工程。
在這個大數據時代,資料科學家的價值在於找出「大量」資料背後的潛在價值,不要反而讓「資料量太多」這邊成了你最大的限制。 從雲端服務開始,多學一點資料工程,讓你的資料科學專案前進地更快吧!
如果你有任何想法想要提出或分享,都歡迎在底下留言或者透過社群網站聯絡我 B-)
跟資料科學相關的最新文章直接送到家。 只要加入訂閱名單,當新文章出爐時, 你將能馬上收到通知